Die Integration von Beobachtbarkeitstools mit Automatisierung ist im Bereich moderner IT-Operationen von größter Bedeutung, da sie eine symbiotische Beziehung zwischen Transparenz und Effizienz fördert. Beobachtbarkeitstools bieten detaillierte Insights in die Performance, den Zustand und das Verhalten komplexer Systeme, mit denen Unternehmen Probleme proaktiv identifizieren und beheben können, bevor diese eskalieren.
Wenn diese Tools nahtlos in Automatisierungs-Frameworks integriert sind, können Unternehmen diese nicht nur überwachen, sondern auch in Echtzeit auf dynamische Änderungen reagieren. Mit dieser Synergie zwischen Beobachtbarkeit und Automatisierung können IT-Teams sich schnell an sich ändernde Bedingungen anpassen, Ausfallzeiten minimieren und die Ressourcennutzung optimieren. Durch automatisierte Reaktionen auf Basis von Beobachtbarkeitsdaten können Unternehmen ihre Agilität verbessern, manuelle Eingriffe reduzieren und für eine robuste und resiliente Infrastruktur sorgen. Kurz gesagt, die Kombination aus Beobachtbarkeit und Automatisierung ist für das Schaffen einer proaktiven, reaktionsfähigen und optimierten operativen Umgebung in der schnelllebigen und komplexen Technologielandschaft von heute unabdingbar.
In diesem Blog-Beitrag betrachten wir einen häufigen Use Case, bei dem Prozesse auf Bare Metal und virtuellen Maschinen überwacht werden. Wir konzentrieren uns auf die Nutzung von Dynatrace OneAgent, einer auf Hosts bereitgestellten Binärdatei, die eine Suite spezialisierter Services umfasst, welche sorgfältig für die Überwachung der Umgebung konfiguriert wurden. Diese Services sammeln aktiv Telemetriemetriken und erfassen so Insights zu verschiedenen Aspekten Ihrer Hosts, darunter Hardware, Betriebssysteme und Anwendungsprozesse.
In diesem Use Case besteht unser Ziel darin, einen Monitor auf Hostebene speziell für den NGINX-Webserverprozess einzurichten. Ich führe Sie durch die Implementierung von Event-Driven Ansible, einem Framework, das Event-Quellen durch definierte Regeln mit den entsprechenden Aktionen verknüpft. In dieser Instanz ist Dynatrace die Event-Quelle.
Nach Abschluss der Konfiguration simulieren wir das folgende Szenario:
- Beim NGINX-Webserver kommt es zu einer ungeplanten Ausfallzeit auf dem Server.
- Die von Dynatrace OneAgent ermöglichte Prozessüberwachung erkennt den fehlgeschlagenen NGINX-Prozess umgehend und generiert eine Problemwarnung auf der Dynatrace-Plattform.
- Das Dynatrace-Quellcode-Plugin, das in dem von Event-Driven Ansible verwendeten Rulebook definiert ist, fragt aktiv nach Fehler-Events ab.
- Event-Driven Ansible führt als Reaktion auf das Event ein Job-Template aus, das die folgenden Aktionen durchführt:
- Initiiert die Erstellung eines ServiceNow-Vorfalltickets
- Versucht, den NGINX-Prozess neu zu starten
- Aktualisiert den Status des Vorfalltickets auf „In Bearbeitung“
