Red Hat OpenShift Virtualization 4.19 significantly improves performance and speed for I/O intensive workloads like databases. Multiple IOThreads for Red Hat OpenShift Virtualization is a new feature allowing virtual machine (VM) disk I/O to be spread among multiple worker threads on the host, which are in turn mapped to disk queues inside the VM. This allows a VM to efficiently use both the vCPU and the host CPU for multi-stream I/O, improving performance.
This article serves as a companion to my colleague Jenifer Abrams's feature introduction. To follow up, I provide performance results to assist you in tuning your VM to achieve better I/O throughput.
For testing, I used fio with Linux VMs as a synthetic I/O workload. Other efforts are under way to test with applications, and also on Microsoft Windows.
For more background on how this feature is implemented in KVM, see this article on IOThread Virtqueue Mapping as well this companion article demonstrating performance improvements for Database workloads in VMs running in a Red Hat Enterprise Linux (RHEL) environment.
Test description
I tested I/O throughput on two configurations:
- A cluster with local storage using the Logical Volume Manager provisioned by the Local Storage Operator (LSO)
- A separate cluster using OpenShift Data Foundation (ODF)
The configurations are very different and cannot be compared.
We tested on pods (for a baseline) and VMs. VMs were allocated 16 cores and 8 GB RAM. I used test files of 512 GB with 1 VM and 256 GB with 2 VMs. I used direct I/O in all tests. I used persistent volume claims (PVC), in block mode and formatted as ext4, for VMs, and filesystem mode PVCs also formatted as ext4 for pods. All tests were run with the libaio I/O engine.
I tested the following matrix:
Parameter | Settings |
Storage Volume Type | Local (LSO), ODF |
Number of Pods/VMs | 1, 2 |
Number of I/O Threads (VMs only) | None (baseline), 1, 2, 3, 4, 6, 8, 12, 16 |
I/O Operations | Sequential and random reads and writes |
I/O Block Sizes (bytes) | 2K, 4K, 32K, 1M |
Concurrent Jobs | 1, 4, 16 |
I/O iodepth (iodepth) | 1, 4, 16 |
I used ClusterBuster to orchestrate the tests. The VMs used CentOS Stream 9, and the pods likewise used CentOS Stream as a container image base.
Local storage
The local storage cluster was a 5 node (3 master + 2 worker) cluster consisting of Dell R740xd nodes containing 2 Intel Xeon Gold 6130 CPUs, each with 16 cores and 2 threads (32 CPUs) for 32 cores and 64 CPUs total. Each node contained 192 GB RAM. The I/O subsystem consisted of four Dell-branded Kioxia CM6 MU 1.6 TB NVMe drives configured as a RAID0 striped multiple device (MD) configuration with default settings. Persistent volume claims were carved out of this MD using the lvmcluster operator. Unfortunately, this rather modest configuration was all I had available, and it's very possible that a faster I/O system would yield even more improvement from multiple I/O threads.
OpenShift Data Foundation
The OpenShift Data Foundation (ODF) cluster was a 6 node (3 master + 3 worker) cluster consisting of Dell PowerEdge R7625 nodes containing 2 AMD EPYC 9534 CPUs, each with 64 cores and 2 threads (128 CPUs) for 128 cores and 256 CPUs total. Each node contains 512 GB RAM. The I/O subsystem consisted of two 5.8 TB NVMe drives per node, with 3-way replication over 25 GbE default pod network. I did not have access to a faster network for this test, but newer network hardware would likely have yielded better uplift.
Summary of results
This test evaluates multiple I/O threads with specific I/O back ends that may not be representative of your use case. Differences in storage characteristics can have a major impact on the choice of number of I/O threads.
Here's what my tests revealed.
- Maximum I/O throughput: for local storage, maximum throughput was about 7.3 GB/sec read and 6.7 GB/sec write, for both pods and VMs, regardless of iodepth or number of jobs on local storage. That is substantially less than what would be expected from the hardware. The devices (which are each 4x PCIe gen4) are rated for 6.9 GB/sec read and 4.2 MB/sec write. I've not investigated the reason for this, but I was running on aging hardware. The top performance is clearly better than the single drive performance, indicating that striping was having effect. For ODF, the best we achieved was about 5 GB/sec read and 2 GB/sec write.
- Large block I/O (1 MB) showed little if any improvement, because performance was already limited by the system.
- The optimal choice for the number of I/O threads varies with workload and storage characteristics. As expected, workloads without significant I/O concurrency showed little benefit.
- Local storage: For VMs with significant I/O concurrency, 4-8 is generally a good starting point. Particularly for workloads utilizing small I/O size and large concurrency, more threads can yield benefit.
