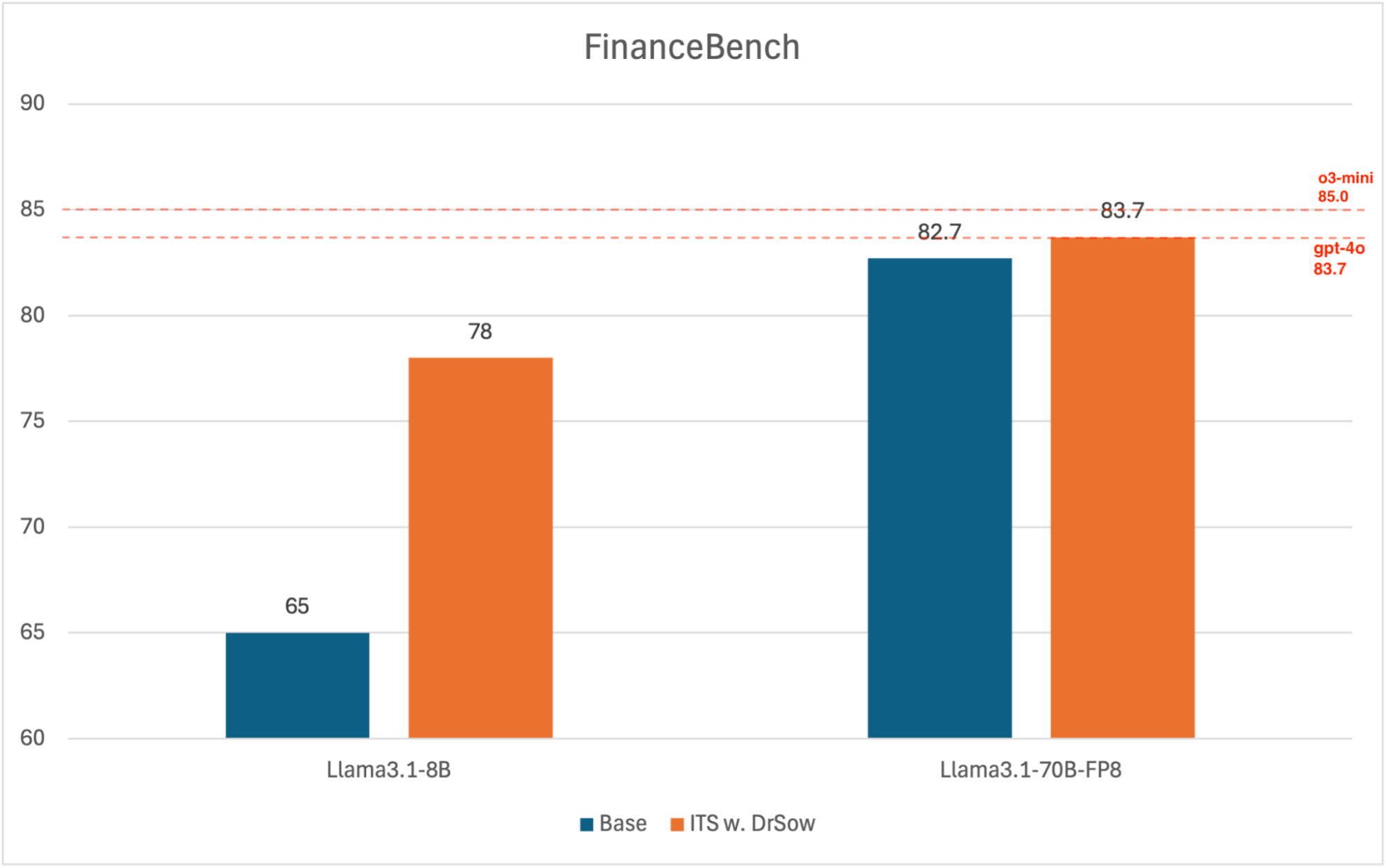
Figure 1: Inference-Time Scaling (ITS) with DrSoW improves FinanceBench accuracy for both small and large models—boosting Llama3.1-8B by 13 points and enabling Llama3.1-70B-FP8 to match GPT-4o-level performance (83.7%) without additional training.
In the race to deploy artificial intelligence (AI) solutions, many organizations focus on throughput—how many tokens per second a model can generate.
Though speed reduces cost, accuracy drives business value. In enterprise AI—from finance to healthcare— “A wrong answer costs more than a slow one.”
Imagine if you could enhance the accuracy of your AI models without retraining them, simply by optimizing how they operate during inference. This is where inference-time scaling (ITS) comes into play—a technique that reallocates computational resources during inference to improve large language model (LLM) response quality.
Understanding inference-time scaling
Typically, improving AI model performance involves increasing the size of model or training data, but these approaches come with significant costs and diminishing returns. ITS offers an alternative by focusing on how models use computational resources during test-time.
“Think of ITS as letting your model ‘sleep on it’ before answering—Like a comedian testing a few punchlines in their head before delivering the one that lands.”
There are two primary ITS strategies:
- Learned sequential search (reasoning): Models like OpenAI’s o3 and DeepSeek-R1 spend more time “thinking” through steps, enhancing reasoning capabilities.
- Verifier-guided parallel search (the focus of this article): This approach generates multiple candidate responses and selects the best one using a reward model or heuristic. It doesn’t require additional training, and can be applied on any off-the-shelf models.
Real-world application: ITS in finance
Video: Greedy decoding suffers from logical errors; Parallel search allows the model to explore multiple reasoning paths, significantly increasing the chance of arriving at the correct answer.
So, how well does a small LLM like Llama-3.1-8B-Instruct handle real-world finance questions? We find that the 8B model often stumbles in the first try, but when we allow it three chances to answer, and use an external reward model to select the best response, the same model nails the answer.
That trick is ITS in miniature—specifically, best-of-N sampling.
To see if the ITS technique scales, we ran the same best-of-N recipe over the entire FinanceBench suite—questions grounded in real SEC filings.
We tested two open source models:
- Llama3.1-8B-Instruct: A smaller, more efficient model.
- Llama3.1-70B-Instruct-FP8: A larger model quantized to 8 bits by Red Hat AI, a portfolio of products that accelerates the development and deployment of AI solutions.
When enhanced with a general-purpose reward model, Dr. SoW, we saw:
