Die Verwaltung von Kapazitäten und Überlastung in Red Hat OpenShift kann komplex erscheinen, aber das Verständnis der Schlüsselkonzepte macht die Dinge einfacher. Im Folgenden finden Sie eine Aufschlüsselung dessen, was Sie über Pod-Anforderungen, -Beschränkungen und Best Practices zu deren Festlegung wissen müssen. Außerdem erfahren Sie, wie die einzelnen Themen zu einer effektiven Verwaltung von Kapazitäten und Überlastung beitragen.
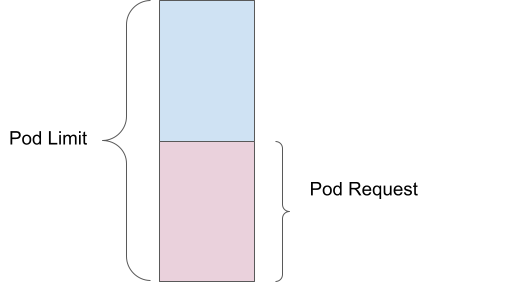
Pod-Anforderung
Eine Pod-Anforderung ist die Menge an Rechenressourcen (wie Arbeitsspeicher oder CPU), die Sie als Minimum für die Ausführung Ihres Containers angeben. Wenn Sie beispielsweise eine Arbeitsspeicheranforderung von 1 GB festlegen, stellt der Scheduler sicher, dass mindestens 1 GB Arbeitsspeicher für Ihren Pod verfügbar ist, bevor er auf einem Knoten platziert wird.
Vorteil des Kapazitätsmanagements: Stellt sicher, dass wichtige Ressourcen für jeden Pod reserviert werden, um Ressourcenengpässe zu vermeiden und zu gewährleisten, dass alle Pods über die für einen effektiven Betrieb minimal erforderlichen Ressourcen verfügen.
Pod-Limit
Ein Pod-Limit hingegen ist die maximale Menge an Ressourcen, die Ihr Pod verwenden kann. Wenn Sie ein Arbeitsspeicher-Limit von 2 GB festlegen, kann der Pod bis zu 2 GB Arbeitsspeicher verwenden, jedoch nicht mehr. Dies wird vom Kernel über cGroups erzwungen, wodurch verhindert wird, dass ein einzelner Pod zu viele Ressourcen verbraucht, was sich auf andere Pods auswirkt.
Vorteil des Kapazitätsmanagements: Schutz vor Ressourcenüberbelegung durch einzelne Pods und geeignete Verteilung der Ressourcen auf alle ausgeführten Pods.
Überlastung
Eine Überlastung erfolgt, wenn das Limit die Anforderung überschreitet. Wenn beispielsweise ein Pod eine Arbeitsspeicheranforderung von 1 GB und ein Limit von 2 GB hat, wird er basierend auf der 1 GB-Anforderung geplant, kann jedoch bis zu 2 GB verwenden. Dies bedeutet, dass der Pod um 200 % überlastet ist, da er die doppelte Menge an Arbeitsspeicher verwenden kann, die garantiert wurde.
Vorteil des Kapazitätsmanagements: Ermöglicht eine effizientere Nutzung von Cluster-Ressourcen, indem es Pods ermöglicht wird, zusätzliche Ressourcen zu verwenden, sofern verfügbar, ohne diese Ressourcen zu garantieren.
Folgen der Nichtfestlegung von Anforderungen und Beschränkungen
Anforderungen und Limits sorgen dafür, dass Ihre Red Hat OpenShift Instanz effizient und vorhersehbar ausgeführt wird. Legen Sie keine Definitionen fest, hat das Auswirkungen.
Keine garantierten Ressourcen
Wenn Sie keine Ressourcenanforderungen festlegen, garantiert der Scheduler keine bestimmte Menge an CPU-Ressourcen oder Arbeitsspeicher für Ihre Pods. Wenn der Knoten stark ausgelastet ist, kann dies zu einer schlechten Performance oder sogar zum Ausfall von Pods führen.
Keine Obergrenze für die Ressourcennutzung
Ohne Limits kann ein Container so viel CPU und Arbeitsspeicher so viel CPU und Arbeitsspeicher verwenden, wie er benötigt. Dies kann zu einem Ressourcenmangel führen, bei dem ein Container alle verfügbaren Ressourcen nutzt, was dazu führt, dass andere Container versagen oder entfernt werden.
