La integración de las herramientas de determinación del estado interno de los sistemas y la automatización es fundamental en el ámbito de las operaciones de TI modernas, ya que fomenta una relación simbiótica entre la supervisión de la actividad y la eficiencia. Las herramientas de determinación del estado interno de los sistemas proporcionan información detallada sobre el rendimiento, el estado y el comportamiento de los sistemas complejos, lo que permite que las empresas identifiquen y corrijan los problemas de manera preventiva antes de que se agraven.
Cuando estas herramientas se integran a los marcos de automatización sin inconvenientes, permiten que las empresas no solo supervisen los cambios dinámicos, sino que también respondan a ellos de forma inmediata. Esta sinergia entre la determinación del estado interno de los sistemas y la automatización permite que los equipos de TI se adapten rápidamente a las condiciones cambiantes, minimicen el tiempo de inactividad y optimicen la utilización de los recursos. Al automatizar las respuestas en función de los datos obtenidos con las herramientas de determinación del estado interno de los sistemas, las empresas pueden mejorar su agilidad, reducir la intervención manual y mantener una infraestructura sólida y resistente. En esencia, la combinación de la determinación del estado interno de los sistemas y la automatización es indispensable para lograr un entorno operativo optimizado que actúe de forma preventiva y tenga capacidad de respuesta en el panorama acelerado y complejo de la tecnología actual.
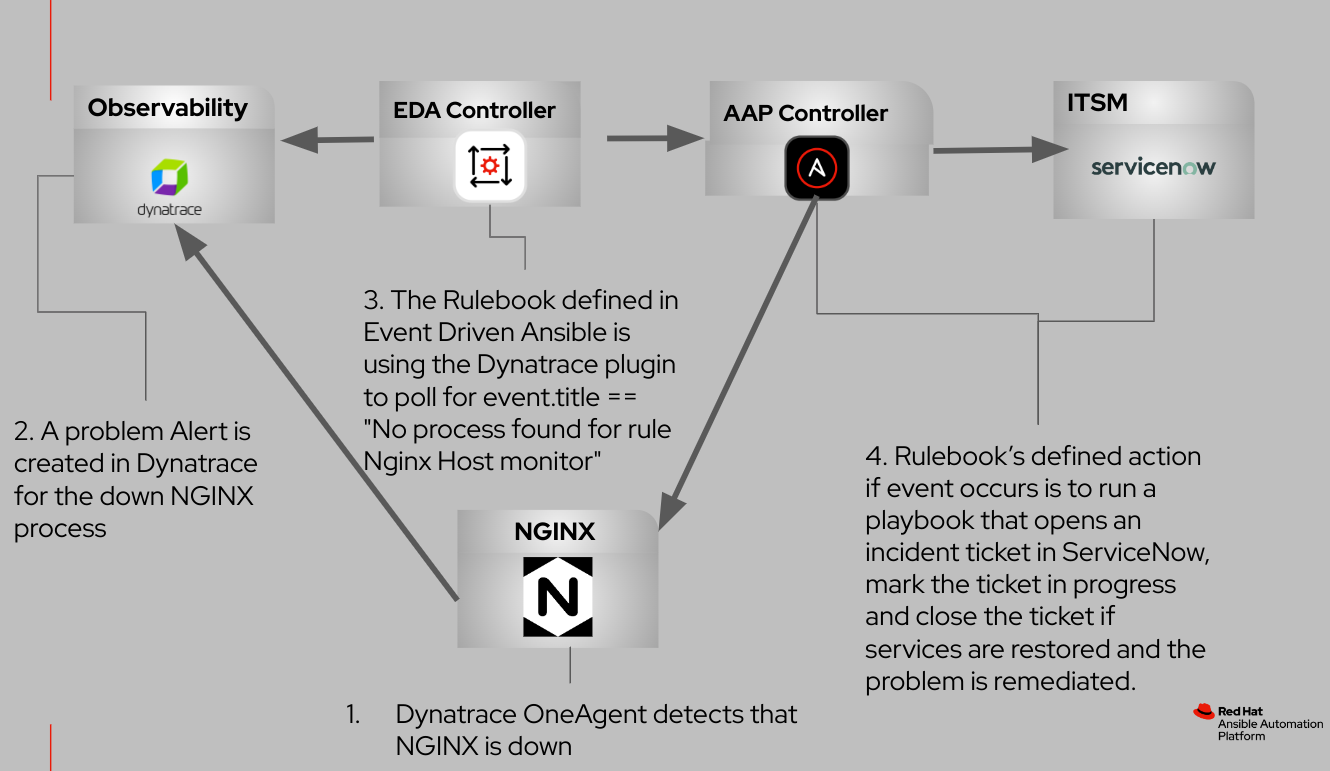
En esteb log, veremos un caso práctico común que involucra la supervisión de los procesos en máquinas virtuales y servidores dedicados (bare metal). Nuestro análisis se centrará en el uso de Dynatrace OneAgent, un archivo binario implementado en los hosts que abarca un conjunto de servicios especializados configurados meticulosamente para la supervisión del entorno. Estos servicios recopilan indicadores de telemetría de forma activa, lo cual permite obtener información sobre diversos aspectos de los hosts, como el hardware, los sistemas operativos y los procesos de las aplicaciones.