- Schließt das Tickets nur, wenn der NGINX-Prozess erfolgreich wiederhergestellt wurde
Im folgenden Flussdiagramm werden die Interaktionen zwischen diesen integrierten Komponenten veranschaulicht.
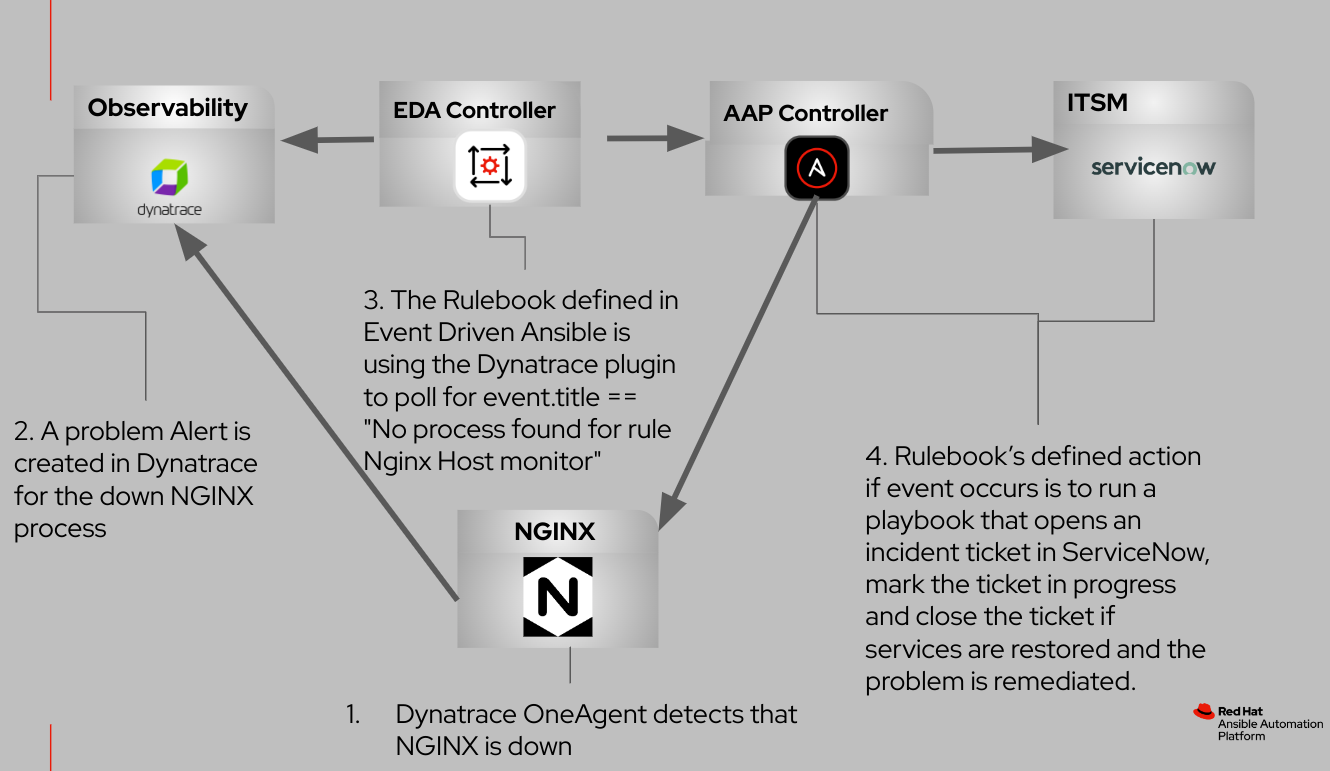
Bevor wir beginnen, machen wir uns mit einigen Begriffen vertraut, die mit den Kernkonzepten von Event-Driven Ansible einhergehen:
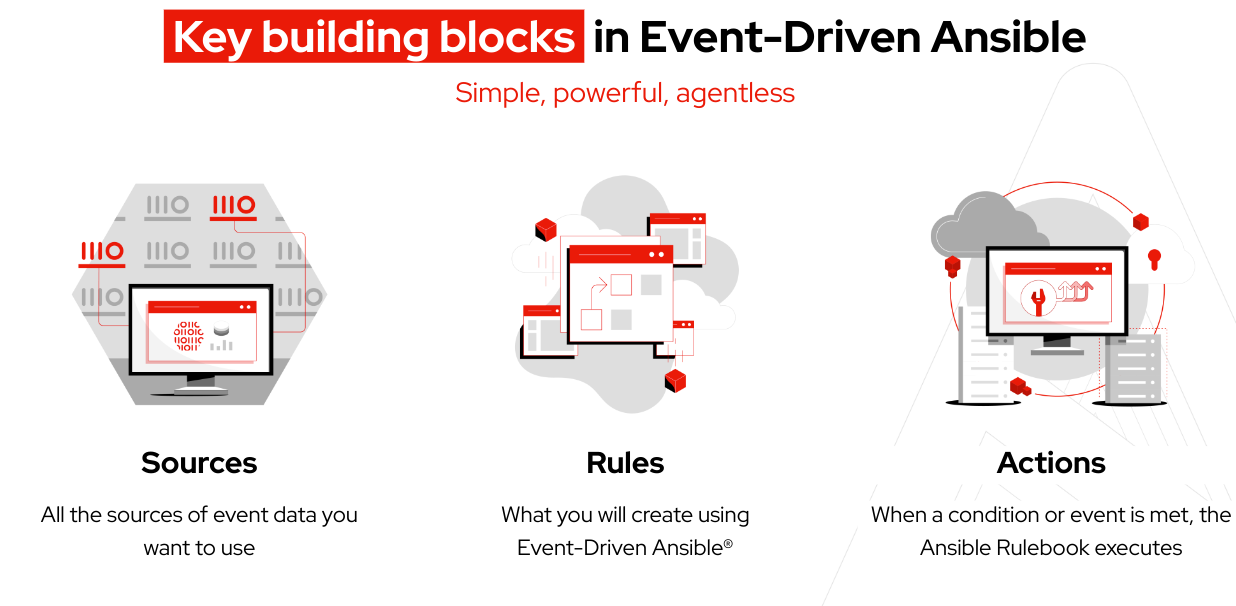
Terminologie:
Ein Ansible Rulebook umfasst sowohl die Event-Quelle als auch detaillierte regelbasierte Anweisungen für die Aktionen, die ausgeführt werden müssen, wenn bestimmte Bedingungen erfüllt sind. So wird ein hohes Maß an Flexibilität erreicht.
Eine Entscheidungsumgebung ist ein Container Image, das zur Ausführung von Ansible Rulebooks entwickelt wurde, die im Event-Driven Ansible Controller verwendet werden.
Plugins für Event-Quellen werden üblicherweise in Python erstellt und dienen dem Zweck, Events aus der angegebenen Event-Quelle zu erfassen. Darüber hinaus werden Plugins über Red Hat Ansible Certified Content Collections verteilt.
Dazu muss eine Entscheidungsumgebung erstellt werden. Siehe folgendes Beispiel der Build-Datei:
---
version: 3
images:
base_image:
name: registry.redhat.io/ansible-automation-platform-24/de-minimal-rhel8:latest
dependencies:
galaxy:
collections:
- ansible.eda
- dynatrace.event_driven_ansible
system:
- pkgconf-pkg-config [platform:rpm]
- systemd-devel [platform:rpm]
- gcc [platform:rpm]
- python39-devel [platform:rpm]
options:
package_manager_path: /usr/bin/microdnfWeitere Anleitungen zum Erstellen von Entscheidungsumgebungen finden Sie in der bereitgestellten Dokumentation. Übertragen Sie nach dem Erstellen Ihrer Entscheidungsumgebung das Container Image in das vorgesehene Image Repository, und laden Sie anschließend das Image in Ihren Event-Driven Ansible Controller herunter.
Mit dem Einrichten Ihrer Entscheidungsumgebung sind Sie kurz davor, eine Regel im Event-Driven Ansible Controller zu aktivieren. Diese Aktivierung umfasst das Rulebook, in dem die Event-Quelle definiert ist, sowie detaillierte Anweisungen zu den Aktionen, die unter bestimmten Bedingungen ausgeführt werden sollen. Ähnlich wie bei der Organisation von Playbooks innerhalb von Projekten in Automation Controller werden auch beim Event-Driven Ansible Controller Projekte verwendet, die unsere Rulebooks verwalten und enthalten.
Nachstehend finden Sie eine Standardverzeichnishierarchie zum Organisieren und Speichern Ihrer Rulebooks und Playbooks in Ihrem Git Repository.
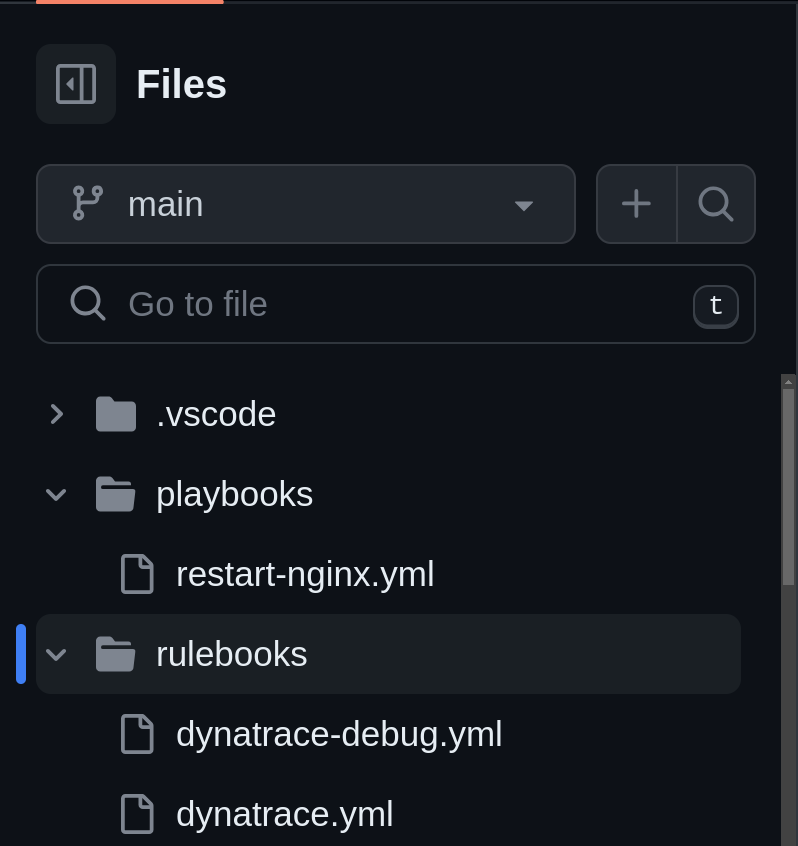
Nachdem wir ein Projekt im Event-Driven Ansible Controller erstellt haben, müssen wir eine Rulebook-Aktivierung erstellen. Hierbei handelt es sich um einen Hintergrundprozess, der durch ein Rulebook definiert wird, das in einer Entscheidungsumgebung ausgeführt wird.