Vorteil des Kapazitätsmanagements: Das Festlegen von Anforderungen und Limits sorgt für eine ausgewogene Ressourcenzuweisung und verhindert sowohl eine Unterversorgung (Ressourcenengpässe) als auch eine Überversorgung (Ressourcenüberlastung).
Best Practices zum Festlegen von Anforderungen und Limits
Im Allgemeinen sind beim Festlegen von Anforderungen und Beschränkungen 5 Best Practices zu beachten:
- Legen Sie immer Speicher- und CPU-Anforderungen fest
- Vermeiden Sie das Festlegen von CPU-Limits, da dies zu Throttling führen kann
- Überwachen Sie Ihre Workloads. Legen Sie Anforderungen basierend auf der durchschnittlichen Nutzung im Zeitverlauf fest
- Legen Sie die Speichergrenzen auf einen Skalierungsfaktor der Anforderung fest
- Verwenden Sie Vertikal Pod Autoscaler (VPA), um diese Werte im Laufe der Zeit zu optimieren und anzupassen
Vorteil des Kapazitätsmanagements: Mit diesen Praktiken stellen Sie sicher, dass jeder Pod die benötigten Ressourcen erhält und gleichzeitig eine Überzuweisung vermieden wird. Dies führt zu einer effizienten Ressourcennutzung und einer verbesserten Cluster-Performance.
Verwenden von Vertical Pod Autoscaler (VPA) zur geeigneten Größenanpassung
Die Komponente Vertical Pod Autoscaler (VPA) von Red Hat OpenShift passt CPU- und Arbeitsspeichervolumen an, die einem Pod zugewiesen sind, wenn der Pod mehr Ressourcen benötigt. Beachten Sie bei der Verwendung von VPA Folgendes:
- Installieren und konfigurieren Sie VPA nur im Recommendation-Modus
- Führen Sie reale Lastsimulationen auf Ihren Pods aus
- Beachten Sie die empfohlenen Werte, und passen Sie die Pod-Ressourcen entsprechend an
Warum nur im Recommendation-Modus?
Wenn Sie VPA auf den Modus Automatic festlegen, werden Pods neu gestartet, um sie an die empfohlenen Werte anzupassen. In-Place-VPA (ohne Neustarts) befindet sich ab Red Hat OpenShift 4.16 in der Alpha-Version.
Anpassung der Überwachungszeit für Empfehlungen
VPA unterstützt benutzerdefinierte Empfehlungen, sodass Sie die Überwachungszeiten je nach Bedarf auf 1 Tag, 1 Woche oder 1 Monat festlegen können. Weitere Details finden Sie unter Automatische Anpassung von Pod-Ressourcen mit Vertical Pod Autoscaler.
Vorteil des Kapazitätsmanagements: VPA unterstützt die dynamische Anpassung von Ressourcenanforderungen und -beschränkungen auf Grundlage der tatsächlichen Nutzungsmuster. Dies gewährleistet eine optimale Ressourcenzuweisung und minimiert eine Überbelegung.
Vom System reservierte Ressourcen in Red Hat OpenShift
Eine Ressource kann als „vom System reserviert“ festgelegt werden. Das heißt, dass Red Hat OpenShift einen Teil der Knotenressourcen (CPU und Speicher) für Prozesse auf Systemebene zuweist, wie Kubelet und Container Runtime. Dies bietet viele Vorteile:
- Gewährleistet dedizierte Ressourcen für Systemprozesse und vermeidet Konflikte mit Anwendungs-Workloads
- Verbessert die Stabilität und Performance von Knoten, indem Ressourcenengpässe für wichtige Systemservices vermieden werden
- Gewährleistet zuverlässigen Betrieb und vorhersehbare Performance des Clusters
Sie können die automatische Ressourcenzuweisung für Knoten aktivieren, indem Sie die Anweisungen für selbst gemanagte OpenShift-Cluster in der OpenShift-Dokumentation befolgen. Eine gemanagte OpenShift-Instanz wie Red Hat OpenShift Service on AWS (ROSA) übernimmt die Verwaltung für Sie.
Vorteil des Kapazitätsmanagements: Die Zuweisung von Ressourcen für Systemprozesse stellt sicher, dass wichtige Services reibungslos ausgeführt werden. Unterbrechungen der Anwendungsperformance aufgrund von Ressourcenkonflikten auf Systemebene werden vermieden.