En este caso práctico, nuestro objetivo es establecer un supervisor en el nivel del host específicamente para el proceso del servidor web NGINX. Te guiaré a través de la implementación de Event-Driven Ansible, un marco de trabajo que vincula las fuentes de eventos con las acciones correspondientes a través de reglas definidas. En esta instancia, la fuente de eventos es Dynatrace.
Una vez que se complete la configuración, simularemos la siguiente situación:
- El servidor web NGINX experimenta un tiempo de inactividad no planificado en el servidor.
- El supervisor de procesos, facilitado por Dynatrace OneAgent, detecta rápidamente el proceso de NGINX con errores y genera una alerta de problema en la plataforma Dynatrace.
- El complemento de la fuente Dynatrace, como se define en el rulebook empleado por Event-Driven Ansible, efectúa sondeos de manera activa en busca de eventos de error.
- Event-Driven Ansible, en respuesta al evento, ejecuta una plantilla de trabajo que realiza las siguientes acciones:
- Inicia la creación de una solicitud de seguimiento de incidentes de ServiceNow.
- Intenta reiniciar el proceso de NGINX.
- Actualiza el estado de la solicitud de seguimiento de incidentes a "En curso".
- Cierra la solicitud de seguimiento de incidentes solo si el proceso de NGINX se restaura correctamente.
El siguiente diagrama de flujo ilustra las interacciones entre estos elementos integrados.
Antes de comenzar, repasemos algunos términos que coincidirán con los conceptos básicos de Event-Driven Ansible:
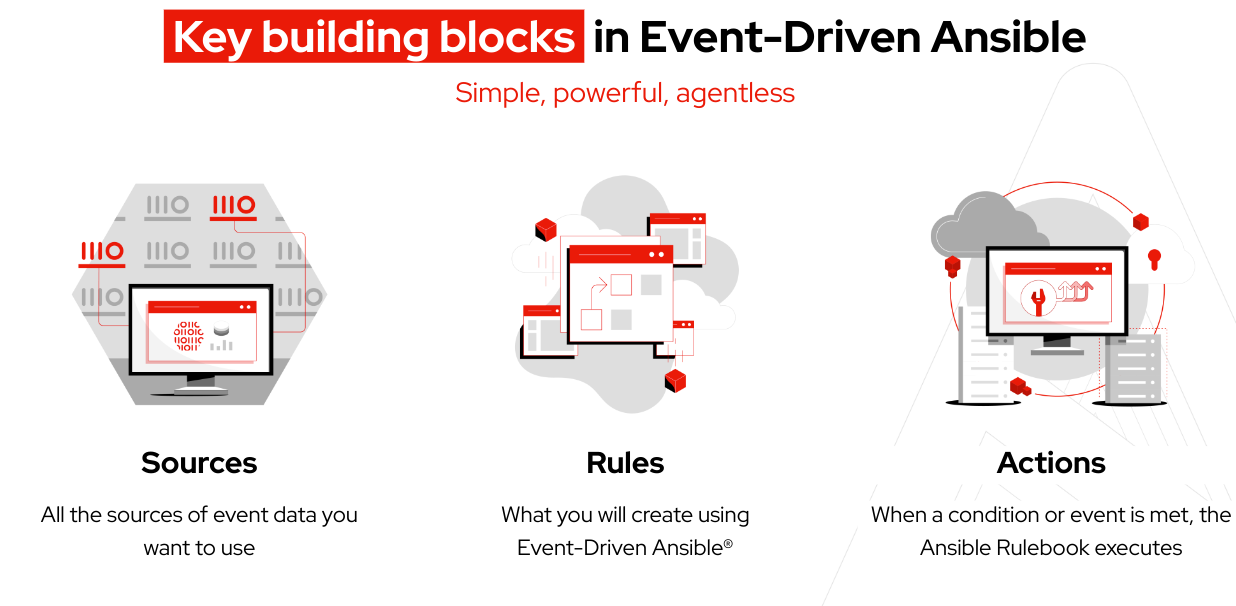
Terminología:
Un rulebook de Ansible abarca tanto la fuente de eventos como las instrucciones detalladas basadas en reglas sobre las acciones que se deben realizar cuando se cumplen ciertas condiciones específicas, lo que ofrece un alto grado de flexibilidad.
Un entorno de toma de decisiones es una imagen de contenedor diseñada para ejecutar los rulebooks de Ansible que se utilizan en el controlador de Event-Driven Ansible.