- ODF: More than 1 I/O thread rarely yielded significant benefit, and in many cases none at all were needed. This is likely due to the comparatively slow pod network; it's likely that faster networking would yield different results.
- Multiple I/O threads were more effective at delivering improvement with multiple concurrent jobs than with deep asynchronous I/O, at least with this test.
- There was little difference in behavior between 1 and 2 concurrent VMs until underlying aggregate maximum I/O throughput (noted above) was reached.
- Multiple I/O threads did not completely close the gap with pods at lower job count or I/O iodepth. At high I/O iodepth with small operations, VMs actually outperformed pods by significant margins for write operations.
By the numbers
Here is the overall I/O throughput to be had using multiple I/O threads on my local storage based system. As you can see, with workloads involving smaller I/O sizes and lots of parallelism to a fast I/O system, there can be great benefits. I present more of my findings below about the benefit I got from different numbers of I/O threads below. I observed only minor improvement with a 1 MB block size because performance was already very close to the underlying system limit. With even faster hardware, it's possible that additional I/O threads would yield improvement even with large block sizes.
Best improvement over VM baseline with additional I/O threads | ||||||||||
(Local storage) | jobs | iodepth | ||||||||
1 | 4 | 16 | ||||||||
size | op | 1 | 4 | 16 | 1 | 4 | 16 | 1 | 4 | 16 |
2048 | randread | 18% | 31% | 30% | 30% | 103% | 192% | 151% | 432% | 494% |
randwrite | 81% | 59% | 24% | 153% | 199% | 187% | 458% | 433% | 353% | |
read | 67% | 58% | 25% | 64% | 71% | 103% | 252% | 241% | 287% | |
write | 103% | 64% | 0% | 143% | 99% | 84% | 410% | 250% | 203% | |
2048 Total | 67% | 53% | 20% | 97% | 118% | 141% | 318% | 339% | 334% | |
4096 | randread | 18% | 34% | 28% | 33% | 101% | 208% | 156% | 432% | 492% |
randwrite | 95% | 69% | 20% | 149% | 200% | 187% | 471% | 543% | 481% | |
read | 26% | 53% | 27% | 24% | 46% | 66% | 142% | 155% | 165% | |
write | 103% | 69% | 0% | 144% | 86% | 48% | 438% | 256% | 161% | |
4096 Total | 60% | 56% | 19% | 87% | 108% | 127% | 302% | 346% | 325% | |
32768 | randread | 16% | 23% | 26% | 23% | 71% | 124% | 99% | 160% | 129% |
randwrite | 75% | 71% | 28% | 108% | 132% | 116% | 203% | 123% | 115% | |
read | 21% | 57% | 25% | 21% | 42% | 32% | 77% | 54% | 32% | |
write | 79% | 64% | 26% | 104% | 59% | 24% | 195% | 45% | 27% | |
32768 Total | 48% | 53% | 26% | 64% | 76% | 74% | 143% | 96% | 76% | |
1048576 | randread | 5% | 2% | 0% | 9% | 0% | 0% | 17% | 0% | 0% |
randwrite | 10% | 0% | 1% | 6% | 0% | 2% | 9% | 0% | 2% | |
read | 12% | 18% | 0% | 9% | 0% | 0% | 16% | 0% | 0% | |
write | 19% | 0% | 0% | 7% | 0% | 0% | 9% | 0% | 0% | |
1048576 Total | 11% | 5% | 0% | 8% | 0% | 1% | 13% | 0% | 0% | |
Here are the number of I/O threads necessary to achieve 90% of the best result achievable with up to 16 I/O threads. For example, if the best result achieved in my test with a particular combination of operation, block size, jobs, and iodepth was 1 GB/sec, then the metric here would be the fewest threads needed to achieve 900 MB/sec. This allows setting a conservative number of threads while still achieving good performance.