Cluster Autoscaler
Ein Cluster Autoscaler fügt Knoten nach Bedarf automatisch hinzu oder entfernt sie. Dies funktioniert in Verbindung mit dem Horizontal Pod Autoscaler (HPA). Weitere Details finden Sie im OpenShift Cluster Autoscaler Guide und in der OpenShift Dokumentation zur automatischen Skalierung.
Vorteil des Kapazitätsmanagements: Der Cluster Autoscaler stellt sicher, dass Ihr Cluster über die richtige Anzahl an Knoten verfügt, um aktuelle Workloads zu bewältigen, und diese je nach Bedarf automatisch skaliert. Dies trägt zu einer optimalen Ressourcennutzung und Kosteneffizienz bei.
ClusterResourceOverride-Operator (CRO)
Der Operator ClusterResourceOverride hilft bei der Optimierung der Ressourcenzuweisung, um eine effiziente und ausgewogene Nutzung im gesamten Cluster sicherzustellen.
Beispielkonfiguration:
- Angeforderte CPU: 100 Millicores (0,1 Kerne)
- Angeforderter Speicher: 200 MiB (Megabyte)
- CPU-Limit: 200 Millicores (0,2 Kerne)
- Speicherlimit: 400 MiB
Overrides:
- CPU Request Override: 50 % der Anforderung
- Memory Request Override: 75 % der Anforderung
- CPU Limit Override: 2-fache Anforderung
- Memory Limit Override: 2-fache Anforderung
Bereinigte Ressourcen:
- Angeforderte CPU: 100 Millicores × 50 % = 50 Millicores (0,05 Kerne)
- Angeforderter Speicher: 200 MiB × 75 % = 150 MiB
- CPU-Limit: 50 Millicores × 2 = 100 Millicores (0,1 Kerne)
- Speicherlimit: 150 MiB × 2 = 300 MiB
Weitere Details finden Sie unter Überlastung auf Cluster-Ebene mit dem Cluster Resource Override Operator.
Vorteil des Kapazitätsmanagements: Durch das Überschreiben von standardmäßigen Ressourcenanforderungen und -beschränkungen können Sie sicherstellen, dass Ressourcen effizient zugewiesen werden und sowohl eine Unterauslastung als auch eine Überlastung verhindern.
Skalierbarkeitsbereich
Ich stelle mir den Skalierbarkeitsbereich als einen höherdimensionalen Würfel vor. Innerhalb des Bereichs werden Ihre Performance Service Level Objectives (SLO) erreicht und Ihr Red Hat OpenShift Cluster funktioniert reibungslos. Während Sie sich in einer Dimension bewegen, nimmt Ihre Kapazität in anderen Dimensionen ab. Mit dem OpenShift-Dashboard können Sie Ihre grüne Zone (wo Sie sich sicher in der Komfortzone für das Skalieren Ihrer Cluster-Objekte befinden) und rote Zone (über diesen Bereich hinaus sollten Sie die Clusterobjekte nicht skalieren) überwachen.

Weitere Details finden Sie unter Node Metrics Dashboard.
Vorteil im Kapazitätsmanagement: Wenn Sie den Skalierbarkeitsbereich verstehen und innerhalb dieses Bereichs arbeiten, können Sie eine zuverlässige Performance Ihres Clusters bei wechselnden Lasten erreichen. So werden Ressourcenengpässe verhindert und eine konsistente Performance gewährleistet.
Autoskalierung von Pods
Red Hat OpenShift bietet verschiedene Methoden zur automatischen Skalierung von Pods. Wir haben bereits Vertical Pod Autoscaling (VPA) erörtert, aber es gibt auch andere Strategien.
Horizontal Pod Autoscaling (HPA)
HPA skaliert Pods horizontal, indem weitere Replikate hinzugefügt werden. Dies ist nützlich für zustandslose Anwendungen in Produktionsumgebungen, wodurch die Performance und Verfügbarkeit der Anwendungen verbessert werden, indem die Last besser verarbeitet und das Löschen aufgrund von Speichermangel (Out of Memory, OOM) vermieden wird. Weitere Informationen finden Sie unter Automatically scaling pods with the Horizontal Pod Autoscaler.