Los plugins de la fuente de eventos se suelen redactar en Python y tienen el propósito de recopilar eventos de la fuente que especifiques. Además, los complementos se distribuyen a través de los conjuntos de contenido certificado Red Hat Ansible Certified Content Collections.
Se debe crear un entorno de toma de decisiones. A continuación, se presenta un ejemplo del archivo de creación:
---
version: 3
images:
base_image:
name: registry.redhat.io/ansible-automation-platform-24/de-minimal-rhel8:latest
dependencies:
galaxy:
collections:
- ansible.eda
- dynatrace.event_driven_ansible
system:
- pkgconf-pkg-config [platform:rpm]
- systemd-devel [platform:rpm]
- gcc [platform:rpm]
- python39-devel [platform:rpm]
options:
package_manager_path: /usr/bin/microdnfConsulta la documentación provista para obtener orientación adicional sobre la creación de entornos de toma de decisiones. Después de crearlo, envía la imagen de contenedor al repositorio de imágenes que designaste y, luego, extrae la imagen y pásala al controlador de Event-Driven Ansible.
Con el establecimiento del entorno de toma de decisiones, estás a punto de crear una activación de reglas en el controlador de Event-Driven Ansible. Esta activación encapsulará el rulebook y definirá la fuente de eventos junto con instrucciones detalladas sobre las acciones que se deberán llevar a cabo bajo condiciones específicas. De manera similar a la organización de los playbooks dentro de los proyectos del controlador de la automatización, el controlador de Event-Driven Ansible emplea proyectos para gestionar y contener nuestros rulebooks.
A continuación, encontrarás una jerarquía estándar de los directorios para organizar y almacenar los rulebooks y los playbooks en tu repositorio de Git.
Una vez que creemos un proyecto en el controlador de Event-Driven Ansible, deberemos crear una activación de rulebook, que es un proceso en segundo plano definido por un rulebook que se ejecuta dentro de un entorno de toma de decisiones.
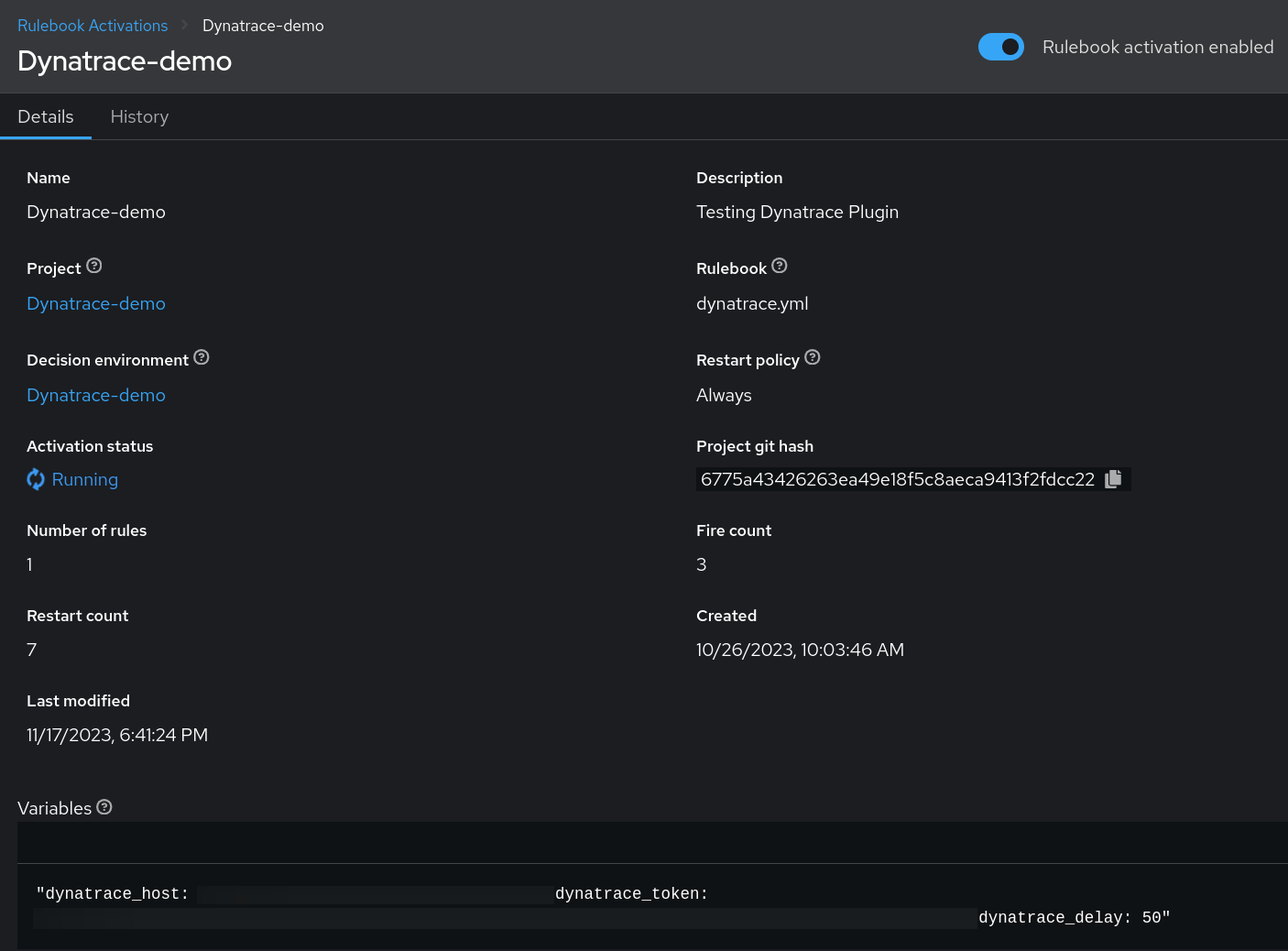
Para este caso práctico, crearemos un rulebook que use el plugin de Dynatrace como la fuente de eventos de Ansible y especificaremos lo que queremos que se lleve a cabo cuando se cumpla una condición.
