Red Hat OpenShift Data Foundation: almacenamiento permanente y gestión de los datos del clúster para Red Hat OpenShift
Red Hat® OpenShift® Data Foundation1 es una solución de almacenamiento permanente y gestión de los datos del clúster que se encuentra integrada a Red Hat OpenShift y optimizada para esta plataforma. Ofrece una plataforma de almacenamiento definida por software, distribuida y con capacidad de expansión, además de sofisticados servicios de gestión de los datos del clúster para empresas, lo que permite que las aplicaciones interactúen con los datos de manera sencilla, uniforme y adaptable. Las empresas pueden trasladarlos a varias infraestructuras y agruparlos gracias a las funciones de gestión de datos multicloud.
Una base para los datos de las aplicaciones y las cargas de trabajo de producción modernas
Al igual que Red Hat OpenShift, OpenShift Data Foundation se puede ejecutar en los entornos locales, en los entornos de nube pública o privada y en el extremo de la red. Usa protocolos comunes, como los de archivos, bloques y objetos, para ofrecer acceso ágil y flexible a los datos y, así, admitir una gran variedad de cargas de trabajo y aplicaciones. La plataforma aísla los detalles y las incongruencias entre las diferentes infraestructuras de almacenamiento, a la vez que presta los sofisticados servicios de gestión de los datos del clúster que necesitan las empresas.
OpenShift Data Foundation se creó para entornos basados en contenedores, y también es compatible con Red Hat OpenShift Virtualization. Gracias al operador de Red Hat OpenShift, resulta sencillo instalar y gestionar la plataforma como parte del ciclo de vida de las aplicaciones basadas en contenedores, lo cual incluye la organización, la programación y la gestión de contenedores propios de la nube. Algunos de los beneficios que brinda este nivel de integración son los siguientes:
- Almacenamiento para Kubernetes empresarial de confianza. OpenShift Data Foundation admite cargas de trabajo diversas, ofrece funciones de puertas de enlace de objetos multicloud2 y brinda continuidad empresarial para las cargas de trabajo en ejecución en Red Hat OpenShift.
- Protección y resistencia de los datos para Red Hat OpenShift. El soporte incluye funciones esenciales como la replicación, el alojamiento de datos en diferentes zonas de disponibilidad y los servicios de backup y restauración para las aplicaciones de Kubernetes, lo cual comprende los datos relacionados con el espacio de nombres, los recursos personalizados y el estado.
- Una experiencia similar a la nube en todos lados. OpenShift Data Foundation proporciona el almacenamiento definido por software que permite que las empresas lo implementen junto con las aplicaciones según sea necesario y se ajuste a distintas situaciones.
- Aumento en la productividad de los desarrolladores. OpenShift Data Foundation brinda funciones y una experiencia del usuario uniformes en todas las plataformas de nube híbrida, lo cual simplifica los procesos de los desarrolladores y los usuarios.
- Modernización de las aplicaciones y los datos. Gracias a la compatibilidad con Red Hat OpenShift Virtualization, las empresas pueden seguir ejecutando sus aplicaciones actuales a la vez que desarrollan otras nuevas propias de la nube, todo en una sola plataforma.
Especificaciones técnicas
OpenShift Data Foundation se encuentra disponible en las versiones Essentials y Advanced (Tabla 1). La versión OpenShift Data Foundation Essentials se incluye con Red Hat OpenShift Platform Plus y ofrece Red Hat OpenShift Container Platform junto con los siguientes elementos:
Red Hat Advanced Cluster Management for Kubernetes
Red Hat Advanced Cluster Security for Kubernetes
Red Hat Quay (una plataforma de registro privado de contenedores global y centrada en la seguridad)
Aspectos destacados
Acceso simplificado a una experiencia de plataforma de datos completa y uniforme para Red Hat OpenShift
Una experiencia del usuario uniforme e independiente de la ubicación de los datos, lo cual brinda uniformidad en todos los entornos de nube y confianza entre los equipos
Capacidad de ampliación a varios petabytes gracias a la resistencia de las tareas empresariales más importantes y el rendimiento óptimo
Sofisticadas funciones de gestión de datos y de continuidad empresarial para las implementaciones en el centro de datos, los entornos de nube pública o privada o el extremo de la red
Tabla 1. Versiones de OpenShift Data Foundation
| Funciones que ofrece la versión Essentials | Funciones que agrega la versión Advanced |
|
|
En la tabla 2, se resumen las características y las funciones de OpenShift Data Foundation.