Minimum iothread count to achieve 90% of best performance | ||||||||||
(Local storage) | jobs | iodepth | ||||||||
1 | 4 | 16 | ||||||||
size | op | 1 | 4 | 16 | 1 | 4 | 16 | 1 | 4 | 16 |
2048 | randread | 1 | 1 | 1 | 1 | 4 | 8 | 3 | 12 | 12 |
randwrite | 1 | 1 | 1 | 3 | 16 | 12 | 8 | 12 | 12 | |
read | 1 | 1 | 1 | 1 | 4 | 4 | 4 | 6 | 8 | |
write | 1 | 1 | 0 | 2 | 12 | 6 | 8 | 6 | 6 | |
2048 Total | 1 | 1 | 1 | 2 | 9 | 8 | 6 | 9 | 10 | |
4096 | randread | 1 | 1 | 1 | 1 | 4 | 8 | 3 | 12 | 12 |
randwrite | 1 | 1 | 1 | 3 | 16 | 12 | 8 | 12 | 12 | |
read | 1 | 1 | 1 | 1 | 2 | 3 | 3 | 6 | 8 | |
write | 1 | 1 | 0 | 3 | 12 | 4 | 8 | 6 | 4 | |
4096 Total | 1 | 1 | 1 | 2 | 9 | 7 | 6 | 9 | 9 | |
32768 | randread | 1 | 1 | 1 | 1 | 3 | 6 | 2 | 4 | 3 |
randwrite | 1 | 1 | 1 | 2 | 12 | 6 | 4 | 3 | 3 | |
read | 1 | 1 | 1 | 1 | 2 | 2 | 2 | 2 | 2 | |
write | 1 | 1 | 1 | 2 | 6 | 2 | 4 | 2 | 1 | |
32768 Total | 1 | 1 | 1 | 2 | 6 | 4 | 3 | 3 | 2 | |
1048576 | randread | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
randwrite | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
read | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | |
write | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
1048576 Total | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | |
Detailed results
For each test case measured, I calculated the following figures of merit:
- Measurement of I/O throughput
- Best VM performance (not directly reported)
- Minimum number of iothreads to achieve 90% of the best VM performance
- Ratio of best VM performance to pod performance
- Improvement of best VM performance over baseline VM performance
I am NOT reporting the number of threads for the best performance, because in many cases the differences were very small, less than the normal variance in reporting I/O performance.
I provide separate summaries for the results for local storage and ODF, due to the characteristics being so different.
All performance graphs below show results for pods (pod), a baseline VM without I/O threads (0) and the specified number of I/O threads on the X axis.
Local storage
If we look at raw performance, we see that in at least some cases using multiple I/O threads offers substantial benefit. For example, with 16 jobs, async I/O with iodepth 1, on local storage use of additional I/O threads can yield a benefit of the better part of an order of magnitude:
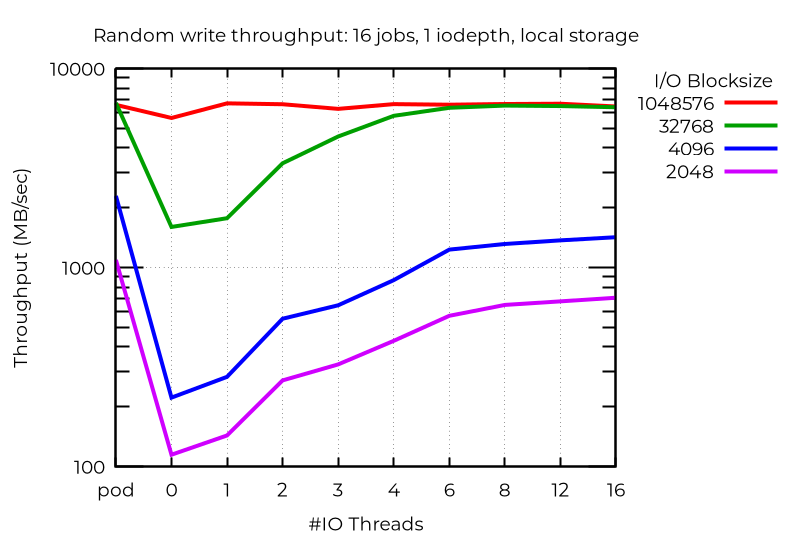
Even with a single stream I/O, the use of an extra I/O thread can yield benefit. Not surprisingly, more than one does not help:
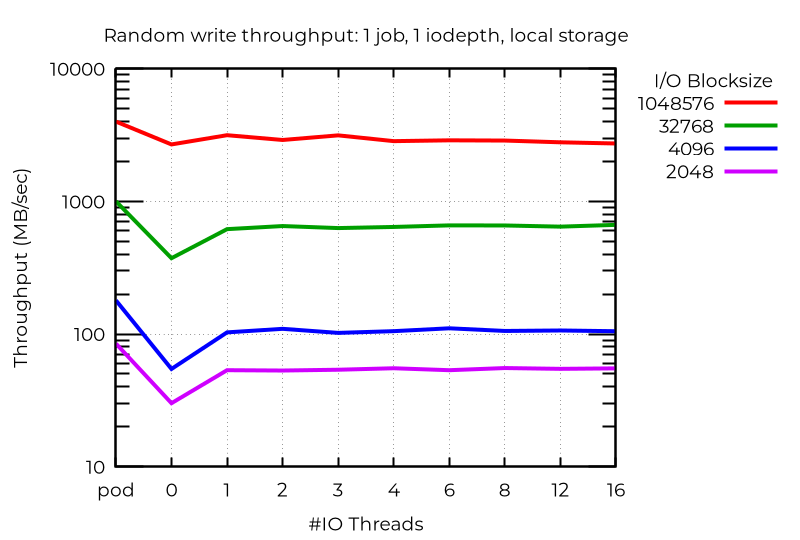
There are anomalous cases where extra I/O threads actually hurts performance. In this case, using deep asynchronous I/O with small blocks, the best performance (even better than pods) is actually achieved with VMs using no dedicated I/O threads. I have not determined why this happens.