En general, hay tres patrones de integración para los plugins de la fuente:
- sondeo
- webhook
- mensajería
En el contexto de nuestro caso práctico, el complemento de la fuente Dynatrace recupera eventos de manera eficiente mediante la realización de un sondeo activo de acuerdo con las condiciones especificadas que se describen en el rulebook. Este mecanismo de sondeo introduce una variable delay referida al plugin de Dynatrace, como se describe en el rulebook (consulta la configuración de la variable delay).
Esta variable de retraso cumple una función crucial en la regulación del comportamiento del plugin al implementar un mecanismo de limitación. Básicamente, organiza la realización de llamadas a la API en intervalos predefinidos, lo que permite que el complemento genere un nuevo evento basado en la respuesta recibida. Este ritmo intencional de las llamadas a la API resulta fundamental para gestionar y optimizar el flujo de trabajo general, reducir el riesgo de encontrar límites de frecuencia y garantizar que el sistema funcione sin problemas.
Consulte el siguiente rulebook:
---
- name: Watching for Problems on Dynatrace
hosts: all
sources:
- dynatrace.event_driven_ansible.dt_esa_api:
dt_api_host: "{{ dynatrace_host }}"
dt_api_token: "{{ dynatrace_token }}"
delay: "{{ dynatrace_delay }}"
rules:
- name: Look for open Process monitor problem
condition: event.title == "No process found for rule Nginx Host monitor"
action:
run_job_template:
name: Fix Nginx and update all
organization: "Default"
job_args:
extra_vars:
problemID: "{{ event.displayId }}"
reporting_host: "{{ event.impactedEntities[0].name }}"Nota: Red Hat no garantiza expresamente brindar soporte por fallas en el código. Ningún contenido goza de garantía de soporte, salvo que se indique lo contrario.
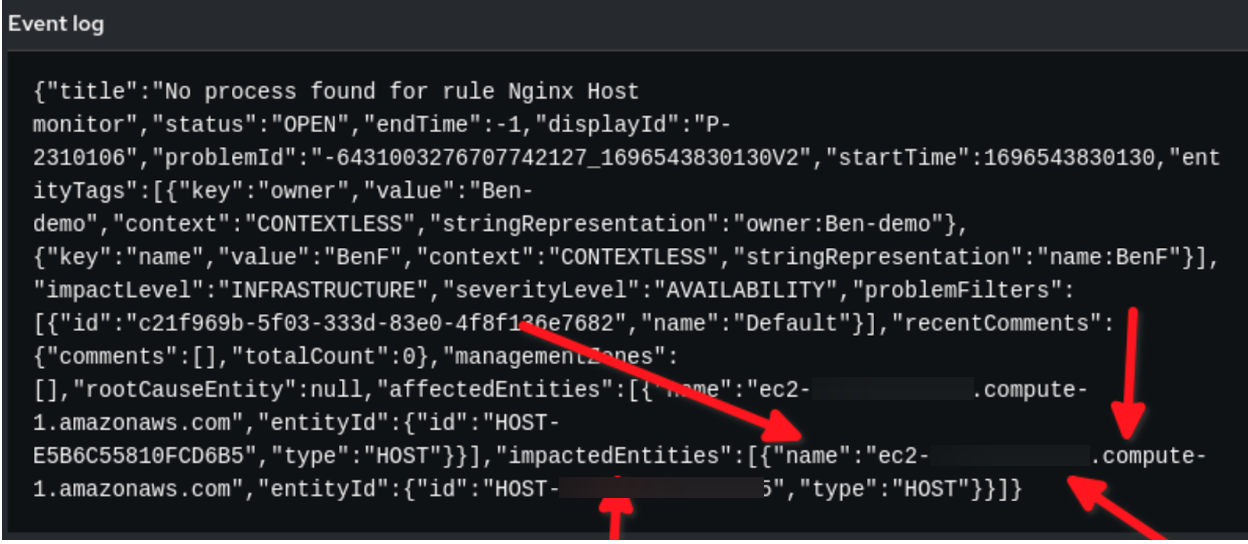
En el rulebook anterior, hay dos claves en YAML que requieren atención. Una es la clave de condición de la sección de reglas. Observa que event.title es igual a "No process found for rule Nginx Host monitor". Pero, ¿de dónde obtuve esa cadena?