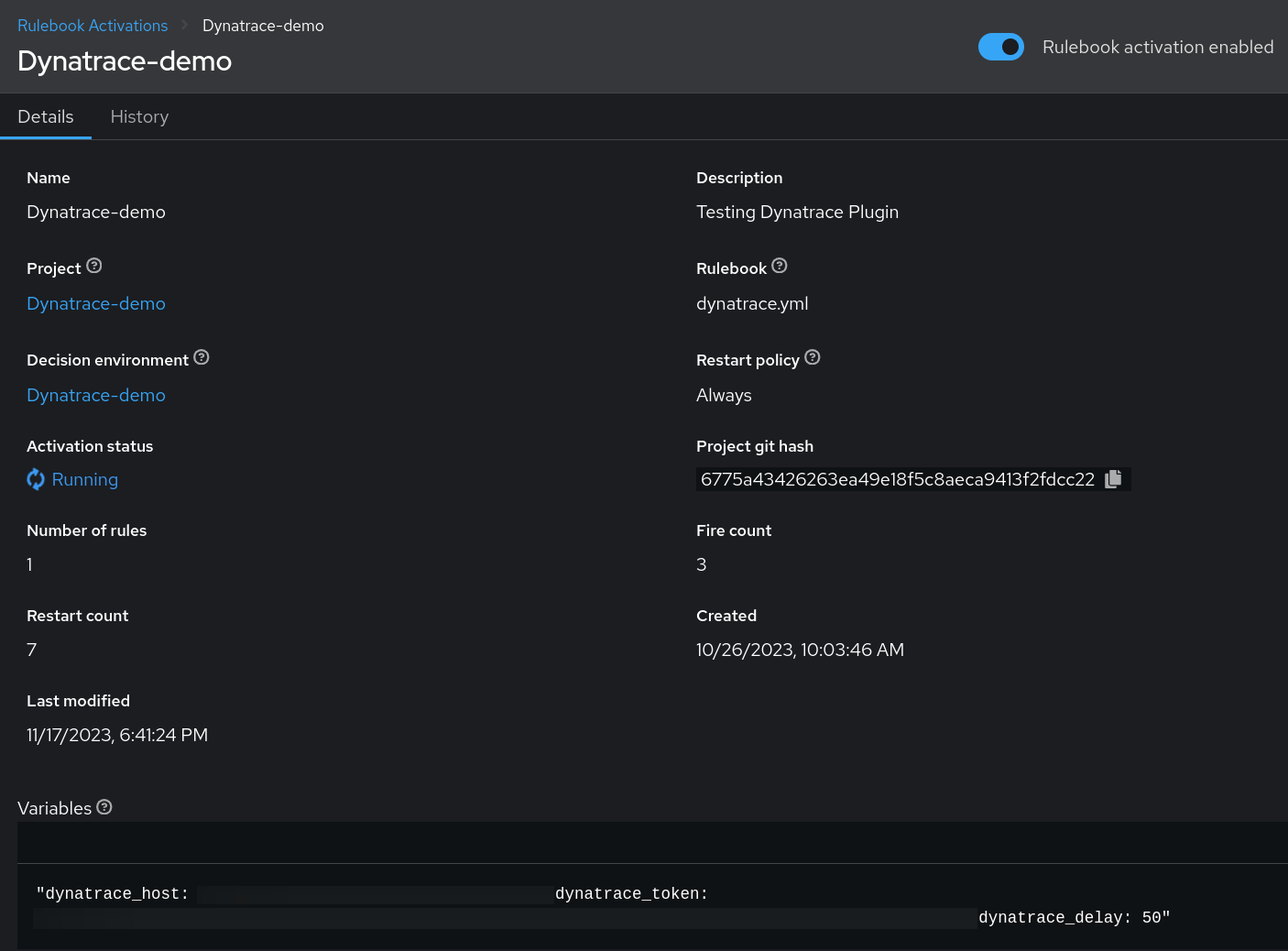
Für diesen Use Case erstellen wir ein Rulebook, das das Dynatrace-Plugin als Ansible-Event-Quelle verwendet, und geben an, welche Aktionen ausgeführt werden sollen, wenn eine Bedingung erfüllt wird.
Im Allgemeinen gibt es 3 Integrationsmuster für Quell-Plugins:
- Polling
- Webhook
- Messaging
In unserem Use Case ruft das Dynatrace-Quellcode-Plugin Events effizient ab, indem es aktiv gemäß den im Rulebook festgelegten Bedingungen aktiv pollt. Dieser Polling-Mechanismus führt eine delay-Variable ein, die zum Dynatrace-Plugin gehört, wie im Rulebook beschrieben (siehe Einstellung der delay-Variable).
Diese Verzögerung (delay) spielt eine wichtige Rolle bei der Regulierung des Plugin-Verhaltens durch die Implementierung eines Throttling-Mechanismus. Im Wesentlichen wird dabei die Ausführung von API-Aufrufen in vordefinierten Intervallen orchestriert, sodass das Plugin basierend auf der empfangenen Antwort ein neues Event generieren kann. Diese bewusste Beschleunigung der API-Aufrufe ist entscheidend für die Verwaltung und Optimierung des gesamten Workflows, um das Risiko von Durchsatzbegrenzungen zu mindern und einen nahtlosen Betrieb des Systems sicherzustellen.
Siehe folgendes Rulebook:
---
- name: Watching for Problems on Dynatrace
hosts: all
sources:
- dynatrace.event_driven_ansible.dt_esa_api:
dt_api_host: "{{ dynatrace_host }}"
dt_api_token: "{{ dynatrace_token }}"
delay: "{{ dynatrace_delay }}"
rules:
- name: Look for open Process monitor problem
condition: event.title == "No process found for rule Nginx Host monitor"
action:
run_job_template:
name: Fix Nginx and update all
organization: "Default"
job_args:
extra_vars:
problemID: "{{ event.displayId }}"
reporting_host: "{{ event.impactedEntities[0].name }}"Hinweis: Red Hat erhebt keinen Anspruch auf die Korrektheit dieses Codes. Der gesamte Inhalt gilt als nicht unterstützt, sofern nicht anders angegeben.
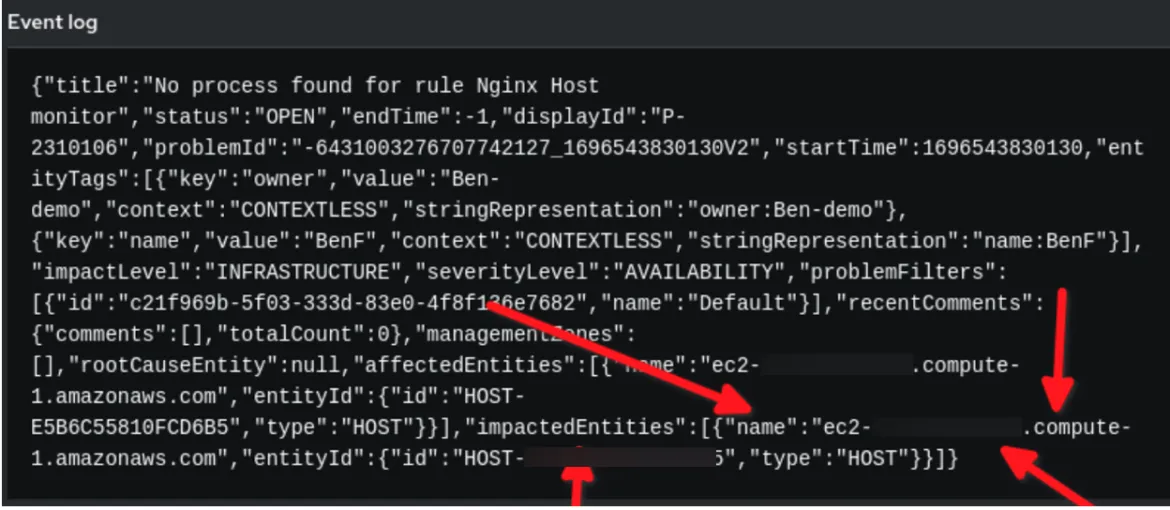
Im obigen Rulebook gibt es 2 Schlüssel in der YAML, die Aufmerksamkeit erfordern. Einer ist der Schlüssel „condition“ im Abschnitt „rules“. Beachten Sie, dass event.title gleich „No process found for rule Nginx Host monitor“ ist. Aber woher bekomme ich diesen String?
Sehen Sie sich zweitens die Variable report_host im Abschnitt „action“ an, in dem das Job-Template aufgerufen wird, das im Automation Controller ausgeführt werden soll. Woher bekomme ich event.impactedEntities[0].name?
Wir befassen uns ausführlicher mit dem Blog, um die Definition und Verwendung dieser Schlüssel in unseren eventgesteuerten Automatisierungsprozessen aufzudecken.
Nach dem Installieren von Dynatrace OneAgent auf dem Zielhost müssen Sie ein Zugriffstoken erstellen. Stellen Sie sicher, dass das Token über die folgenden Berechtigungen verfügt:
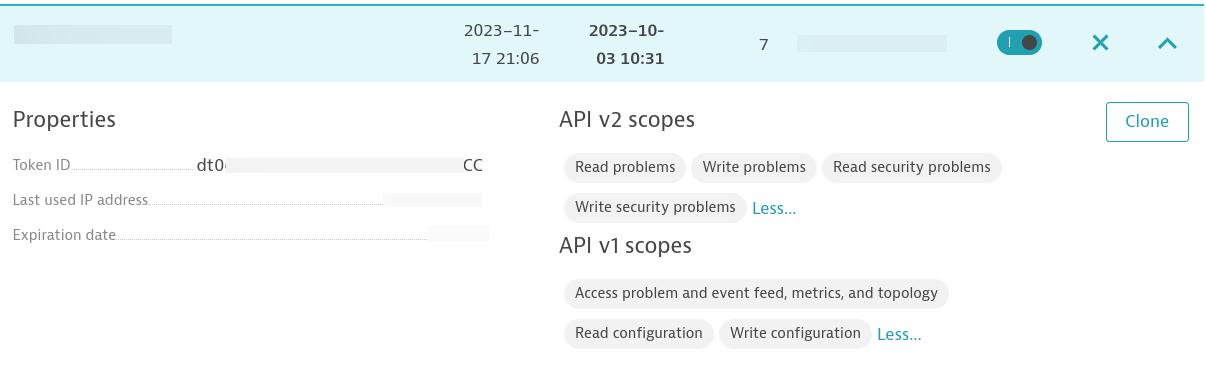
Sie müssen eine Prozessverfügbarkeits-Monitorregel auf Hostebene für den NGINX-Prozess konfigurieren. Stellen Sie sicher, dass der Hostname, auf dem NGINX ausgeführt wird, mit dem Hostnamen übereinstimmt, der in Ihrem Inventory innerhalb des Automation Controllers angegeben ist.
Nachdem Sie den Monitor eingerichtet haben, können Sie den von der Rulebook-Aktivierung abgefragten Payload in Event-Driven Ansible testen, indem Sie den NGINX-Prozess auf Ihrem gemanagten Host beenden.
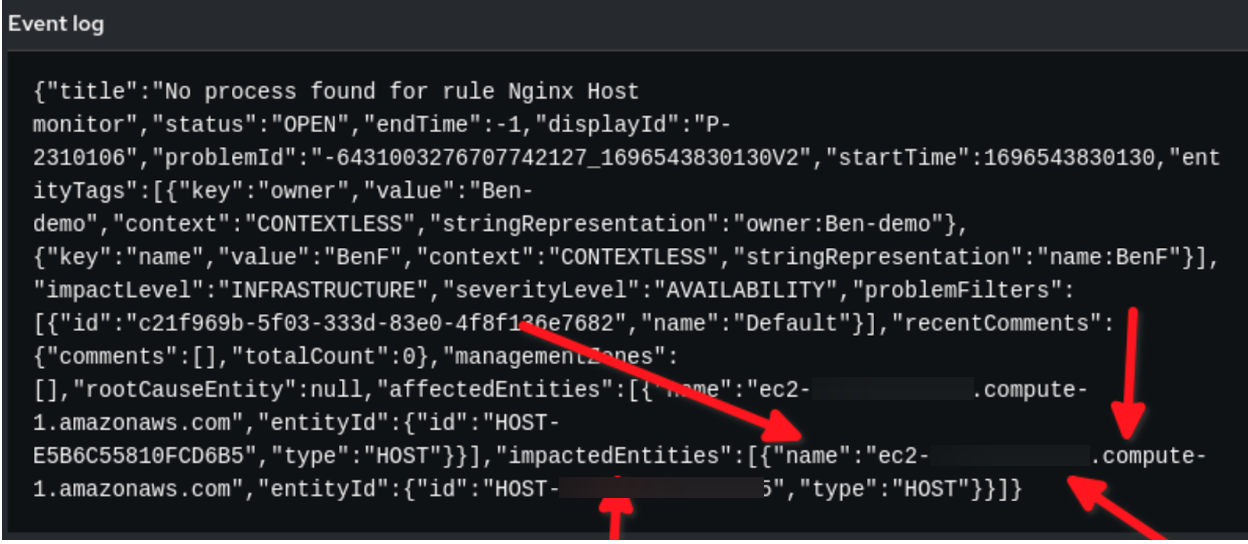
Im Beispielregelaudit können Sie sehen, wie die Payload in Event-Driven Ansible aussieht:
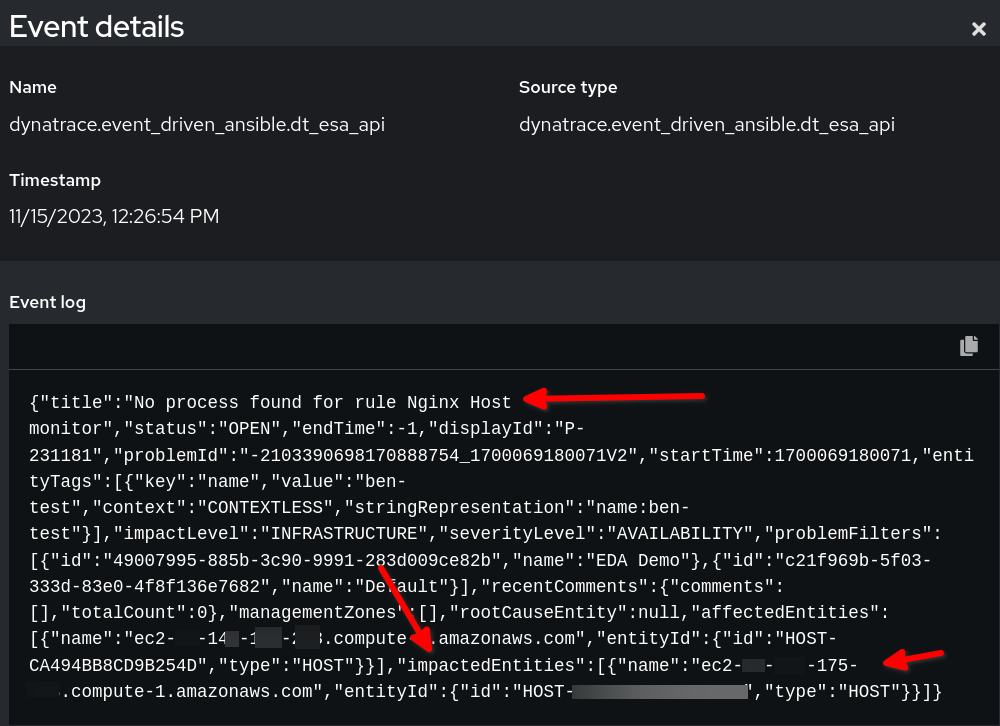
Im obigen Beispiel sehen Sie, dass die Payload-Event-Daten von Dynatrace im JSON-Format vorliegen. Wir verwenden den in event.title festgelegten String für unsere Bedingung, und die Variable reporting_host wird dynamisch durch den Wert event.impactedEntities[0].name festgelegt. Beachten Sie, dass impactedEntities.name[0].name mehr als ein Host sein kann.
Was kommt nun, nachdem wir wissen, wie der Schlüsselwert Condition und die reporting_host-Variablen festgelegt werden?
Dies ist ein günstiger Zeitpunkt, um das Playbook zu bewerten, das für die Ausführung in Automation Controller als Job-Template vorgesehen ist. Dieses Playbook wird verwendet, wenn die Event Payload, die von Event-Driven Ansible ausgelöst wird, das den NGINX-Prozess als down meldet, von Dynatrace erkannt wird:
---
- name: Restore nginx service create, update and close ServiceNow ticket after Ansible restores services
hosts: "{{ reporting_host }}"
gather_facts: false
become: true
vars:
incident_description: Nginx Web Server is down
sn_impact: medium
sn_urgency: medium
tasks:
- name: Create an incident in ServiceNow
servicenow.itsm.incident:
state: new
description: " Dynatrace reported {{ problemID }}"
short_description: "Nginx is down per {{ problemID }} on {{ reporting_host }} reported by Dynatrace nginix monitor."
caller: admin
urgency: "{{ sn_urgency }}"
impact: "{{ sn_impact }}"
register: new_incident
delegate_to: localhost
- name: Display incident number
ansible.builtin.debug:
var: new_incident.record.number
- name: Pass incident number
ansible.builtin.set_fact:
ticket_number: "{{ new_incident.record.number }}"
- name: Try to restart nginx
ansible.builtin.service:
name: nginx
state: restarted
register: chksrvc
- name: Update incident in ServiceNow
servicenow.itsm.incident:
state: in_progress
number: "{{ ticket_number }}"
other:
comments: "Ansible automation is working on {{ problemID }}. on host {{ reporting_host }}"
delegate_to: localhost
- name: Validate service is up and update/close SNOW ticket
block:
- name: Close incident in ServiceNow
servicenow.itsm.incident:
state: closed
number: "{{ ticket_number }}"
close_code: "Solved (Permanently)"
close_notes: "Go back to bed. Ansible fixed problem {{ problemID }} on host {{ reporting_host }} reported by Dynatrace."
delegate_to: localhost
when: chksrvc.state == "started"„Red Hat erhebt keinen Anspruch auf die Korrektheit dieses Codes. Der gesamte Inhalt gilt als nicht unterstützt, sofern nicht anders angegeben.“
Es ist wichtig zu betonen, dass der Name des Job-Templates, das in Automation Controller erstellt werden soll, mit dem Namen im Abschnitt run_job_template des Rulebooks übereinstimmen muss. Im Rahmen dieses Use Case-Beispiels habe ich mich dafür entschieden, Fragen in mein Job-Template zu integrieren und Eingabeaufforderungen beim Start für die Variablen problemID und reporting_host zu aktivieren, die aus dem Rulebook übergeben werden.
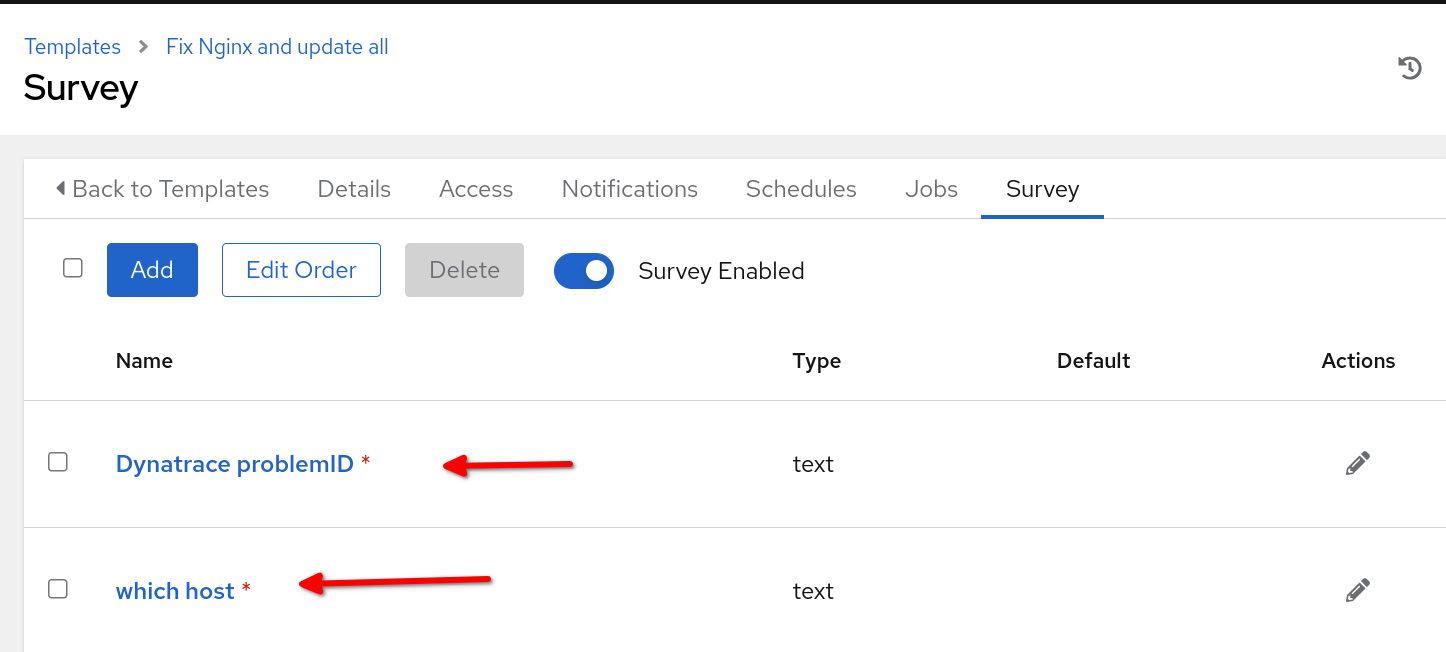
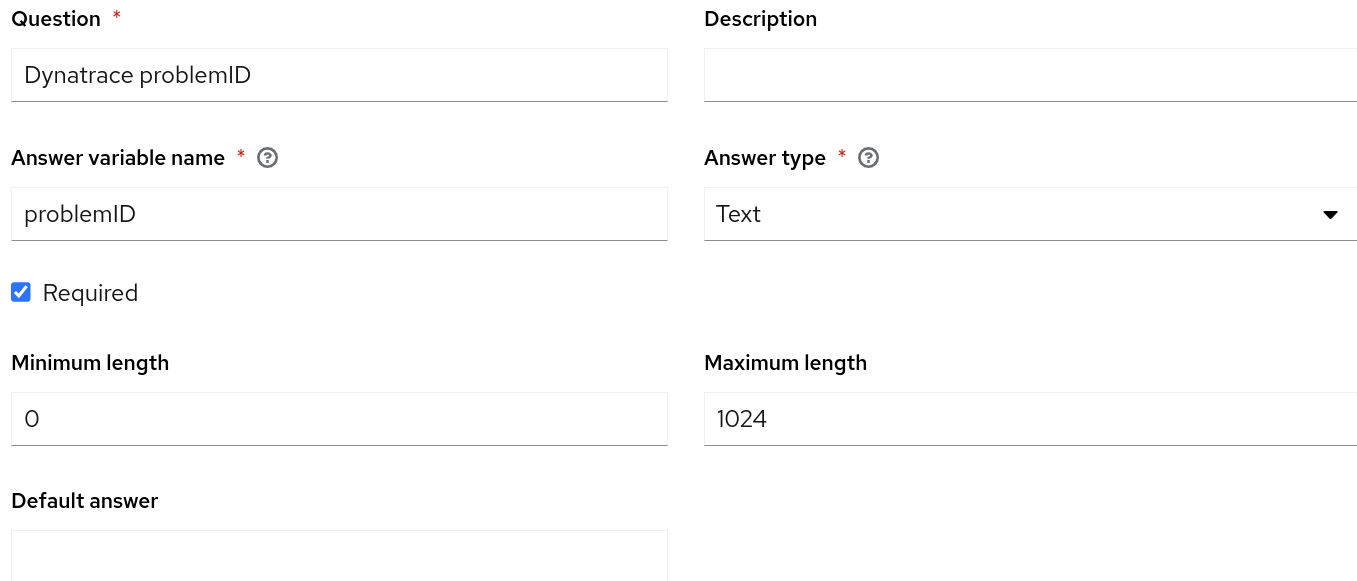
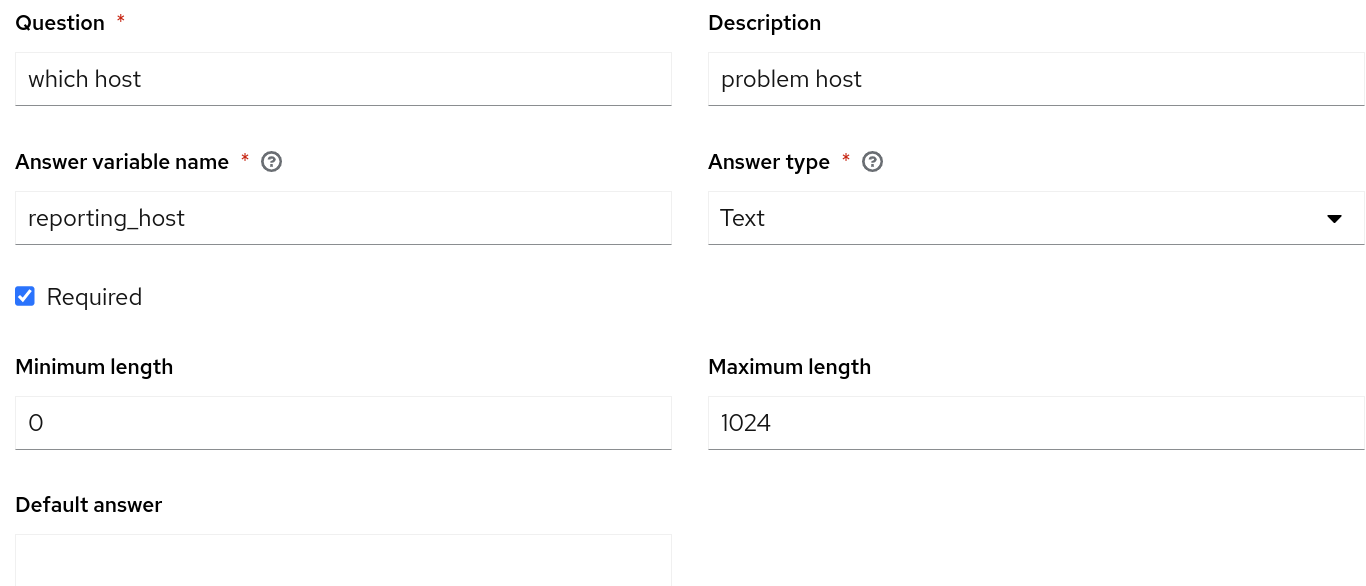
Damit unser Use Case funktioniert, muss Automation Controller in ServiceNow integriert sein und eine Ausführungsumgebung für die Automatisierung mit der ITSM ServiceNow Collection in Automation Controller konfiguriert haben, die mit Ihrem Job-Template verwendet wird. Stellen Sie außerdem sicher, dass Sie ein Projekt in Automation Controller erstellt haben, in dem sich das Remediation Playbook befindet, und dass der Hostname, auf dem der NGINX-Webserver gehostet wird, im Inventory von Automation Controller enthalten sein muss. Überprüfen Sie abschließend, ob Sie Ihren Event-Driven Ansible Controller erfolgreich in Ihren Automation Controllerintegriert haben.
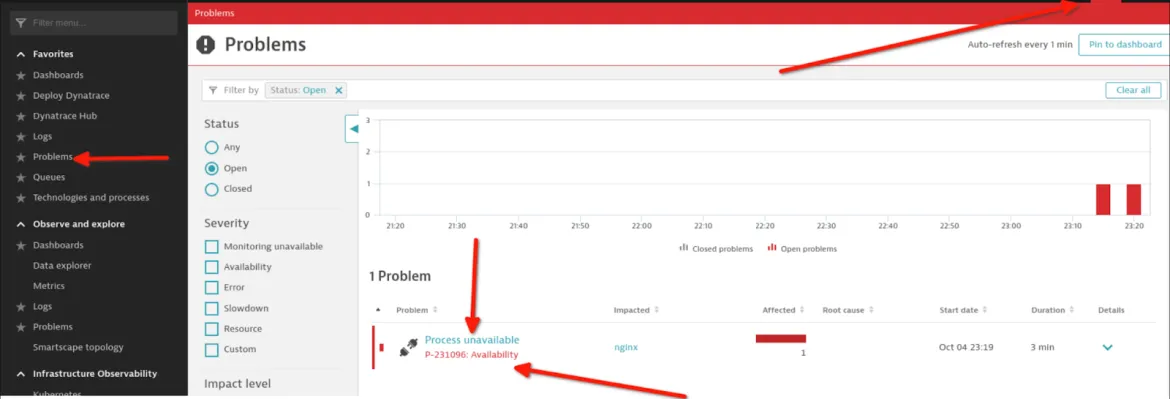
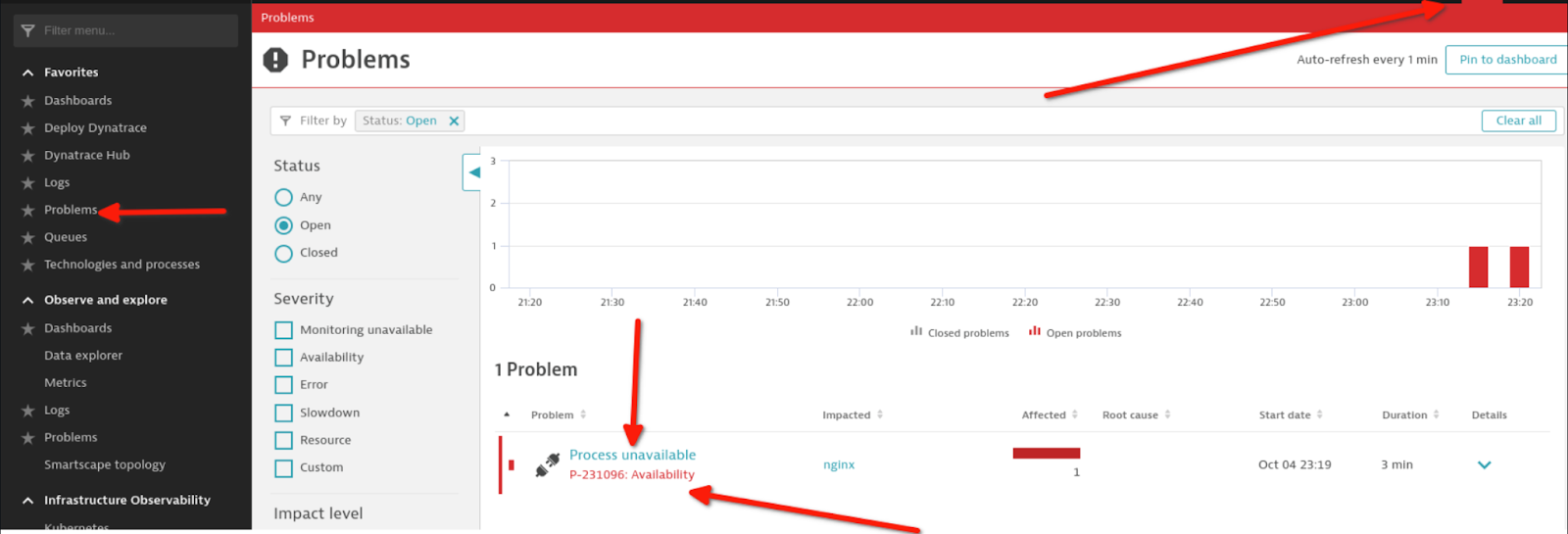
Da die Einrichtung nun abgeschlossen ist, sollten Sie diese testen. Beenden Sie dazu den NGINX-Prozess auf Ihrem Host und beobachten Sie Folgendes:
Eine in Dynatrace generierte Warnung:
Ein Regelaudit-Event in Event-Driven Ansible:
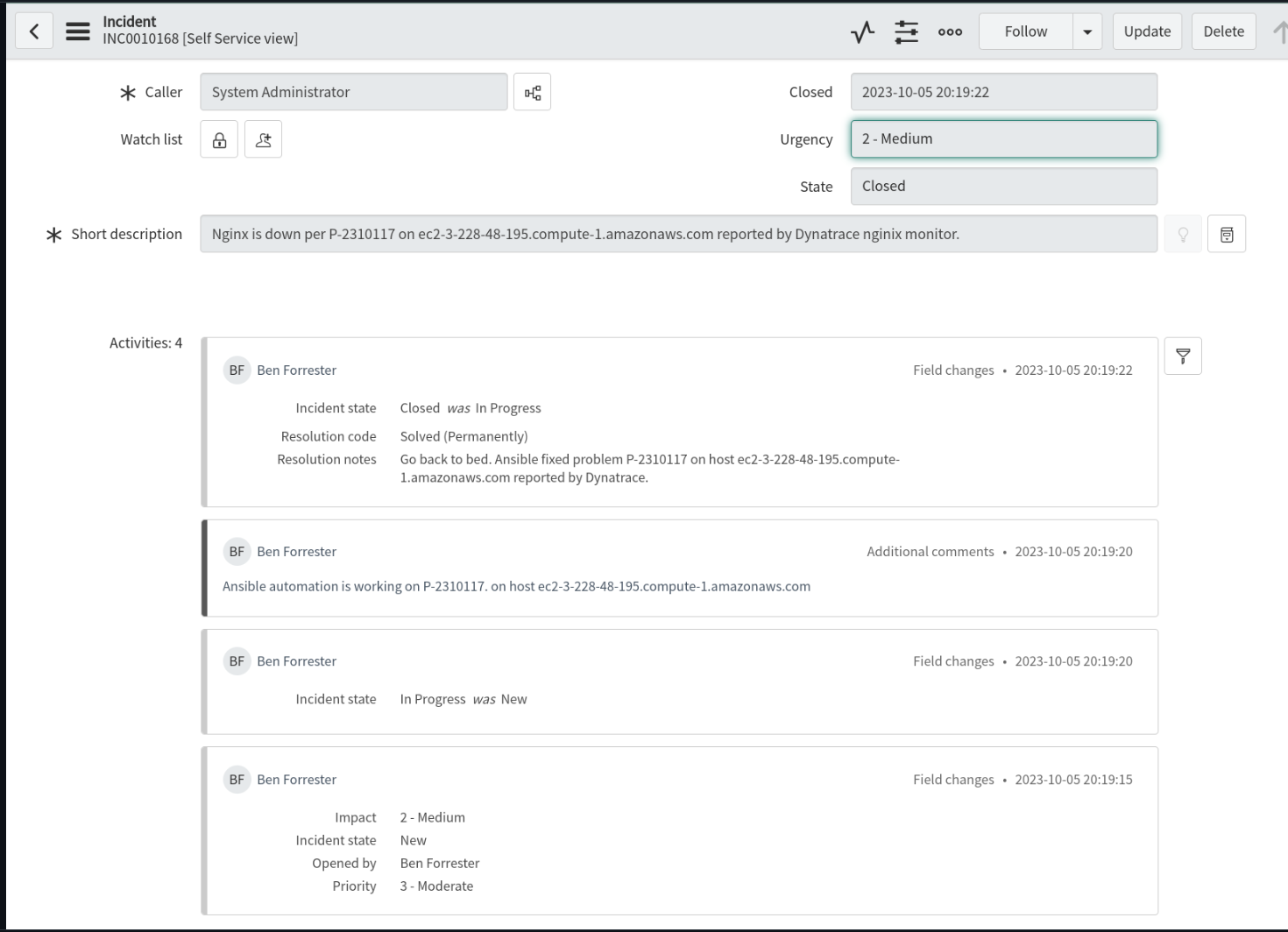
Job-Event, bei dem das Job-Template zur Problembehebung in Automation Controller ausgeführt wird

Ein Vorfallticket wird geöffnet, aktualisiert und geschlossen, wenn der NGINX-Prozess auf dem problematischen Host, der von Dynatrace gemeldet wurde, wiederhergestellt wurde.