Tabla 2. Características y funciones
| Continuidad empresarial y recuperación ante desastres | |
| OpenShift APIs for Data Protection | Las interfaces de backup y recuperación de datos que tienen en cuenta los clústeres incluyen el backup y la recuperación de espacios de nombres de cargas de trabajo, aplicaciones y servicios de clústeres individuales. |
| Recuperación ante desastres entre regiones | La recuperación ante desastres asíncrona para los problemas de los centros de datos se puede extender a diferentes regiones o continentes mediante la red de área amplia (WAN) para ofrecer protección ante los desastres entre regiones. |
| Recuperación ante desastres dentro del área metropolitana | La recuperación ante desastres sincrónica para los problemas de los clústeres ofrece protección ante los problemas del sistema y permite recuperar todo dentro del entorno de un campus o un área metropolitana en el que se encuentran disponibles redes de baja latencia. |
| Servicios de datos en el extremo de la red | |
| Clústeres de tres nodos compactos | Admite Red Hat OpenShift y OpenShift Data Foundation en tres nodos de producción. |
| OpenShift de un solo nodo | Una configuración de OpenShift Data Foundation de un solo nodo admite implementaciones ligeras, instantáneas y backups para las ubicaciones en el extremo de la red de un entorno de infraestructura pequeña. |
| Implementación ligera de un solo nodo | La implementación ligera permite aumentar los recursos con el transcurso del tiempo para satisfacer la demanda de los usuarios. |
| Supervisión de varios clústeres | |
| Paneles de varios clústeres | Los paneles de varios clústeres se integran a Red Hat Advanced Cluster Management para ofrecer supervisión desde un solo lugar en relación con el estado y la optimización de varios clústeres y, así, identificar, aislar y resolver los problemas que afectan a las cargas de trabajo distribuidas. |
| Puerta de enlace multicloud | |
| Buckets de objetos | Los buckets de objetos brindan almacenamiento de datos con opciones disponibles de duplicación, propagación y cifrado, además de varios enfoques de clasificación por niveles compatibles. |
| Buckets de espacios de nombres | Los buckets de espacios de nombres se pueden usar para funciones de unificación de los datos con el fin de organizar, configurar y gestionar varios recursos de datos sin necesidad de copiar y remplazar conjuntos de datos. |
| Solicitudes de buckets de objetos | Las solicitudes de buckets de objetos permiten que los usuarios creen buckets de objetos de forma dinámica para los flujos de trabajo de los desarrolladores, de manera que se ajusten a los flujos de trabajo de solicitudes de volúmenes permanentes. |
| Seguridad de los datos mejorada | |
| Cifrado de extremo a extremo | El cifrado de extremo a extremo entre el clúster y los clientes mejora la seguridad de los datos en todo el clúster. |
| Cifrado de volumen permanente | Cifre los datos en el volumen permanente con un sistema de gestión de claves que le permitirá incorporar su propia clave. |