Autoscaler für benutzerdefinierte Metriken
Hiermit werden Ihre Pods basierend auf benutzerdefinierten Metriken skaliert, die für verschiedene Umgebungen wie Produktion, Test und Entwicklung geeignet sind. Dies verbessert die Verfügbarkeit und Performance von Anwendungen, indem die Überwachung und Skalierung basierend auf spezifischen Druckpunkten erfolgt. Weitere Details finden Sie unter Custom Metrics Autoscaler Operator Überblick.
Vorteil des Kapazitätsmanagements: Die automatische Skalierung auf Basis des Workload-Bedarfs stellt sicher, dass Ihre Anwendungen immer über die erforderlichen Ressourcen verfügen, um unterschiedliche Lasten zu bewältigen, wodurch sowohl die Performance als auch die Ressourceneffizienz verbessert werden.
OpenShift Scheduler
Das LowNodeUtilization-Profil des OpenShift-Schedulers verteilt Pods gleichmäßig auf Knoten, um eine geringe Ressourcennutzung für jeden Knoten zu erreichen. Zu den Vorteilen zählen:
- Kosteneffizienz in Cloud-Umgebungen, die durch die Minimierung der Anzahl der benötigten Knoten erreicht wird
- Verbesserte Ressourcenzuweisung im Cluster
- Energieeffizienz in Rechenzentren
- Verbesserte Performance zur Verhinderung einer Knotenüberlastung
- Verhindern von Ressourcenengpässen durch Balancing von Workloads
Weitere Details finden Sie unter Scheduling pods using a scheduler profile.
Vorteil des Kapazitätsmanagements: Durch die Sicherstellung einer gleichmäßigen Ressourcenverteilung hilft der Scheduler, Hotspots und nicht ausreichend ausgelastete Knoten zu vermeiden. Dies führt zu einem ausgewogeneren und effizienteren Cluster.
OpenShift Descheduler
Das Profil AffinityAndTaints schließt Pods aus, die die Inter-Pod-Anti-Affinität, Knotenaffinität und Knoten-Taints verletzen. Zu den Vorteilen zählen:
- Korrigieren einer suboptimalen Pod-Platzierung
- Erzwingen von Knotenaffinitäten und -anti-Affinitäten
- Reaktion auf Knoten-Taint-Änderungen, um sicherzustellen, dass nur kompatible Pods auf dem Knoten verbleiben
Weitere Details finden Sie unter Evicting pods using the Descheduler
Vorteil des Kapazitätsmanagements: Der Descheduler hilft dabei, eine optimale Pod-Platzierung im Zeitverlauf beizubehalten, sich an Änderungen im Cluster anzupassen und eine effiziente Nutzung von Ressourcen unter Berücksichtigung von Affinitäts- und Taint-Beschränkungen zu gewährleisten.
Indem Sie diese Best Practices befolgen und die in OpenShift verfügbaren Tools verwenden, können Sie Kapazität und Überlastung effektiv verwalten und so sicherstellen, dass Ihre Anwendungen reibungslos und effizient ausgeführt werden.
Red Hat Advanced Cluster Management Right Sizing (RHACM)
Red Hat Advanced Cluster Management for Kubernetes Right Sizing ist jetzt als erweiterte Preview für Entwicklerinnen und Entwickler verfügbar. Das Ziel von RHACM Right Sizing besteht darin, Plattform Engineering-Teams Empfehlungen auf CPU- und speicherbasierter Namespace-Ebene zu geben. RHACM Right Sizing wird derzeit von Prometheus-Aufzeichnungsregeln unterstützt, sodass Sie Maximal- und Spitzenwertlogik über verschiedene Aggregationszeiträume (1, 2, 5, 10, 30, 60 und 90 Tage) anwenden können.
