We're seeing a significant trend: more organizations are bringing their large language model (LLM) infrastructure in-house. Whether for latency, compliance, or data privacy, self-hosting with open source models on your own hardware puts you in control of your AI journey. However, scaling LLMs from experimentation to a production-grade service introduces significant cost and complexity.
A new open source framework, llm-d, backed by a powerhouse of contributors including Red Hat, IBM, and Google, is designed to address these challenges. It focuses on the core of the problem: AI inference—the process where your model generates results for prompts, agents, retrieval-augmented generation (RAG), and more.
Through smart scheduling decisions (disaggregation) and AI-specific routing patterns, llm-d enables dynamic, intelligent workload distribution for LLMs. t Why is this so important? Let’s learn how llm-d works and how it can help save on AI costs, while increasing performance.
The challenge with scaling LLM inference
Scaling traditional web services on platforms like Kubernetes follows established patterns. Standard HTTP requests are typically fast, uniform, and stateless. Scaling LLM inference, however, is a fundamentally different problem.
One of the main reasons for this is the high variance in request characteristics. A RAG pattern, for example, might use a long input prompt packed with context from a vector database to generate a short, one-sentence answer. Conversely, a reasoning task might begin with a short prompt and produce a long, multi-step response. This variance creates load imbalances that can degrade performance and increase tail latency (ITL). LLM inference also relies heavily on key value (KV) cache, the short-term memory of an LLM, to store intermediate results. Traditional load balancing is unaware of this cache's state, leading to inefficient request routing and underutilized compute resources.
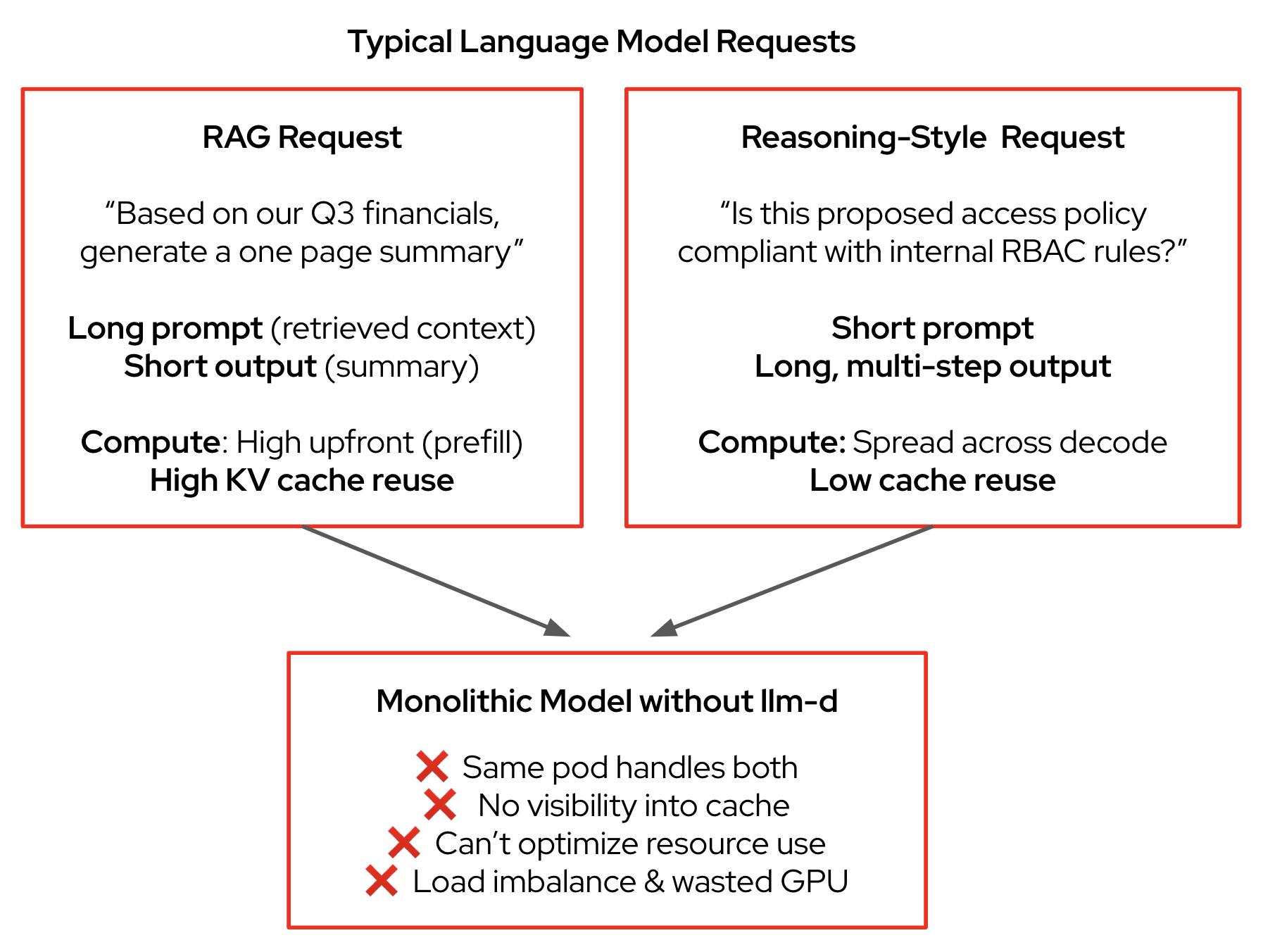