| Integración al sistema de gestión de claves (KMS) | La compatibilidad con el protocolo de interoperabilidad de gestión de claves (KMIP) integra el cifrado a las claves que proporcionó el usuario. |
| Compatibilidad con el sistema de archivos de red (NFS) | |
| Compatibilidad con NFS | Los servicios NFS para las aplicaciones internas o externas respaldan la interacción con las aplicaciones heredadas, la modernización de las aplicaciones y la futura migración a un entorno de Red Hat OpenShift. |
Resumen "OpenShift Data Foundation". Red Hat, 4 de noviembre de 2022.
"Multicloud object gateway namespace bucket replication". Red Hat, 1.° de julio de 2022.
Adopción de cargas de trabajo diversas
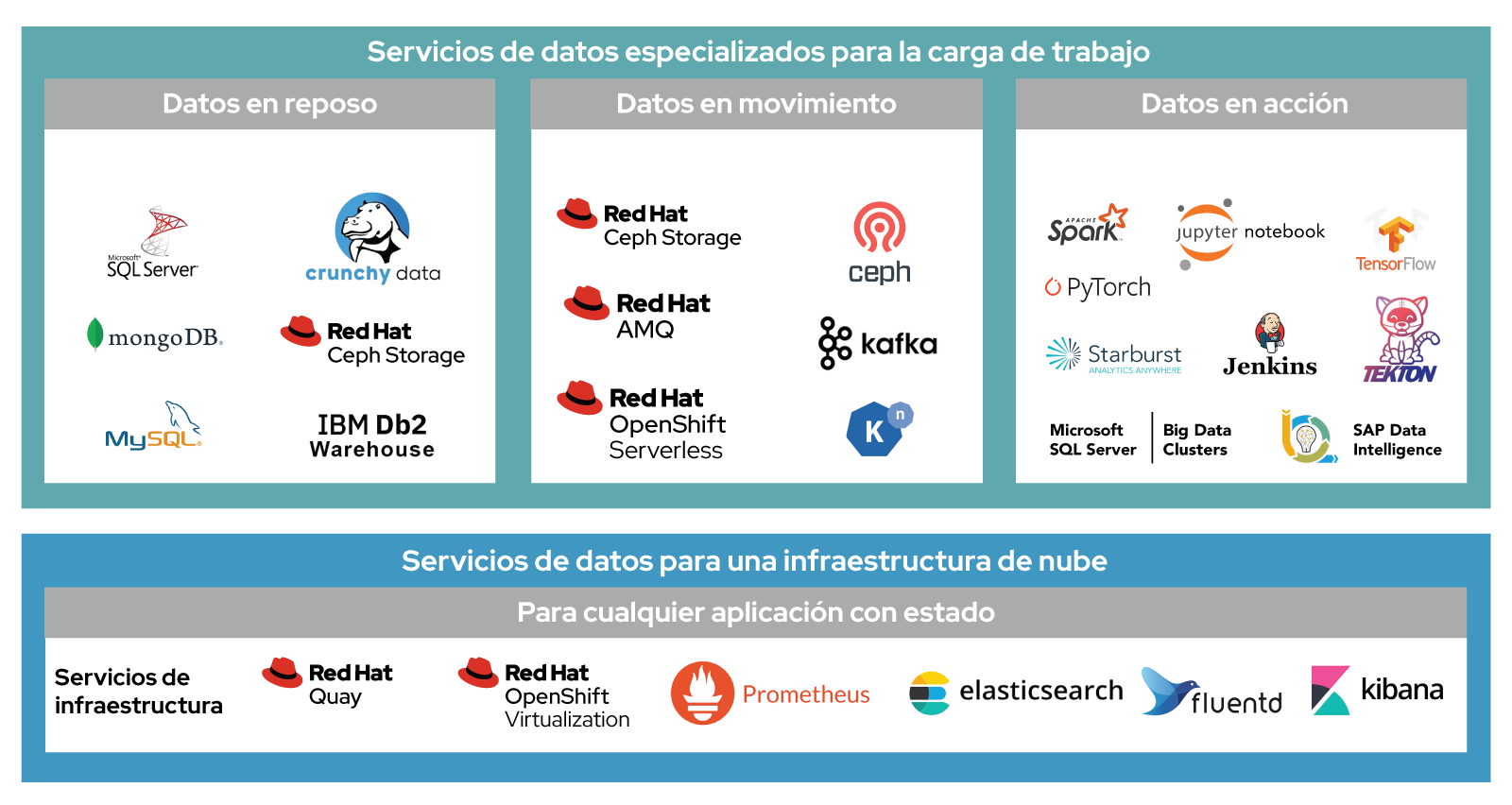
La mayoría de los proveedores de nube dan soporte al almacenamiento de datos en cargas de trabajo diversas pero, en general, con varias tecnologías. Esto lleva mucho tiempo, ya que es complejo de comprender y gestionar, y puede crear una dependencia de un proveedor de nube determinado, porque otros ofrecen combinaciones diferentes de tecnologías y funciones. En cambio, OpenShift Data Foundation proporciona almacenamiento de contenedores que da soporte a los datos en reposo, en movimiento y en acción (Figura 2). Es compatible con varias plataformas de nube y funciona con una amplia variedad de partners y tecnologías.
Además, Red Hat OpenShift Data Foundation, el cual se basa totalmente en la tecnología de open source, admite el almacenamiento de archivos, objetos y bloques, y utiliza un conjunto único de operadores de Kubernetes para todas las plataformas de nube. Las empresas pueden ofrecer almacenamiento definido por el software para diversos tipos de cargas de trabajo con una solución exclusiva, y trasladar las aplicaciones de una plataforma de nube a la otra con facilidad, ya que son totalmente compatibles.
Los ejemplos de uso más conocidos para OpenShift Data Foundation incluyen:
- Repositorios de datos y desarrollo de aplicaciones en la nube, entre los que se encuentran los modelos de innovación/implementación continuas (CI/CD).
- Datos estructurados, entre ellos, las bases de datos SQL/NoSQL y los almacenes de datos.
- Cargas de trabajo de big data tales como el análisis de datos y las cargas IA/ML.
- Protección de datos que tiene en cuenta los contenedores y que ofrece copias de seguridad y soporte a la resistencia de datos para volúmenes permanentes y espacios de nombres de Kubernetes.
Conclusión
Independientemente de que Red Hat OpenShift se ejecute en una infraestructura local, en una nube pública o en una nube híbrida, Red Hat OpenShift Data Foundation brinda acceso simplificado, experiencia uniforme y ajuste dinámico para los servicios permanentes de datos, los cuales están integrados directamente y se pueden utilizar en muchos tipos de cargas de trabajo. La implementación de Red Hat OpenShift Data Foundation simplifica la gestión de datos y permite preparar y eliminar el almacenamiento según sea necesario como una parte integral de entornos unificados y organizados en contenedores.
Consulte las notas de la versión más reciente de Red Hat OpenShift Data Foundation para obtener información sobre las plataformas soportadas.