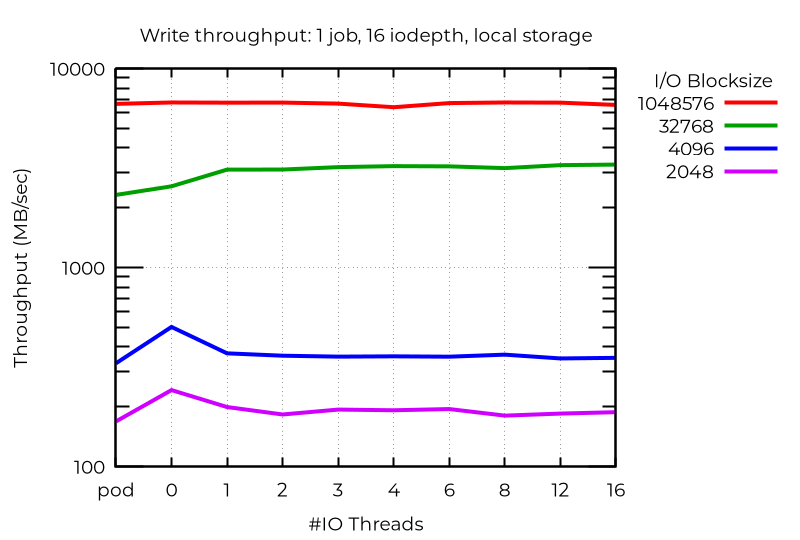
All of this demonstrates that to get the best performance out of multiple I/O threads, you need to experiment with your particular workload.
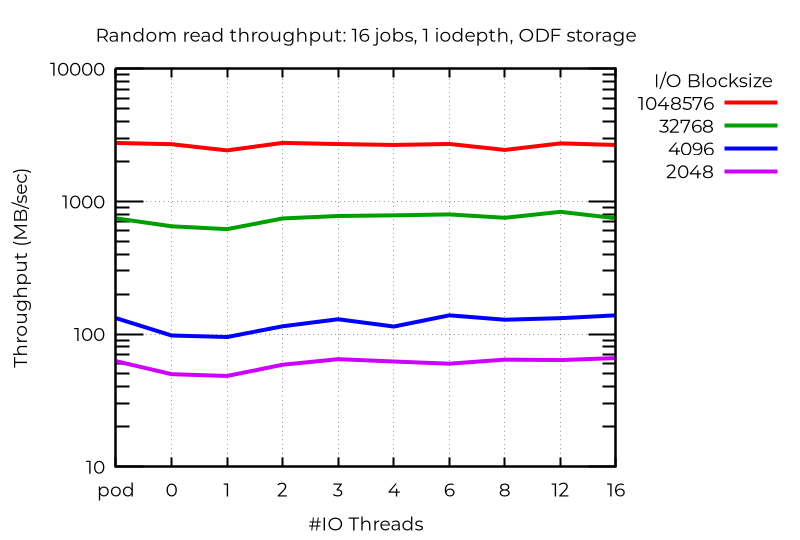
ODF cluster results
In contrast to local storage, where small block random write demonstrated dramatic improvement with multiple I/O threads, I observed minimal improvement with ODF even with high job counts. It's likely that faster, or lower latency, networking would yield greater benefit. Read operations, particularly random read, did demonstrate modest benefit, but writes, and lower job counts, showed little (if any) benefit.
Conclusions
Multiple I/O threads for OpenShift Virtualization is an exciting new feature in OpenShift 4.19 that offers the potential of substantial improvements in I/O performance for workloads with concurrent I/O, particularly with fast I/O systems such as the local NVMe storage used in my tests. Faster I/O subsystems are expected to benefit the most from multiple I/O threads, because more CPUs are needed to fully drive the underlying bare metal I/O. As always with I/O, differences in I/O systems and overall workloads can greatly affect performance, so I recommend testing your own workloads to take best advantage of this new feature. I hope that my test results help you make good choices for I/O threads!
product trial
Red Hat OpenShift Virtualization Engine | Product Trial
About the author

More like this
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds