La gestión de la capacidad y la sobreasignación en Red Hat OpenShift parece compleja, pero comprender algunos conceptos clave simplifica la tarea. A continuación, explicaremos lo que necesitas saber sobre las solicitudes de los pods, los límites y las prácticas recomendadas para establecerlos, junto con la forma en que cada tema contribuye a la gestión eficaz de la capacidad y la sobreasignación.
Solicitud de los pods
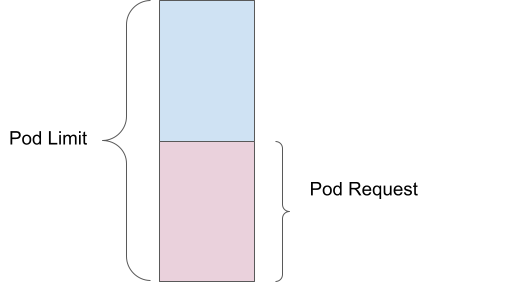
Una solicitud de pod corresponde a la cantidad de recursos informáticos (como la memoria o la CPU) que especificas como el mínimo requerido para que se ejecute tu contenedor. Por ejemplo, si estableces una solicitud de memoria de 1 GiB, el programador garantiza que haya al menos esa cantidad de memoria disponible para tu pod antes de colocarlo en un nodo.
Ventaja de la gestión de la capacidad: garantiza que los recursos esenciales se reserven para cada pod, lo que evita la escasez de recursos y asegura que todos los pods tengan la cantidad mínima que necesitan para funcionar de manera eficiente.
Límite de los pods
Por otro lado, el límite es la cantidad máxima de recursos que tu pod puede usar. Si estableces un límite de memoria de 2 GiB, el pod puede utilizar hasta esa cantidad, pero no más. El kernel aplica esto a través de grupos de control, lo que ayuda a evitar que un solo pod consuma demasiados recursos y afecte a otros.
Ventaja de la gestión de la capacidad: evita que los pods individuales utilicen demasiados recursos, lo que garantiza una distribución justa en todos los pods en ejecución.
Sobreasignación
La sobreasignación ocurre cuando el límite supera la solicitud. Por ejemplo, si un pod tiene una solicitud de memoria de 1 GiB y el límite es de 2 GiB, se programa en función de la cantidad solicitada, pero puede usar hasta la cantidad que se definió como límite. Esto significa que el pod está sobreasignado en un 200 %, ya que puede usar el doble de la cantidad de memoria que estaba garantizada.
Ventaja de la gestión de la capacidad: permite un uso más eficiente de los recursos del clúster al permitir que los pods usen recursos adicionales cuando estén disponibles, sin garantizarlos previamente.
Consecuencias de no establecer solicitudes y límites
Las solicitudes y los límites permiten que la instancia de Red Hat OpenShift se ejecute de manera eficiente y predecible. Cuando no los defines, hay consecuencias.
Falta de recursos garantizados
Si no estableces solicitudes de recursos, el programador no garantiza ninguna cantidad específica de CPU o memoria para los pods. Esto puede afectar el rendimiento o hacer que el pod deje de funcionar correctamente cuando el nodo está sometido a una gran carga.
Falta de límites en el uso de recursos
Sin límites, un contenedor puede usar toda la CPU y la memoria que necesite, lo cual podría generar una escasez de recursos, donde un contenedor usa todos los que están disponibles y esto hace que otros contenedores fallen o se eliminen.
Ventaja de la gestión de la capacidad: el establecimiento de las solicitudes y los límites garantiza una asignación de los recursos equilibrada, que evita tanto la preparación deficiente (falta de recursos) como la preparación excesiva (acaparamiento de recursos).
Prácticas recomendadas para establecer solicitudes y límites
En general, hay cinco prácticas recomendadas que se deben seguir al establecer solicitudes y límites:
- establecer siempre las solicitudes de memoria y CPU;
- evitar definir límites de CPU, ya que puede generar restricciones que afecten el rendimiento;
- supervisar la carga de trabajo; establecer las solicitudes según el uso promedio a lo largo del tiempo;
- definir los límites de la memoria como un multiplicador de la solicitud;
- usar el adaptador automático vertical de pods (VPA) para ajustar estos valores a lo largo del tiempo.