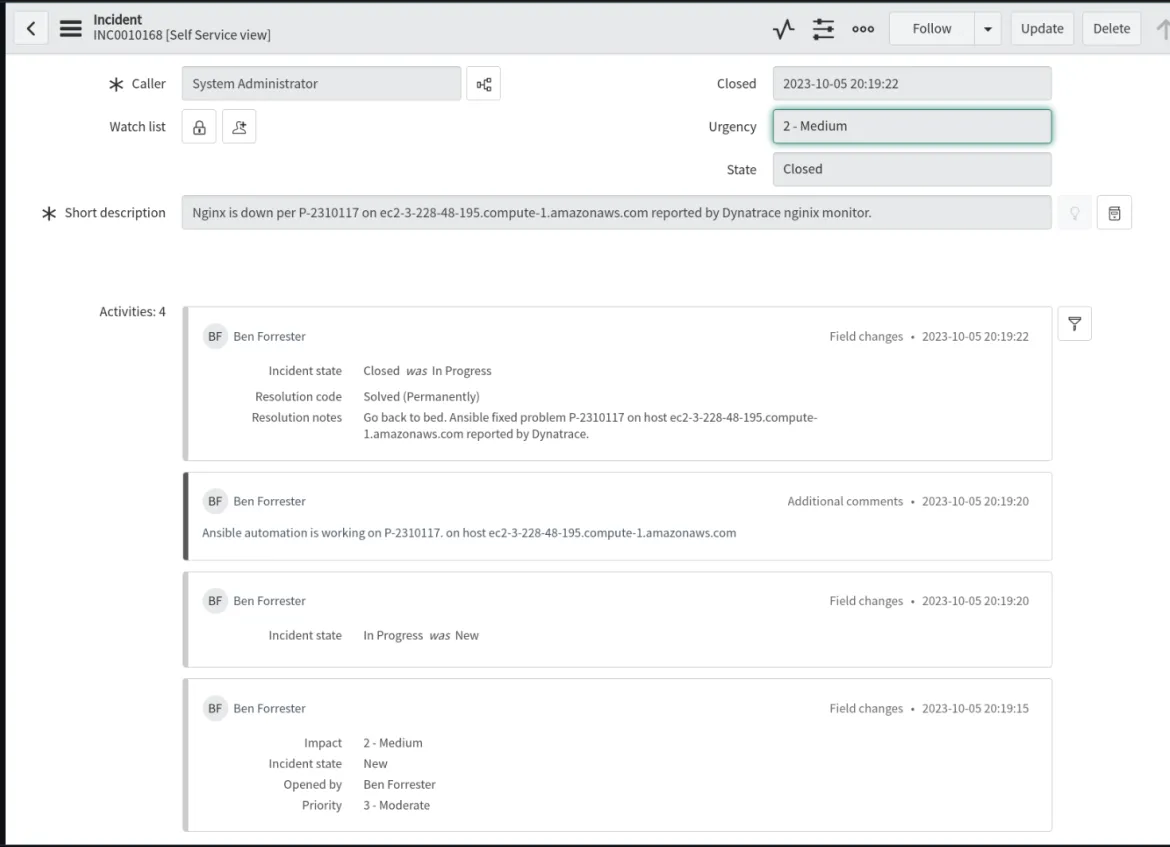

In diesem Beispiel für einen Use Case haben wir das Dynatrace-Plugin und Entscheidungsumgebungen vorgestellt und beispielhafte Payload-Event-Daten aus unserer Quelle untersucht, um zu veranschaulichen, wie Variablen dynamisch aufgefüllt werden. Wir haben einen Prozessmonitor auf Hostebene für den NGINX-Prozess in Dynatrace implementiert. Alternativ hätten wir in Dynatrace einen synthetischen Monitor für das Monitoring auf Anwendungsebene einsetzen können.
Unser Remediation Playbook betont die Bedeutung der Anpassungsfähigkeit und bleibt dynamisch. Es ist speziell darauf ausgelegt, ausschließlich auf den Hosts ausgeführt zu werden, die von Dynatrace als problematisch gemeldet wurden. Auch wenn dieses Beispiel ein breites Spektrum an Themen abdeckt, sollte erwähnt werden, dass die Automatisierung komplexer Aufgaben nicht von Anfang an einen allumfassenden Ansatz erfordert. Ziehen Sie stattdessen eine schrittweise Integration von Fehlerbehebungsaufgaben in Ihr Playbook in Betracht, während Sie lernen, Korrekturen zu automatisieren. Sie können zunächst ein Vorfallticket öffnen, bevor Sie Problembehebungen implementieren und schrittweise zur Automatisierung häufigerer Probleme übergehen. Die Anwendung standardmäßiger agiler Prinzipien auf die Automatisierung ermöglicht einen iterativen und flexiblen Ansatz. Die Zeiten, in denen häufige Probleme manuell um 3 Uhr morgens behoben werden mussten, sind vorbei. Jetzt können Sie dank effektiver unternehmensweiter Automatisierungspraktiken wieder durchschlafen.
Viel Spaß beim Automatisieren!
Zusätzliche Ressourcen und nächste Schritte
Sie möchten mehr über Event-Driven Ansible erfahren?
- Webseite von Event-Driven Ansible
- Selbstbestimmte Labs: Praktische Erfahrungen mit Event-Driven Ansible und mehr
- Video-Playlist zu Event-Driven Ansible
Über den Autor

Nach Thema durchsuchen

Automatisierung
Das Neueste zum Thema IT-Automatisierung für Technologien, Teams und Umgebungen

Künstliche Intelligenz
Erfahren Sie das Neueste von den Plattformen, die es Kunden ermöglichen, KI-Workloads beliebig auszuführen

Open Hybrid Cloud
Erfahren Sie, wie wir eine flexiblere Zukunft mit Hybrid Clouds schaffen.

Sicherheit
Erfahren Sie, wie wir Risiken in verschiedenen Umgebungen und Technologien reduzieren

Edge Computing
Erfahren Sie das Neueste von den Plattformen, die die Operations am Edge vereinfachen

Infrastruktur
Erfahren Sie das Neueste von der weltweit führenden Linux-Plattform für Unternehmen

Anwendungen
Entdecken Sie unsere Lösungen für komplexe Herausforderungen bei Anwendungen
Virtualisierung
Erfahren Sie das Neueste über die Virtualisierung von Workloads in Cloud- oder On-Premise-Umgebungen