En segundo lugar, observa la variable reporting_host en la sección de acción, donde llamamos a la plantilla de trabajo para que se ejecute en el controlador de la automatización. ¿Dónde obtengo event.impactedEntities[0].name?
Profundizaremos en esto a lo largo del blog para descubrir la definición y el uso de estas claves en nuestros procesos de automatización basada en eventos.
Una vez que instales Dynatrace OneAgent en el host de destino, deberás crear un token de acceso. Asegúrate de que el token tenga los siguientes permisos:
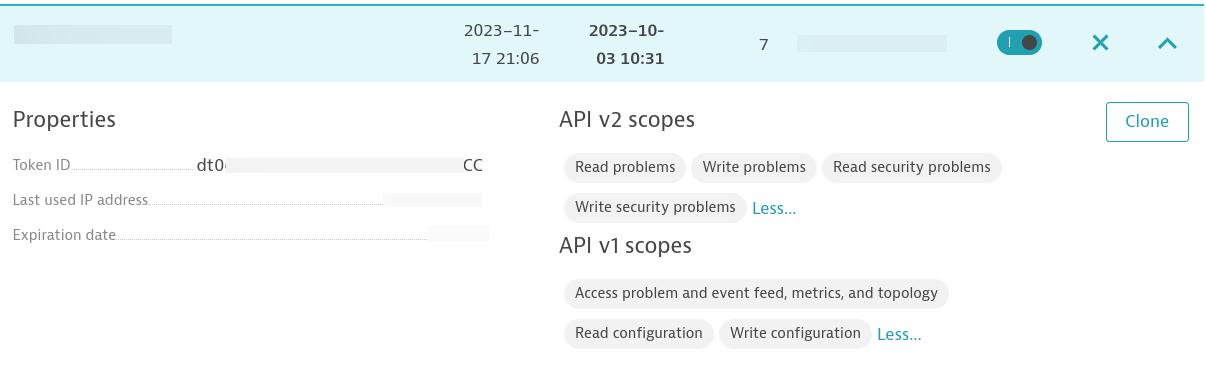
Deberás configurar una regla que supervise la disponibilidad de los procesos en el nivel del host para el proceso de NGINX. Asegúrate de que el nombre de host que ejecuta NGINX coincida con el nombre de host especificado en el inventario dentro del controlador de la automatización.
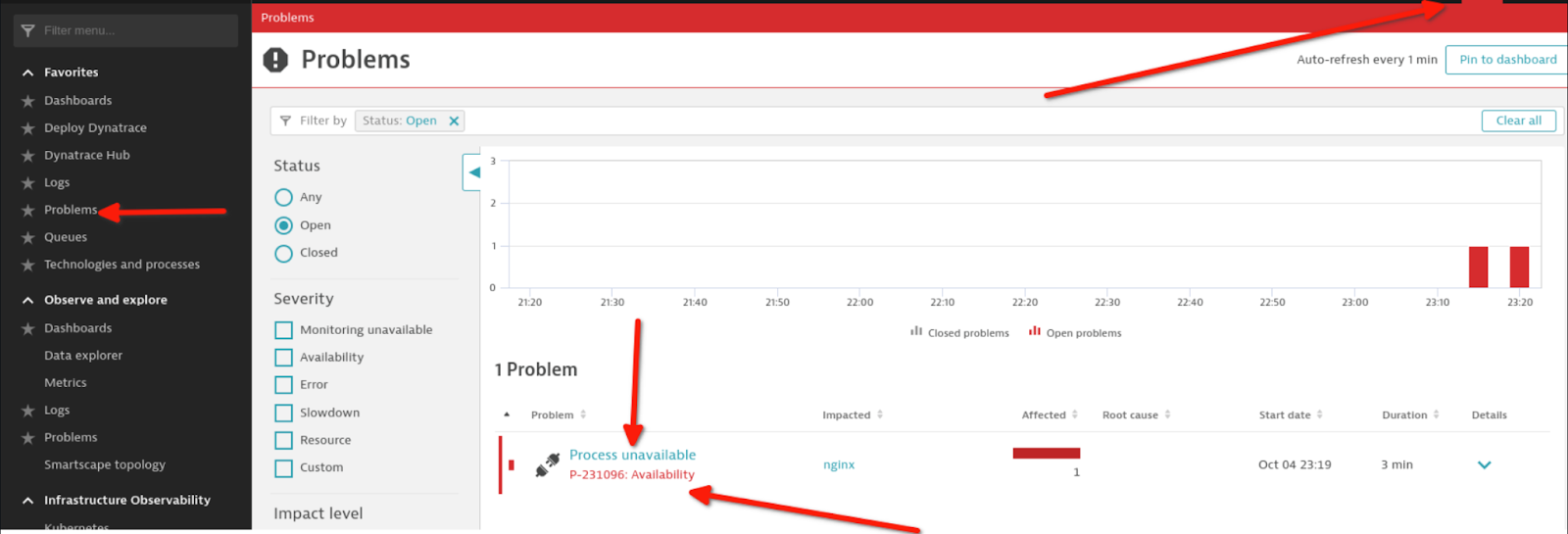
Después de configurar el supervisor, puedes probar la carga útil que se sondea por medio de la activación del rulebook en Event-Driven Ansible finalizando el proceso de NGINX en el host administrado.
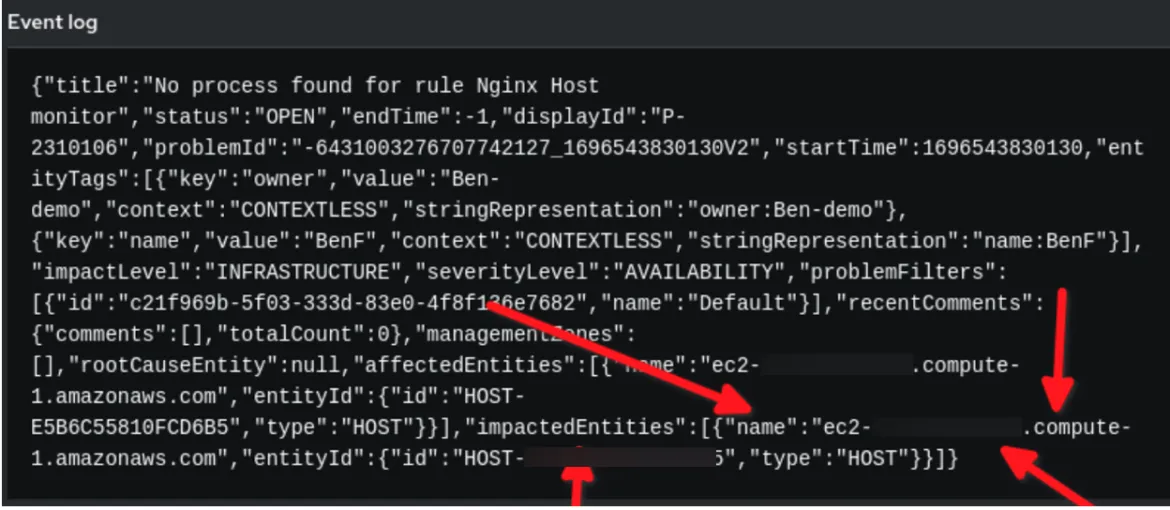
Observa el ejemplo de auditoría de reglas que muestra cómo se verá la carga útil en Event-Driven Ansible:
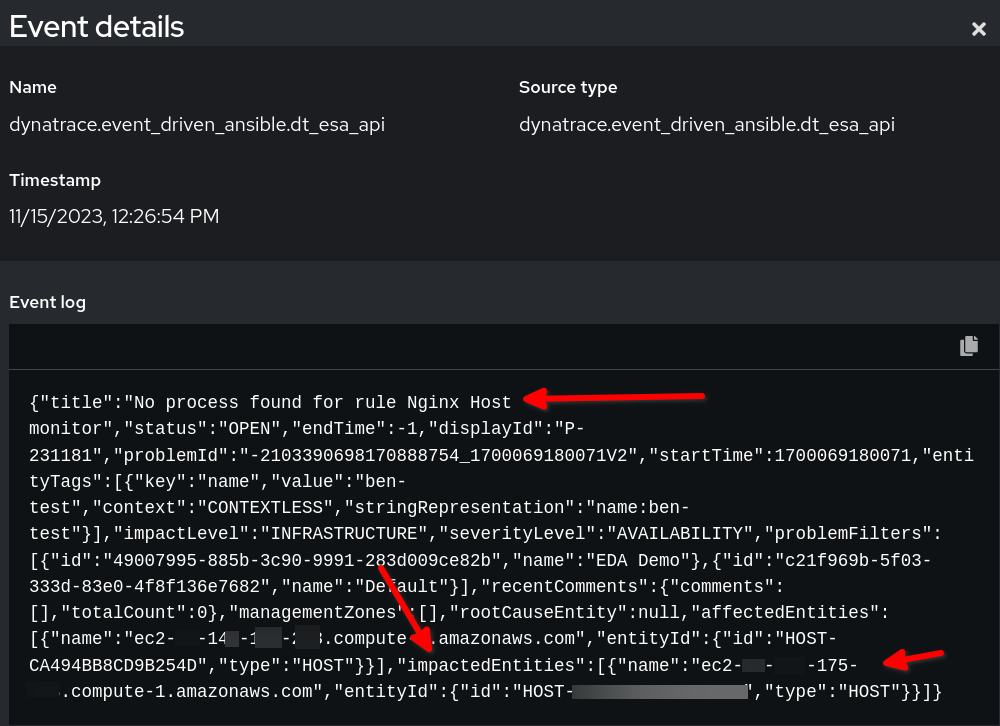
En el ejemplo anterior, verás que los datos de los eventos de la carga útil de Dynatrace están en formato JSON. Usamos la cadena establecida en event.title para nuestra condición y la variable reporting_host se establece dinámicamente por el valor event.impactedEntities[0].name. Ten en cuenta que impactedEntities.name[0].name podría ser más de un host.
Ahora que sabemos cómo se establecen el valor de la clave condition y la variable reporting_host, ¿qué sigue?
Este es un momento oportuno para evaluar el playbook que se desea ejecutar en el controlador de la automatización como plantilla de trabajo. Este playbook se usa cuando Dynatrace detecta la carga útil del evento, que Event-Driven Ansible activa cuando informa que el proceso de NGINX está inactivo:
---
- name: Restore nginx service create, update and close ServiceNow ticket after Ansible restores services
hosts: "{{ reporting_host }}"
gather_facts: false
become: true
vars:
incident_description: Nginx Web Server is down
sn_impact: medium
sn_urgency: medium
tasks:
- name: Create an incident in ServiceNow
servicenow.itsm.incident:
state: new
description: " Dynatrace reported {{ problemID }}"
short_description: "Nginx is down per {{ problemID }} on {{ reporting_host }} reported by Dynatrace nginix monitor."
caller: admin
urgency: "{{ sn_urgency }}"
impact: "{{ sn_impact }}"
register: new_incident
delegate_to: localhost
- name: Display incident number
ansible.builtin.debug:
var: new_incident.record.number
- name: Pass incident number
ansible.builtin.set_fact:
ticket_number: "{{ new_incident.record.number }}"
- name: Try to restart nginx
ansible.builtin.service:
name: nginx
state: restarted
register: chksrvc
- name: Update incident in ServiceNow
servicenow.itsm.incident:
state: in_progress
number: "{{ ticket_number }}"
other:
comments: "Ansible automation is working on {{ problemID }}. on host {{ reporting_host }}"
delegate_to: localhost
- name: Validate service is up and update/close SNOW ticket
block:
- name: Close incident in ServiceNow
servicenow.itsm.incident:
state: closed
number: "{{ ticket_number }}"
close_code: "Solved (Permanently)"
close_notes: "Go back to bed. Ansible fixed problem {{ problemID }} on host {{ reporting_host }} reported by Dynatrace."
delegate_to: localhost
when: chksrvc.state == "started""Nota: Red Hat no garantiza expresamente brindar soporte por fallas en el código. Ningún contenido goza de garantía de corrección, salvo que se indique lo contrario".
Es importante enfatizar que el nombre de la plantilla de trabajo que se establecerá en el controlador de la automatización debe coincidir con el nombre especificado en la sección run_job_template del rulebook. En el contexto de este caso práctico de ejemplo, opté por incorporar encuestas dentro de mi plantilla de trabajo y habilité solicitudes en el inicio para las variables problemID y reporting_host, tal como se pasan desde el rulebook.