Ventaja de la gestión de la capacidad: estas prácticas garantizan que cada pod obtenga los recursos que necesita y evita la asignación excesiva, lo que permite utilizar los recursos de manera eficiente y mejorar el rendimiento del clúster.
Uso del adaptador automático vertical de pods para ajustar los recursos
El elemento VPA de Red Hat OpenShift ajusta la cantidad de CPU y memoria que se asigna a un pod cuando este requiere más recursos. Cuando uses el VPA, debes:
- instalar y configurar el VPA solo en modo recomendación;
- ejecutar simulaciones de carga reales en los pods;
- controlar los valores recomendados y ajustar los recursos del pod según corresponda.
¿Por qué conviene usar solo el modo recomendación?
Si configuras el VPA en el modo automático, los pods se reinician para ajustarse a los valores recomendados. El VPA con ajustes sin reinicio está en la versión alfa, a partir de Red Hat OpenShift 4.16.
Ajuste del tiempo de visualización para los sistemas de recomendación
El VPA admite sistemas de recomendaciones personalizados, lo que te permite establecer tiempos de visualización de un día, una semana o un mes, según tus necesidades. Para obtener más información, lee Automatically adjust pod resource levels with the vertical pod autoscaler.
Ventaja de la gestión de la capacidad: el VPA ayuda al ajustar las solicitudes de recursos y los límites de manera dinámica en función de los patrones de uso reales. Esto garantiza una asignación de recursos óptima y disminuye la sobreasignación.
Recursos reservados del sistema en Red Hat OpenShift
Un recurso se puede designar como reservado para el sistema. Es decir que Red Hat OpenShift asigna una parte de los recursos del nodo (CPU y memoria) para los procesos del sistema, como el tiempo de ejecución de los contenedores y kubelet. Gracias a esto, se generan muchas ventajas:
- garantía de recursos exclusivos para los procesos del sistema, lo que evita que haya conflictos con las cargas de trabajo de las aplicaciones;
- mayor estabilidad y mejor rendimiento de los nodos, ya que se evita la escasez de recursos para los servicios esenciales del sistema;
- funcionamiento confiable y un rendimiento predecible del clúster.
Puedes habilitar la asignación automática de recursos para los nodos siguiendo las instrucciones para los clústeres de OpenShift autogestionados de la documentación. Una instancia de OpenShift gestionada, como Red Hat OpenShift Service on AWS (ROSA), se encarga de administrarlos.
Ventaja de la gestión de la capacidad: la asignación de recursos para los procesos del sistema garantiza que los servicios esenciales se ejecuten sin problemas, lo que evita que se generen interrupciones en el rendimiento de las aplicaciones a causa de conflictos con los recursos.
Ajuste automático de los clústeres
El ajuste automático de clústeres agrega o elimina nodos automáticamente según sea necesario. Esto funciona junto con el adaptador automático horizontal de pods (HPA). Para obtener más información, lee la guía del adaptador automático de clústeres de OpenShift y la documentación de OpenShift sobre el adaptador automático.
Ventaja de la gestión de la capacidad: el adaptador automático garantiza que el clúster tenga la cantidad correcta de nodos para gestionar la carga de trabajo actual y se amplía o se reduce automáticamente según sea necesario. Gracias a esto, se optimiza el uso de los recursos y aumenta la rentabilidad.
Operador ClusterResourceOverride
El operador ClusterResourceOverride (CRO) ayuda a optimizar la asignación de recursos para garantizar un uso eficiente y equilibrado en todo el clúster.
Ejemplo de configuración:
- CPU solicitada: 100 milicores (0,1 núcleos)
- Memoria solicitada: 200 MiB (mebibytes)
- Límite de CPU: 200 milicores (0,2 núcleos)
- Límite de memoria: 400 MiB
Anulaciones:
- Anulación de la solicitud de la CPU: el 50 % de lo que se solicitó
- Anulación de la solicitud de memoria: el 75 % de lo que se solicitó
- Anulación del límite de la CPU: el doble de la solicitud
- Anulación del límite de la memoria: el doble de la solicitud
Recursos ajustados:
- CPU solicitada: 100 milicores × 50 % = 50 milicores (0,05 núcleos)
- Memoria solicitada: 200 MiB × 75 % = 150 MiB
- Límite de la CPU: 50 milicores × 2 = 100 milicores (0,1 núcleos)
- Límite de la memoria: 150 MiB × 2 = 300 MiB
Para obtener más información, lee Cluster-level overcommit using the Cluster Resource Override Operator.