With Kubernetes, the current approach has been to deploy LLMs as monolithic containers–large, black boxes with no visibility or control. This, in addition to ignoring prompt structure, token count, response latency goals (Service Level Objectives or SLO), cache availability, and many other factors, makes it difficult to scale effectively.
In short, our current inferencing systems are inefficient and are using more computing resources than necessary.
llm-d is making inference more efficient and more cost-effective
While vLLM provides vast model support across a wide array of hardware, llm-d takes it a step further. Building on top of existing enterprise IT infrastructures, llm-d brings distributed and advanced inference capabilities to help save on resources and improve performance, including 3x improvements in time-to-first-token and doubled throughput under latency (SLO) constraints. Though it delivers a powerful suite of innovations, llm-d's main focus is around two innovations that help improve inference:
- Disaggregation: Disaggregating the process allows us to more efficiently use hardware accelerators during inference. This involves separating prompt processing (prefill phase) from token generation (decode phase) into individual workloads, called pods. This separation allows for independent scaling and optimization of each phase, since they have different computational demands.
- Intelligent scheduling layer: This extends the Kubernetes Gateway API, enabling more nuanced routing decisions for incoming requests. It leverages real-time data like KV cache utilization and pod load to direct requests to the most optimal instance, maximizing cache hits and balancing workload across the cluster.
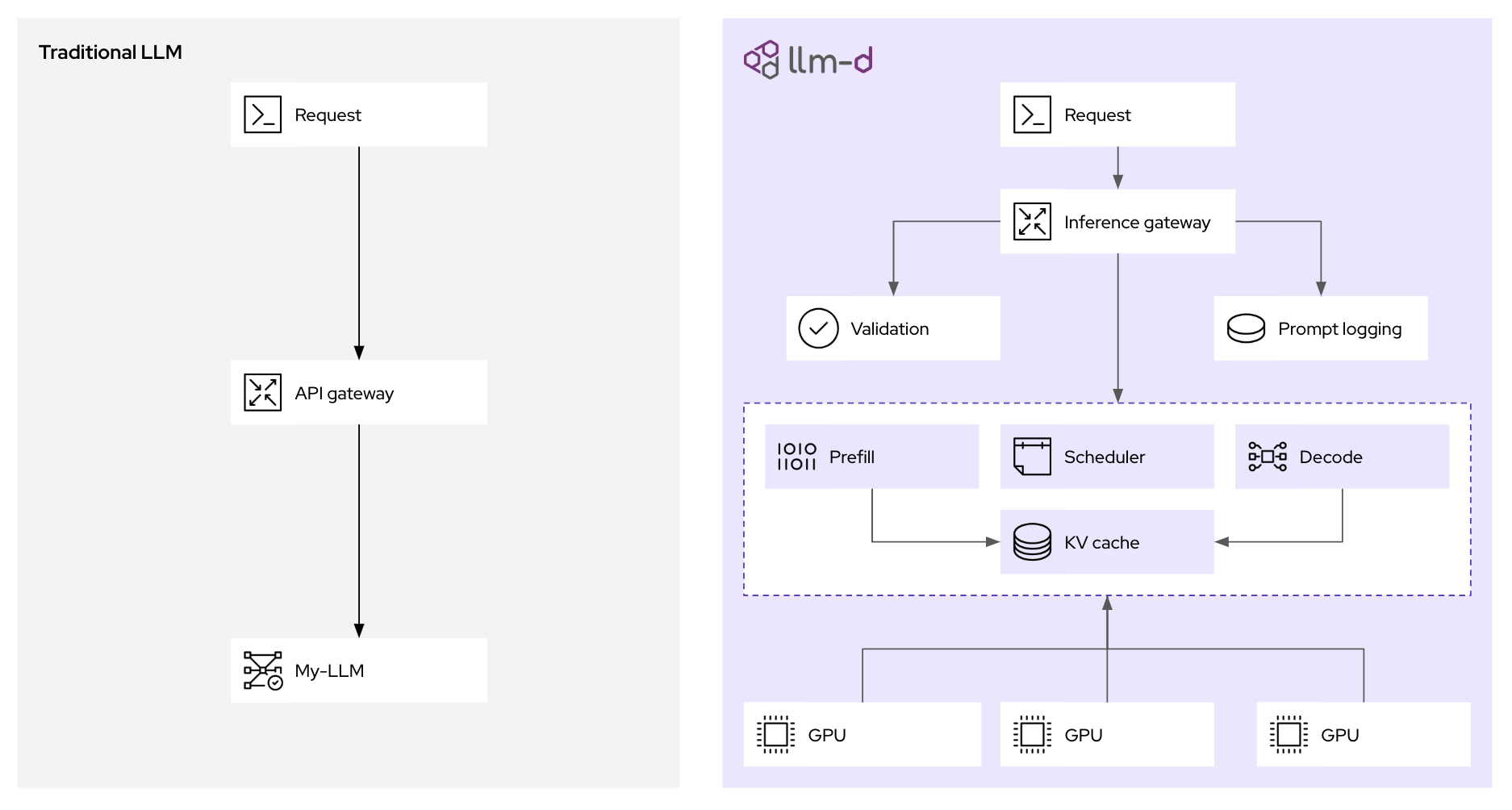
In addition to features such as caching KV pairs across requests to prevent recomputing, llm-d breaks LLM inference into modular, intelligent services for scalable performance (and builds on the extensive support that vLLM itself provides). Let’s dive a bit into each of these technologies and learn how they’re used by llm-d, with some practical examples.
How disaggregation increases throughput with lower latency
The fundamental difference between the prefill and decode phases of LLM inference presents a challenge for uniform resource allocation. The prefill phase, which processes the input prompt, is typically compute-bound, demanding high processing power to create the initial KV cache entries. Conversely, the decode phase, where tokens are generated one by one, is often memory-bandwidth bound, as it primarily involves reading from and writing to the KV cache with relatively less compute.
By implementing disaggregation, llm-d allows these two distinct computational profiles to be served by separate Kubernetes pods. This means you can provision prefill pods with resources optimized for compute-heavy tasks and decode pods with configurations tailored for memory-bandwidth efficiency.
How the LLM-aware inference gateway works
At the heart of llm-d's performance gains is its intelligent scheduling router, which orchestrates where and how inference requests are processed. When an inference request arrives at the llm-d gateway (based on kgateway), it's not simply forwarded to the next available pod. Instead, the endpoint picker (EPP), a core component of llm-d's scheduler, evaluates multiple real-time factors to determine the optimal destination:
- KV cache awareness: The scheduler maintains an index of the KV cache status across all running vLLM replicas. If a new request shares a common prefix with an already cached session on a specific pod, the scheduler prioritizes routing to that pod. This dramatically increases cache hit rates, avoiding redundant prefill computations and directly reducing latency.
- Load awareness: Beyond simple request counts, the scheduler assesses the actual load on each vLLM pod, considering GPU memory utilization and processing queues, helping to prevent bottlenecks.
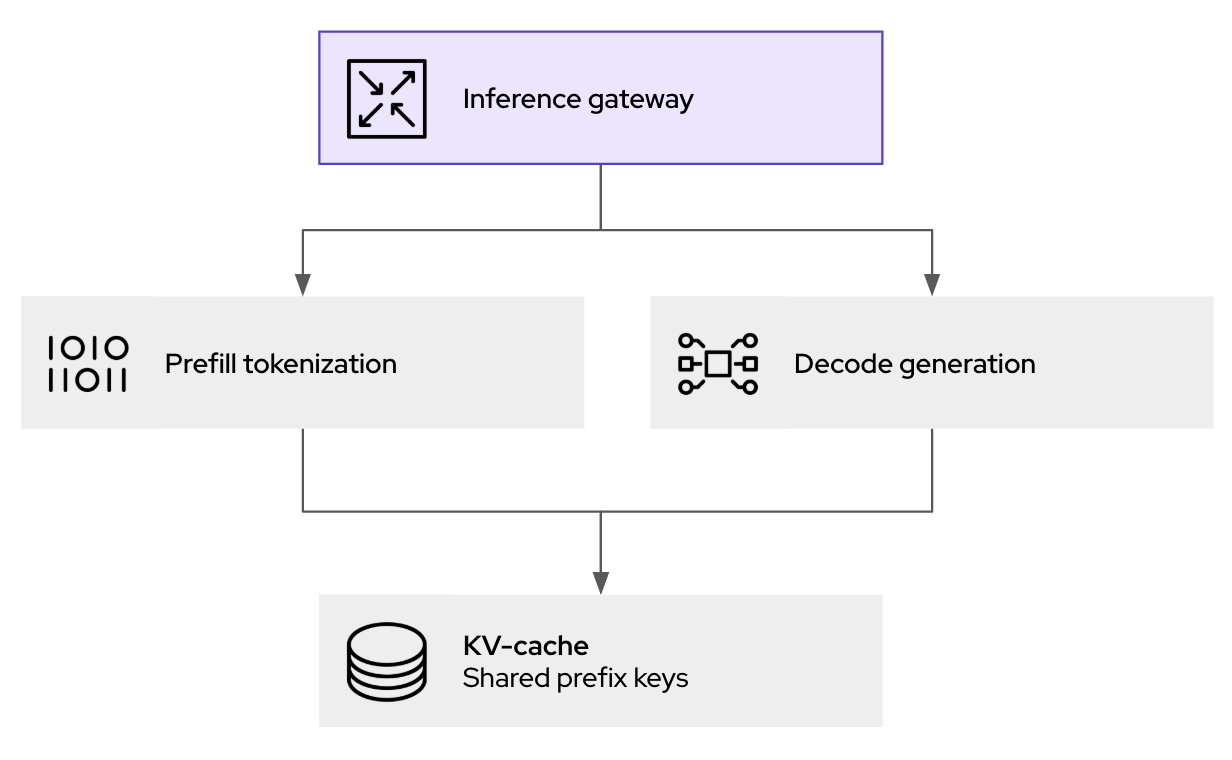
This Kubernetes-native approach provides the policy, security, and observability layer for generative AI inference. Not only does this help with handling traffic, but it also enables prompt logging and auditing (for governance and compliance) as well as guardrails before forwarding to inference.