- A 13-point improvement in the 8B model (65 → 78 % accuracy)
- The quantized 70B model achieved GPT-4o level accuracy (83.7%) without any fine-tuning
Why it works: Small LLMs tend to extract relevant information well, but struggle with precision in reasoning. Their answers contain the right pieces, but are stitched together with logical errors or incomplete steps. Inference-time scaling fixes that by sampling alternate solution paths and letting the reward model choose the solution with the best reasoning and structure.
You can try out the method in the inference-time scaling repo and reward_hub.
Dr. SoW: Plug-and-play reward modeling
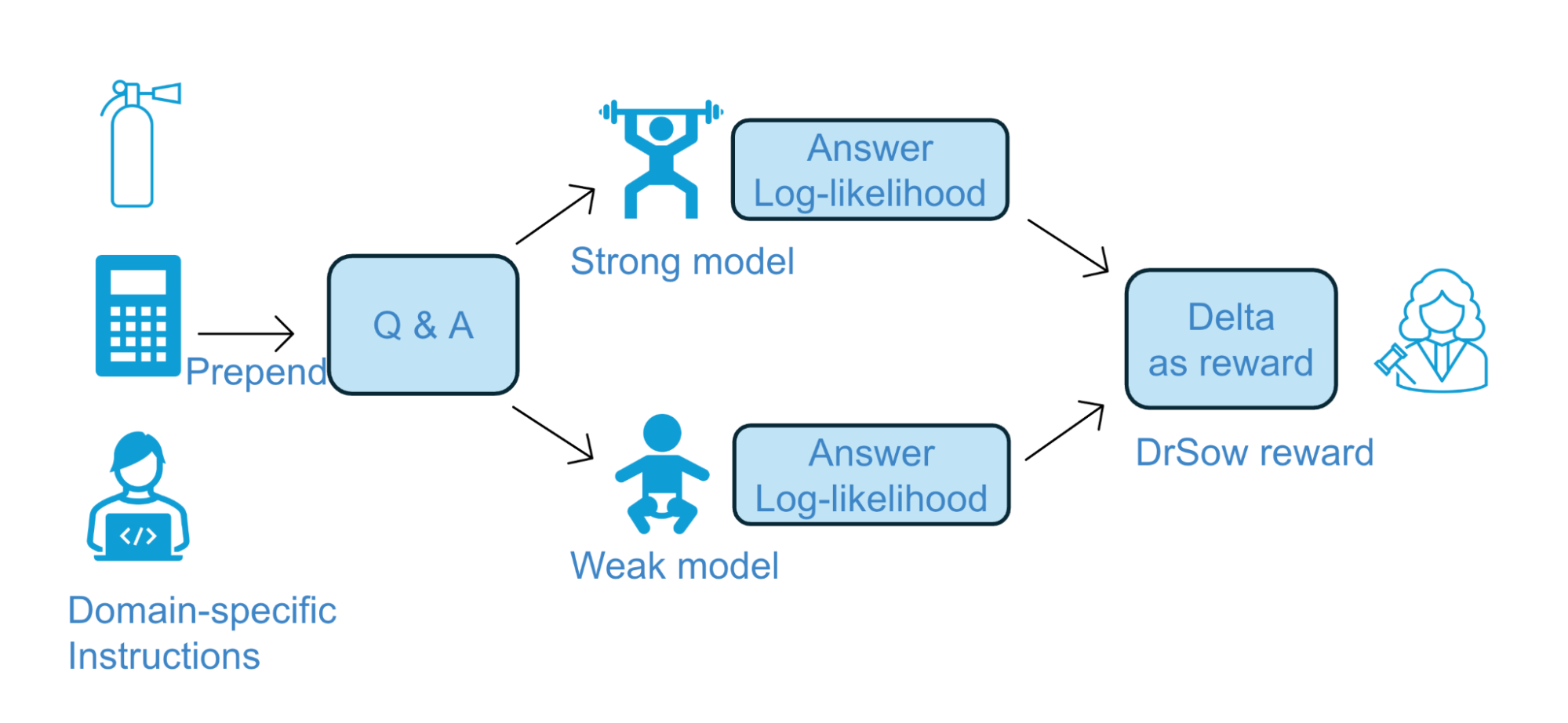
Figure 3: Dr. SoW is a pointwise reward model derived by contrasting the log-probabilities of a stronger and weaker model. It can be guided by task-specific instructions, enabling customization for domain-specific performance gains.
Since verifier-based search methods such as best-of-N or particle filtering depend on good external rewards, you may wonder if you need to train a specialized reward model for each use-case. The answer is nope! We used Dr. SoW (Density Ratio of Strong-over-Weak), a general-purpose, plug-and-play reward modeling method.
Instead of relying on expensive fine-tuning or opaque proprietary judges, Dr. SoW uses a simple but powerful insight: the difference in how two language models (one strong, one weak) assign probability to the same output encodes a preference. Our paper shows that it is a reliable reward signal that selects better answers—purely at inference time.
Challenge | Traditional approach | Dr. SoW advantage |
Training reward models is costly | Fine-tune on labeled data, often domain-specific | No training needed |
Custom reward models often don’t generalize | Manual retraining for each domain (finance, healthcare, SQL, etc.) | Choices of model pairs plus prompt-guided customization enables domain generalization |
Proprietary models hinder commercial use | Frontier models, such as GPT-4, as a judge | Leverage fully open source, Apache/MIT-licensed models |
Key takeaways for enterprises
- Prioritize accuracy: A wrong answer costs more than a slow one
- Scale smarts, not size: Inference-time scaling upgrades your existing models—no additional training needed
- Build inference-time scaling into your infrastructure: More compute for higher performance should be a runtime choice, a single button click to unlock for your existing models
Connect with Us
If you’re developing AI infrastructure for enterprise applications, it’s time to look beyond tokens per second.
Curious how to scale your LLM’s accuracy without retraining?
Let’s chat. Connect with Red Hat AI on X and LinkedIn and explore how inference-time scaling can boost your AI application—today.
resource
エンタープライズ AI を始める:初心者向けガイド
執筆者紹介