Ventaja de la gestión de la capacidad: al anular las solicitudes y los límites de los recursos predeterminados, puedes asegurarte de que los recursos se asignen de manera eficiente, lo que evita el desaprovechamiento y la sobreasignación.
Límite de la capacidad de ajuste
Imaginemos al límite de la capacidad de ajuste como un cubo de dimensiones superiores. Si te mantienes dentro de los límites establecidos, alcanzarás los objetivos de rendimiento del nivel de servicio (SLO), y el clúster de Red Hat OpenShift funcionará sin problemas. A medida que avanzas en una dimensión, disminuye tu capacidad en otras dimensiones. Puedes usar el panel de OpenShift para controlar tu área verde (donde estás dentro de la zona de confort para ajustar los objetos del clúster) y el área roja (más allá de la cual no debes ajustar los objetos del clúster).

Para obtener más información, lee Node metrics dashboard.
Ventaja de la gestión de la capacidad: si comprendes los límites de la capacidad de ajuste y operas dentro de ellos, podrás asegurarte de que el clúster funcione de manera confiable con cargas variables, lo que evita los bloqueos de recursos y garantiza un rendimiento uniforme.
Ajuste automático de los pods
Hay varios métodos de ajuste automático de pods en Red Hat OpenShift. Ya hablamos sobre el adaptador automático vertical de pods, pero también hay otras estrategias.
Adaptador automático horizontal de pods
El HPA ajusta los pods horizontalmente agregando más réplicas. Esto es útil para aplicaciones sin estado en entornos de producción, ya que mejora el rendimiento y el tiempo de actividad al gestionar mejor la carga y evitar las eliminaciones por falta de memoria (OOM). Para obtener más información, lee Automatically scaling pods with the horizontal pod autoscaler.
Ajuste automático de indicadores personalizados
Los pods se adaptan según los indicadores definidos por el usuario, adecuados para diversos entornos, como los de producción, de pruebas y de desarrollo. Esto mejora el tiempo de actividad y el rendimiento de las aplicaciones mediante la supervisión y el ajuste que se define según problemas específicos. Para obtener más información, lee Custom Metrics Autoscaler operator overview.
Ventaja de la gestión de la capacidad: el ajuste automático que se basa en la demanda de la carga de trabajo garantiza que las aplicaciones siempre tengan los recursos necesarios para gestionar cargas variables, lo que mejora el rendimiento y la eficiencia.
Programador de OpenShift
El perfil LowNodeUtilization del programador de OpenShift distribuye los pods de manera uniforme entre los nodos para lograr que los recursos se usen poco en cada uno. Estas son algunas de las ventajas que ofrece:
- rentabilidad en los entornos de nube gracias a la reducción de la cantidad de nodos necesarios;
- mejora de la asignación de recursos en todo el clúster;
- eficiencia energética en los centros de datos;
- rendimiento mejorado al evitar la sobrecarga de los nodos;
- equilibrio de las cargas de trabajo para evitar la escasez de recursos.
Para obtener más información, lee Scheduling pods using a scheduler profile.
Ventaja de la gestión de la capacidad: al garantizar una distribución uniforme de los recursos, el programador ayuda a evitar las zonas sobrecargadas y los nodos desaprovechados, lo que genera un clúster más equilibrado y eficiente.
Desprogramador de OpenShift
El perfil AffinityAndTaints elimina los pods que no cumplen con la antiafinidad entre pods ni con la afinidad y los taints de los nodos. Estas son algunas de las ventajas que ofrece:
- corrección de la ubicación poco eficiente de los pods;
- aplicación de afinidades y antiafinidades de nodos;
- respuesta a los cambios del taint del nodo para garantizar que solo los pods compatibles permanezcan en el nodo.
Para obtener más información, lee Evicting pods using the descheduler.
Ventaja de la gestión de la capacidad: el desprogramador ayuda a mantener la ubicación óptima de los pods a lo largo del tiempo, lo que permite adaptarse a los cambios en el clúster y garantizar el uso eficiente de los recursos, mientras se respetan los límites de afinidad y taint.
Si sigues estas prácticas recomendadas y usas las herramientas disponibles en OpenShift, podrás gestionar de manera efectiva la capacidad y la sobreasignación, lo que garantiza que las aplicaciones se ejecuten sin problemas y con eficiencia.
Ajuste de Red Hat Advanced Cluster Management
El ajuste de Red Hat Advanced Cluster Management for Kubernetes (RHACM) ya está disponible como versión de prueba mejorada para los desarrolladores. El objetivo es proporcionar a los equipos de ingeniería de plataformas recomendaciones de espacio de nombres que se basan en la memoria y la CPU. Actualmente, funciona con las reglas de registro de Prometheus, lo que le permite aplicar la lógica de valores máximos en diferentes períodos de agregación (1, 2, 5, 10, 30, 60 y 90 días).
Las ventajas de usar el ajuste de RHACM incluyen:
- identificación de los principales consumidores de recursos (por ejemplo, las áreas que causan el desaprovechamiento);
- fomento de la transparencia en toda la empresa y de conversaciones relevantes;
- mejora de la gestión de la flota con RHACM, lo que posibilita la rentabilidad y la optimización de los recursos, independientemente de la cantidad de clústeres gestionados que necesites implementar;
- navegación simplificada del usuario que se proporciona en un panel de Grafana exclusivo, como parte de la consola de RHACM.
Ventaja de la gestión de la capacidad: Las funciones del ajuste de RHACM permiten a los ingenieros de plataformas acceder a las recomendaciones de ajuste que se basan en la CPU y la memoria y se muestran en un panel exclusivo de Grafana, parte de la consola de Red Hat Advanced Cluster Management for Kubernetes. Esto posibilita que los usuarios accedan a las recomendaciones clave que se basan en varios períodos de agregación, como los marcos de tiempo más largos, ya que el uso varía a largo plazo. Por lo tanto, esas recomendaciones son fáciles de usar y de aplicar (consulta las siguientes figuras).
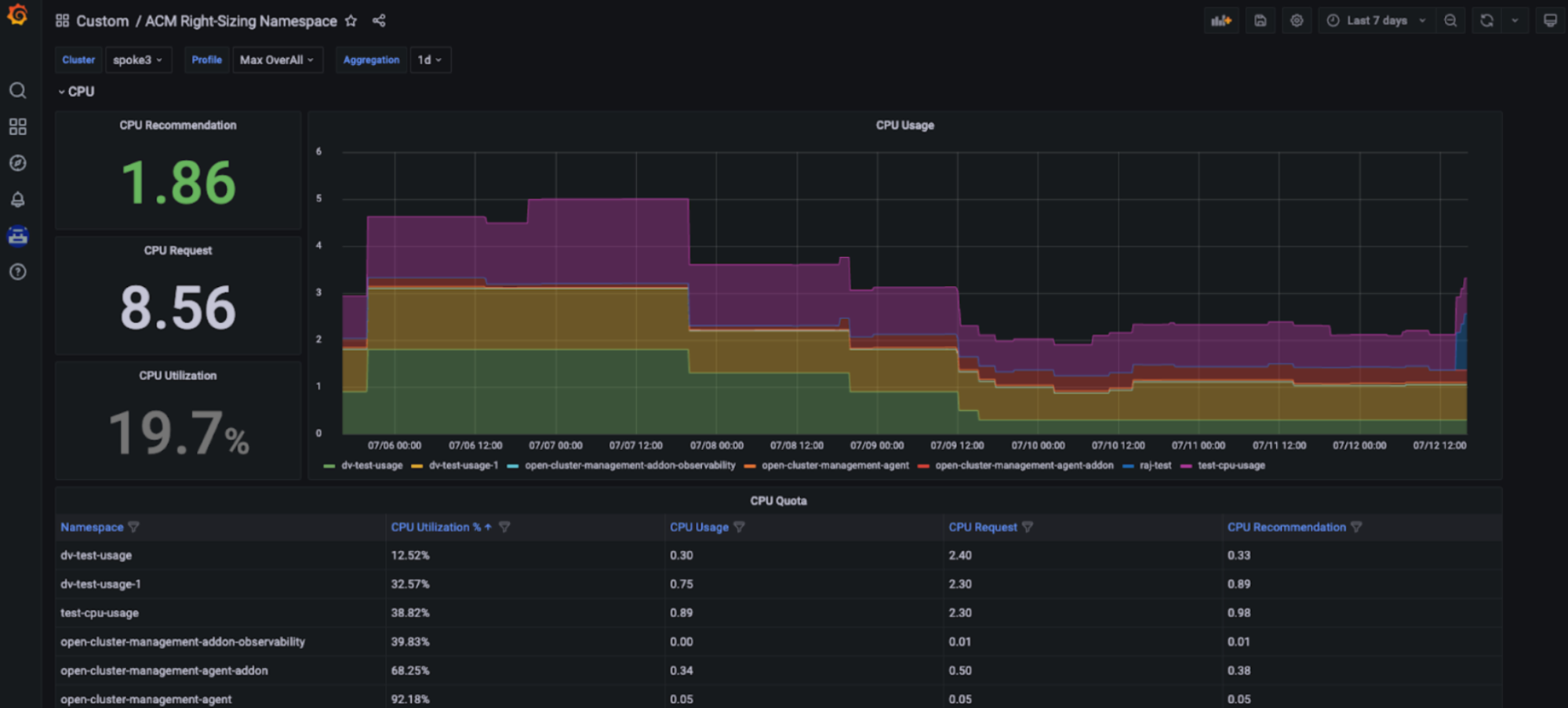
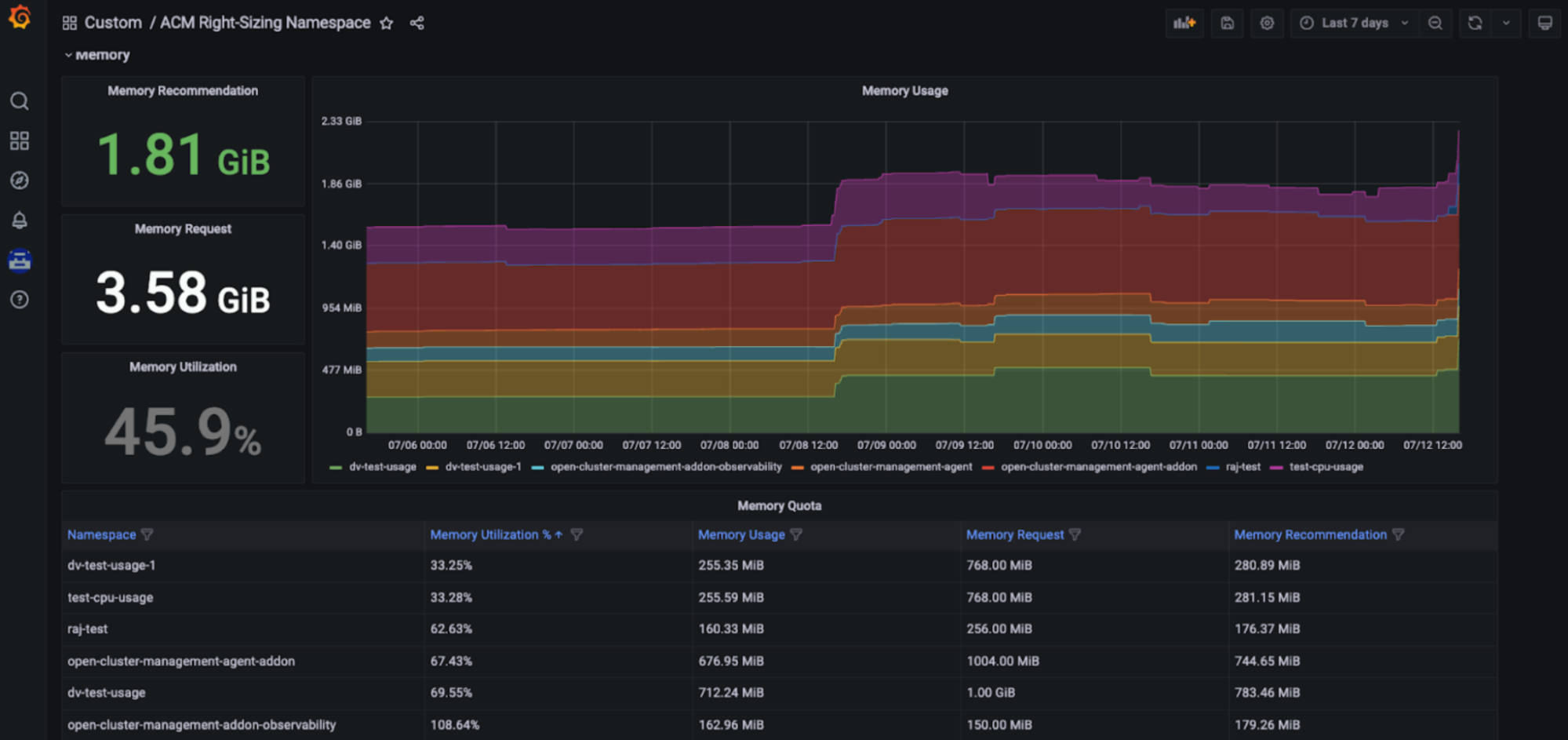
Configuración
Para obtener más información sobre los requisitos previos y los pasos de instalación, consulta nuestro blog exclusivo. También puedes acceder a este repositorio de GitHub. Mientras trabajamos para lanzar una versión de prueba, también evaluamos la posibilidad de ofrecer recomendaciones en diferentes niveles. A diferencia de la función de optimización de recursos de gestión de costos de Red Hat Insights (se define a continuación), el ajuste de RHACM es una solución que no requiere compartir los análisis de datos con Red Hat.