Get started with llm-d
There’s exciting energy behind the llm-d project. While vLLM is ideal for single server setups, llm-d is built for the operator managing a cluster, aimed at performant, cost-efficient AI inference. Ready to explore it yourself? Check out the llm-d repository on GitHub and join the conversation on Slack! It’s a great place to ask questions and get involved.
The future of AI is being built on open and collaborative principles. With communities like vLLM and projects like llm-d, Red Hat is working to make AI more accessible, affordable, and powerful for developers everywhere.
resource
Introducción a la inteligencia artificial para las empresas: Guía para principiantes
Sobre el autor

Cedric Clyburn (@cedricclyburn), Senior Developer Advocate at Red Hat, is an enthusiastic software technologist with a background in Kubernetes, DevOps, and container tools. He has experience speaking and organizing conferences including DevNexus, WeAreDevelopers, The Linux Foundation, KCD NYC, and more. Cedric loves all things open-source, and works to make developer's lives easier! Based out of New York.
Más similar
Navegar por canal

Automatización
Las últimas novedades en la automatización de la TI para los equipos, la tecnología y los entornos

Inteligencia artificial
Descubra las actualizaciones en las plataformas que permiten a los clientes ejecutar cargas de trabajo de inteligecia artificial en cualquier lugar

Nube híbrida abierta
Vea como construimos un futuro flexible con la nube híbrida

Seguridad
Vea las últimas novedades sobre cómo reducimos los riesgos en entornos y tecnologías

Edge computing
Conozca las actualizaciones en las plataformas que simplifican las operaciones en el edge

Infraestructura
Vea las últimas novedades sobre la plataforma Linux empresarial líder en el mundo

Aplicaciones
Conozca nuestras soluciones para abordar los desafíos más complejos de las aplicaciones
Virtualización
El futuro de la virtualización empresarial para tus cargas de trabajo locales o en la nube