Zu den Vorteilen der Verwendung von RHACM Right Sizing gehören:
- Identifizieren der größten Ressourcenverschwender (wie etwa Bereiche, die zu einer Unterauslastung führen)
- Fördern der Transparenz in Ihrem Unternehmen und Aufnahme relevanter Kommunikation
- Verbessertes Flottenmanagement durch RHACM durch Kosteneffizienz und Ressourcenoptimierung, unabhängig davon, wie viele gemanagte Cluster Sie bereitstellen müssen
- Vereinfachte Benutzernavigation in einem dedizierten Grafana-Dashboard – als Teil der RHACM-Konsole
Vorteil des Kapazitätsmanagements: Mit den RHACM Right Sizing-Funktionen können Plattform-Engineers auf CPU- und speicherbasierte Empfehlungen zur geeigneten Größe zugreifen, die in einem dedizierten Grafana-Dashboard – Teil der Konsole von Red Hat Advanced Cluster Management for Kubernetes – angezeigt werden und Nutzenden basierend auf verschiedenen Aggregationszeiträumen den Zugriff auf wichtige Empfehlungen ermöglichen. Die schließt längere Zeiträume ein, da die Nutzung im Zeitverlauf variiert. So werden diese Empfehlungen benutzerfreundlich und leicht umsetzbar (siehe folgende Abbildungen).
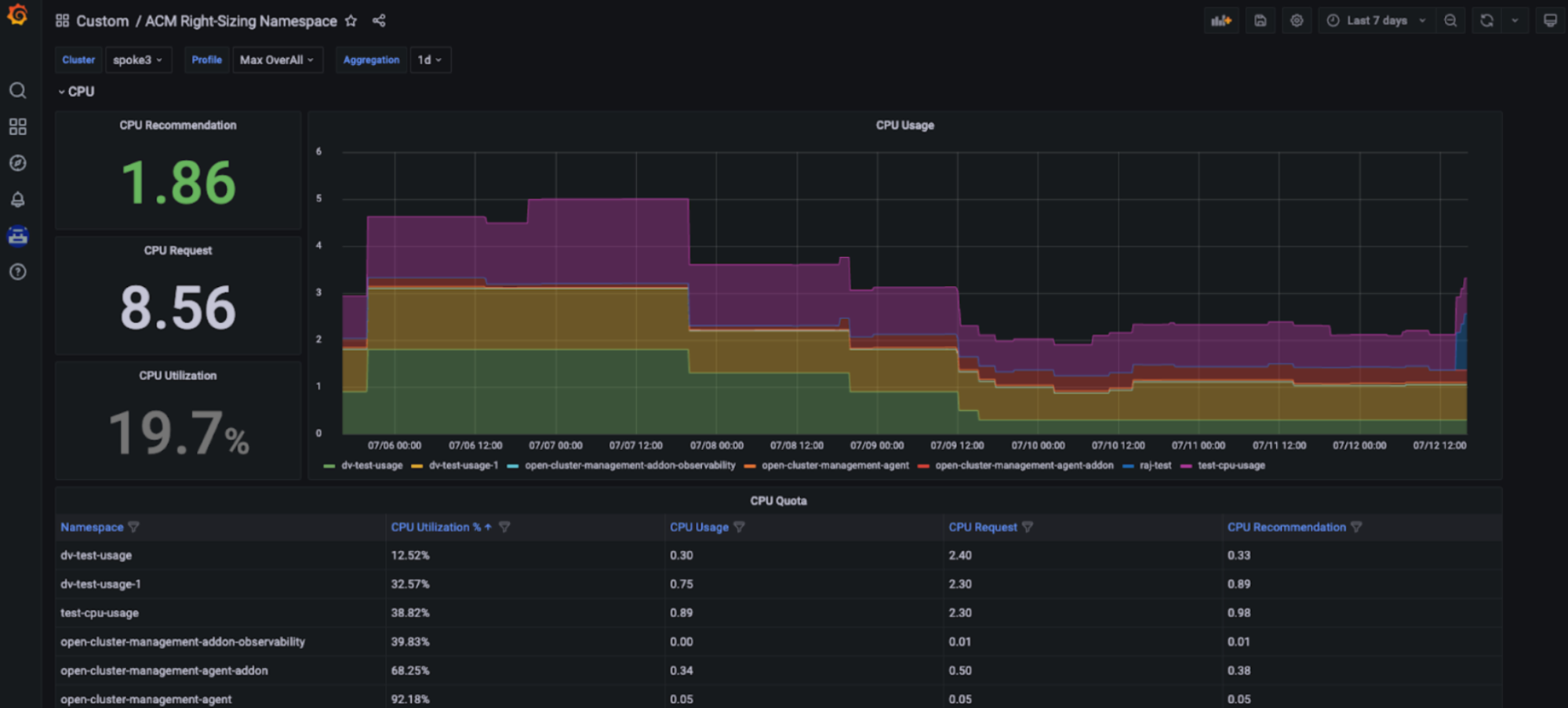
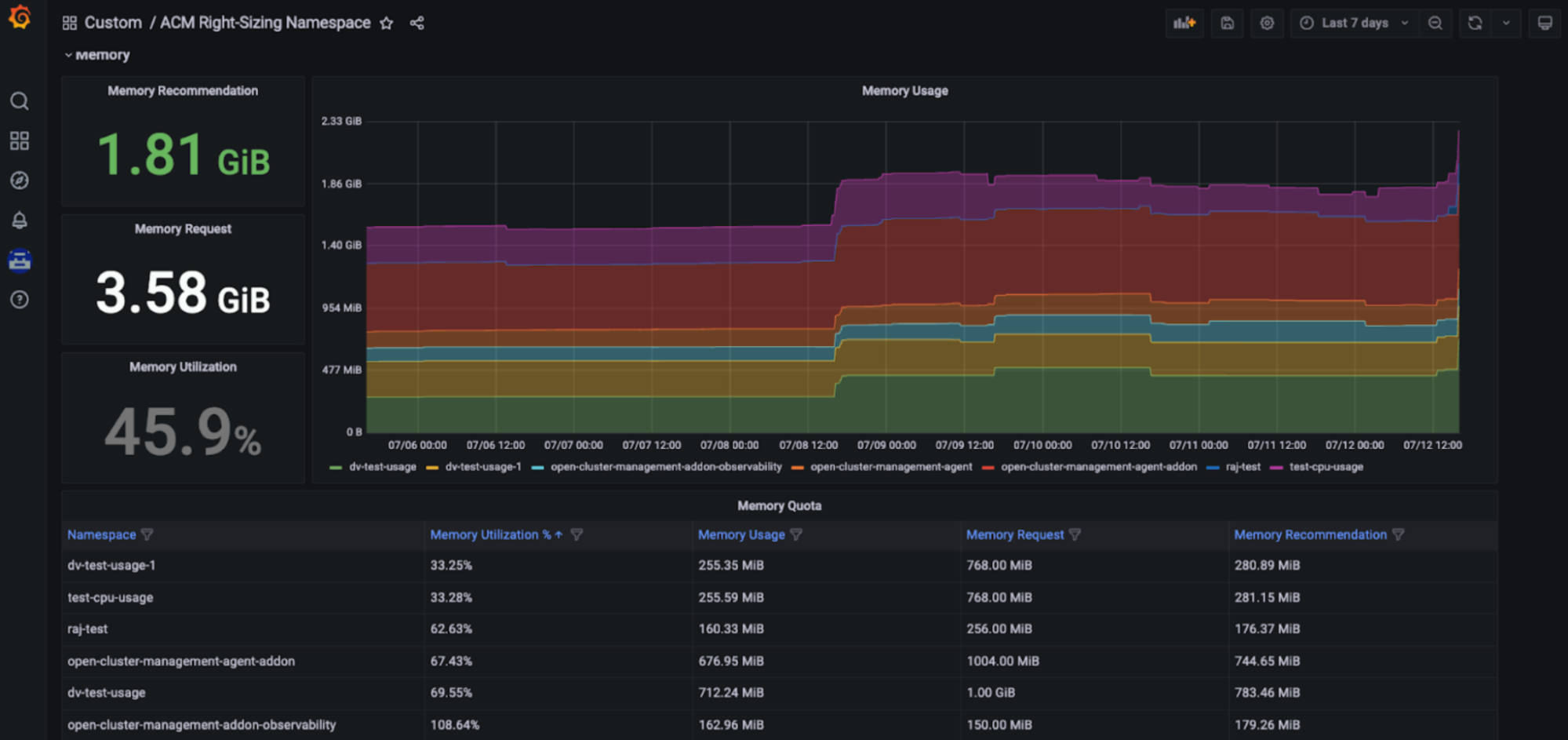
Einrichtung
Weitere Details zu Voraussetzungen und Installationsschritten finden Sie in unserem speziellen Blog. Das folgende GitHub-Repo kann ebenfalls verwendet werden. Während wir auf eine Technologievorschau hinarbeiten, prüfen wir auch, ob auf verschiedenen Ebenen Empfehlungen gegeben werden können. Im Gegensatz zur Funktion zur Ressourcenoptimierung in Insights Cost Management (siehe unten) ist die richtige RHACM-Dimensionierung eine Lösung, bei der keine Analysedaten mit Red Hat geteilt werden müssen.