Optimización de recursos para OpenShift con la gestión de costos de Red Hat Insights
Definición
La gestión de costos de Red Hat Insights es nuestra solución de software como servicio (SaaS) que ofrece un panel único para todos tus gastos en la nube y en OpenShift, que incluye las instalaciones.
Recientemente, la optimización de recursos de OpenShift, parte de la gestión de costos de Red Hat Insights, llegó al público en general. El objetivo de la función de optimización de recursos de Red Hat Insights es proporcionar a los equipos de desarrollo recomendaciones para la CPU y la memoria que sean específicas y aplicables. Esta función se basa en el proyecto open source Kruize.
Beneficios
La optimización de recursos de OpenShift proporciona a los desarrolladores recomendaciones relacionadas con los contenedores, incluidas recomendaciones para las implementaciones y los controladores deploymentconfigs, statefulsets y replicasets.
Se generan dos conjuntos:
- Recomendaciones de costos. Consúltalas cuando desees ahorrar dinero o aprovechar al máximo el uso de los clústeres ajustando las cuotas de los espacios de nombres y la cantidad de nodos o sus tamaños.
- Recomendaciones de rendimiento. Revísalas cuando tu prioridad principal sea lograr que las aplicaciones tengan el mismo rendimiento que el hardware.
Actualmente, ambos tipos de recomendaciones se generan en tres períodos: según 24 horas, 7 días y 15 días de observación.
La optimización de los recursos para las recomendaciones de OpenShift que genera la gestión de costos de Red Hat Insights puede ayudarte a ahorrar dinero y mejorar el rendimiento de la aplicación. Además, puedes ver estas recomendaciones en contexto, junto con el costo de la carga de trabajo.
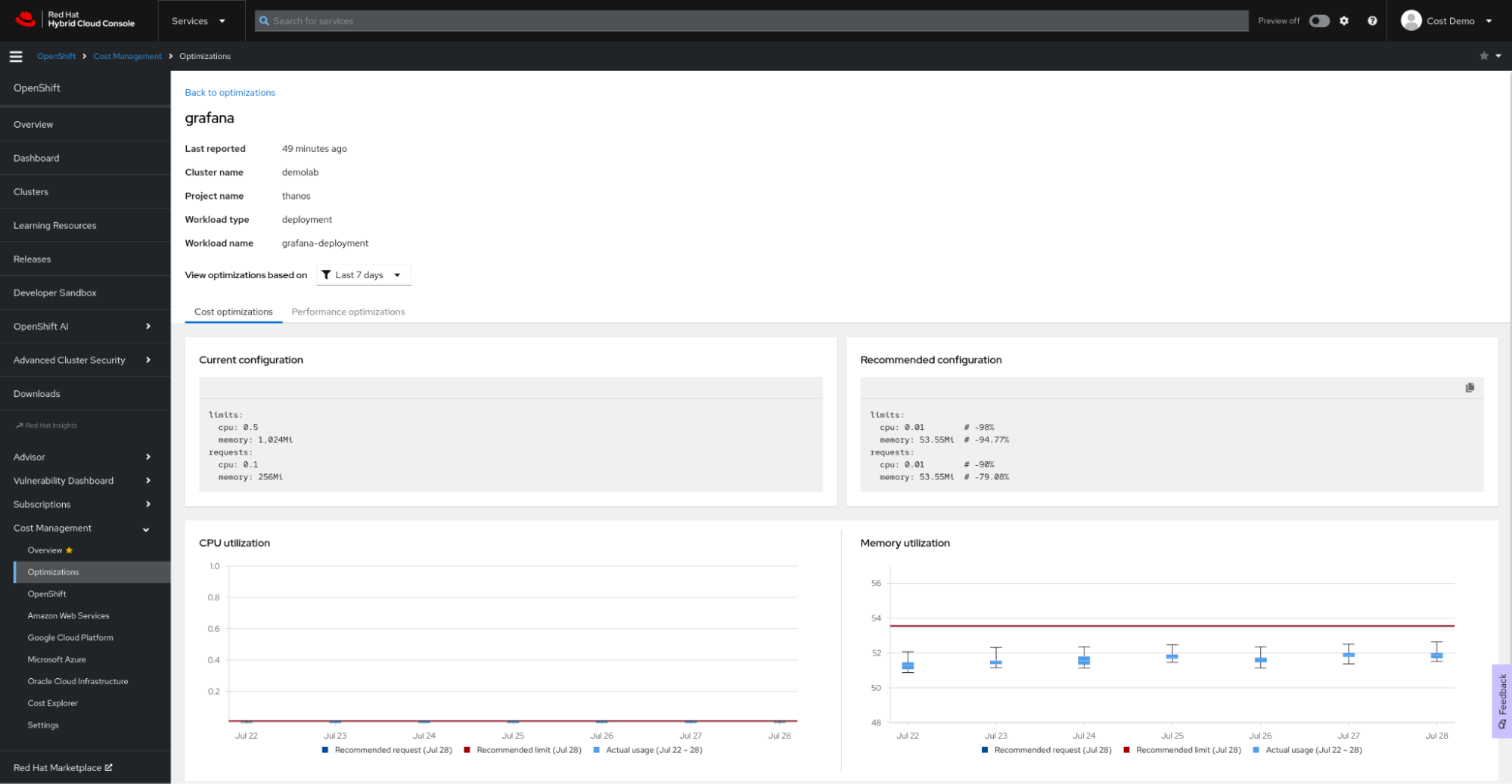
Configuración