Guangxuan (GX) Xu is a Research Engineer at Red Hat AI Innovation Team, specializing in large language model alignment, emergent reasoning, and enterprise-scale AI deployment. He holds a Master's degree in Computer Science from UCLA, with research published at leading venues including ACL, AAAI, and ICLR.
Previously at IBM Research, he contributed to InstructLab and RL-driven optimization methods for foundation models. His work bridges frontier AI research with real-world impact across business, science, and human applications.

類似検索
チャンネル別に見る

自動化
テクノロジー、チームおよび環境に関する IT 自動化の最新情報

AI (人工知能)
お客様が AI ワークロードをどこでも自由に実行することを可能にするプラットフォームについてのアップデート

オープン・ハイブリッドクラウド
ハイブリッドクラウドで柔軟に未来を築く方法をご確認ください。

セキュリティ
環境やテクノロジー全体に及ぶリスクを軽減する方法に関する最新情報

エッジコンピューティング
エッジでの運用を単純化するプラットフォームのアップデート

インフラストラクチャ
世界有数のエンタープライズ向け Linux プラットフォームの最新情報

アプリケーション
アプリケーションの最も困難な課題に対する Red Hat ソリューションの詳細
仮想化
オンプレミスまたは複数クラウドでのワークロードに対応するエンタープライズ仮想化の将来についてご覧ください