Ressourcenoptimierung für OpenShift mithilfe des Kostenmanagements von Red Hat Insights
Definition
Red Hat Insights Cost Management ist unsere SaaS-Lösung und bietet eine zentrale Übersicht für Ihre Cloud- und OpenShift-Ausgaben, einschließlich On-Premise.Die
Ressourcenoptimierung für OpenShift, die Teil des Kostenmanagements von Red Hat Insights ist, ist seit kurzem allgemein verfügbar. Das Ziel der Funktion zur Ressourcenoptimierung in Red Hat Insights besteht darin, Entwicklungsteams spezifische, umsetzbare Empfehlungen für CPU und Speicher zu geben. Diese Funktion wird vom Open Source-Projekt Kruize unterstützt.
Vorteile
Die Ressourcenoptimierung für OpenShift bietet Entwicklungsteams Empfehlungen auf Containerebene, einschließlich Container, Deployments, Deploymentconfigs, Statefulsets und Replicasets.
Es werden zwei Gruppen von Empfehlungen generiert:
- Kostenempfehlungen Beachten Sie diese Empfehlungen, wenn Sie Kosten sparen oder die Nutzung Ihrer Cluster maximieren möchten, indem Sie die Namespace-Quotas, Knotengrößen oder Anzahl der Knoten anpassen.
- Empfehlungen für die Performance Beachten Sie diese Empfehlungen, wenn Sie Ihre Anwendungen so leistungsfähig machen wollen, wie es die Hardware zulässt.
Derzeit werden beide Arten von Empfehlungen in drei Zeitrahmen generiert: auf Grundlage von 24 Stunden Beobachtungszeit, auf Grundlage von 7 Beobachtungstagen und basierend auf 15 Beobachtungstagen.
Durch die Ressourcenoptimierung für OpenShift über das Kostenmanagement von Red Hat Insights generierte Empfehlungen können Sie Kosten sparen und für eine optimale Performance Ihrer Anwendung sorgen. Außerdem können Sie diese Empfehlungen zusammen mit den monetären Kosten der Workload im Kontext sehen.
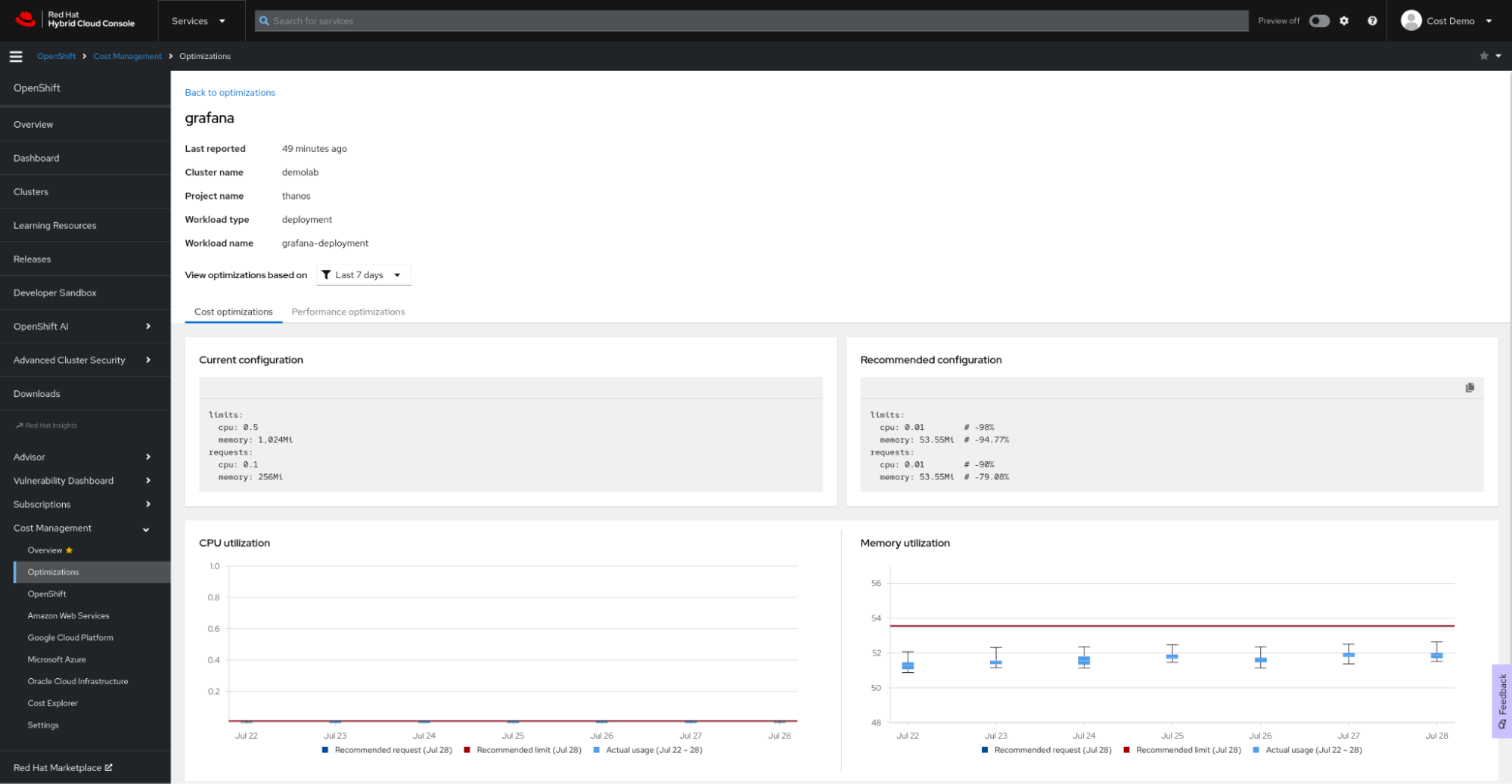
Einrichtung