La optimización de los recursos para las recomendaciones de OpenShift es otra función de la gestión de costos de Red Hat Insights. Sigue las instrucciones del documento de gestión de costos de Red Hat Insights para configurarla y usa nuestra interfaz de programación de aplicaciones (API) de gestión de costos para crear tu propio panel en la herramienta de inteligencia comercial o visualización que prefieras, como Microsoft Excel, Power BI o Grafana. No es necesario realizar configuraciones complejas ni asignar recursos costosos para el procesamiento. El operador de indicadores de gestión de costos enviará tus datos de uso a Red Hat Hybrid Cloud Console para analizarlos y generará información sobre los costos y los recursos (si tus clústeres no están conectados a Internet, consulta nuestra documentación del modo desconectado).
Sobre los autores


Vanessa is a Senior Product Manager in the Observability group at Red Hat, focusing on both OpenShift Analytics and Observability UI. She is particularly interested in turning observability signals into answers. She loves to combine her passions: data and languages.

Pau Garcia Quiles joined Red Hat in 2021 as Principal Product Manager. He has 20 years of experience in IT in various roles, both as a vendor and as a customer, systems administrator, software developer and project manager. He has been involved in open source for more than 15 years, most notably as a Debian maintainer, KDE developer and Uyuni developer.
Más similar
Navegar por canal

Automatización
Las últimas novedades en la automatización de la TI para los equipos, la tecnología y los entornos

Inteligencia artificial
Descubra las actualizaciones en las plataformas que permiten a los clientes ejecutar cargas de trabajo de inteligecia artificial en cualquier lugar

Nube híbrida abierta
Vea como construimos un futuro flexible con la nube híbrida

Seguridad
Vea las últimas novedades sobre cómo reducimos los riesgos en entornos y tecnologías

Edge computing
Conozca las actualizaciones en las plataformas que simplifican las operaciones en el edge

Infraestructura
Vea las últimas novedades sobre la plataforma Linux empresarial líder en el mundo

Aplicaciones
Conozca nuestras soluciones para abordar los desafíos más complejos de las aplicaciones
Virtualización
El futuro de la virtualización empresarial para tus cargas de trabajo locales o en la nube