Ein weiteres Feature des Kostenmanagements von Red Hat Insights ist die Ressourcenoptimierung für OpenShift. Beachten Sie das Red Hat Insights Kostenmanagement-Merkblatt zur Einrichtung und nutzen Sie unsere umfassende Kostenmanagement-API zur Erstellung Ihres eigenen Dashboards in Ihrem bevorzugten Business Intelligence- oder Visualisierungstool wie Microsoft Excel, Power BI oder Grafana. Es ist keine komplexe Konfiguration oder die Zuweisung teurer Ressourcen für die Verarbeitung erforderlich: Der Cost Management Metrics Operator sendet Ihre Nutzungsdaten zur Analyse an die Red Hat Hybrid Cloud Console und generiert Kosten- und Ressourcen-Insights für Sie (falls Ihre Cluster nicht mit dem Internet verbunden sind, lesen Sie unsere Dokumentation zum isolierten Modus).
Über die Autoren


Vanessa is a Senior Product Manager in the Observability group at Red Hat, focusing on both OpenShift Analytics and Observability UI. She is particularly interested in turning observability signals into answers. She loves to combine her passions: data and languages.

Pau Garcia Quiles joined Red Hat in 2021 as Principal Product Manager. He has 20 years of experience in IT in various roles, both as a vendor and as a customer, systems administrator, software developer and project manager. He has been involved in open source for more than 15 years, most notably as a Debian maintainer, KDE developer and Uyuni developer.
Mehr davon
Nach Thema durchsuchen

Automatisierung
Das Neueste zum Thema IT-Automatisierung für Technologien, Teams und Umgebungen

Künstliche Intelligenz
Erfahren Sie das Neueste von den Plattformen, die es Kunden ermöglichen, KI-Workloads beliebig auszuführen

Open Hybrid Cloud
Erfahren Sie, wie wir eine flexiblere Zukunft mit Hybrid Clouds schaffen.

Sicherheit
Erfahren Sie, wie wir Risiken in verschiedenen Umgebungen und Technologien reduzieren

Edge Computing
Erfahren Sie das Neueste von den Plattformen, die die Operations am Edge vereinfachen

Infrastruktur
Erfahren Sie das Neueste von der weltweit führenden Linux-Plattform für Unternehmen

Anwendungen
Entdecken Sie unsere Lösungen für komplexe Herausforderungen bei Anwendungen
Virtualisierung
Erfahren Sie das Neueste über die Virtualisierung von Workloads in Cloud- oder On-Premise-Umgebungen