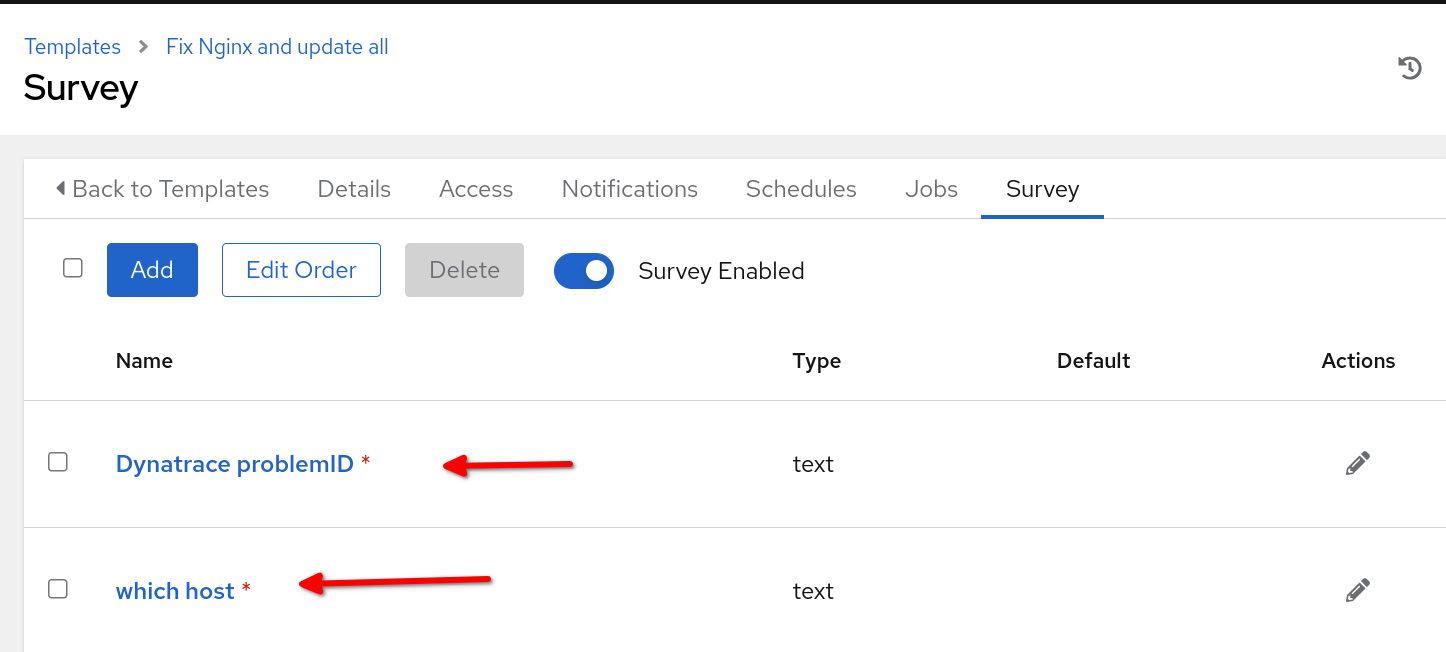
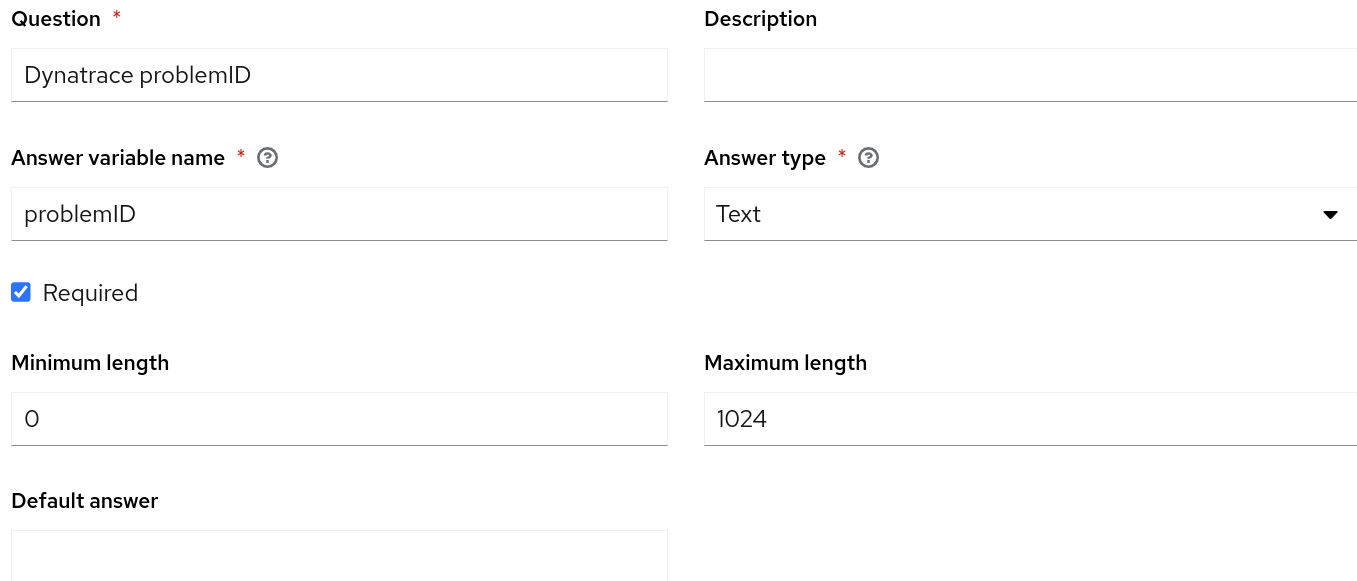
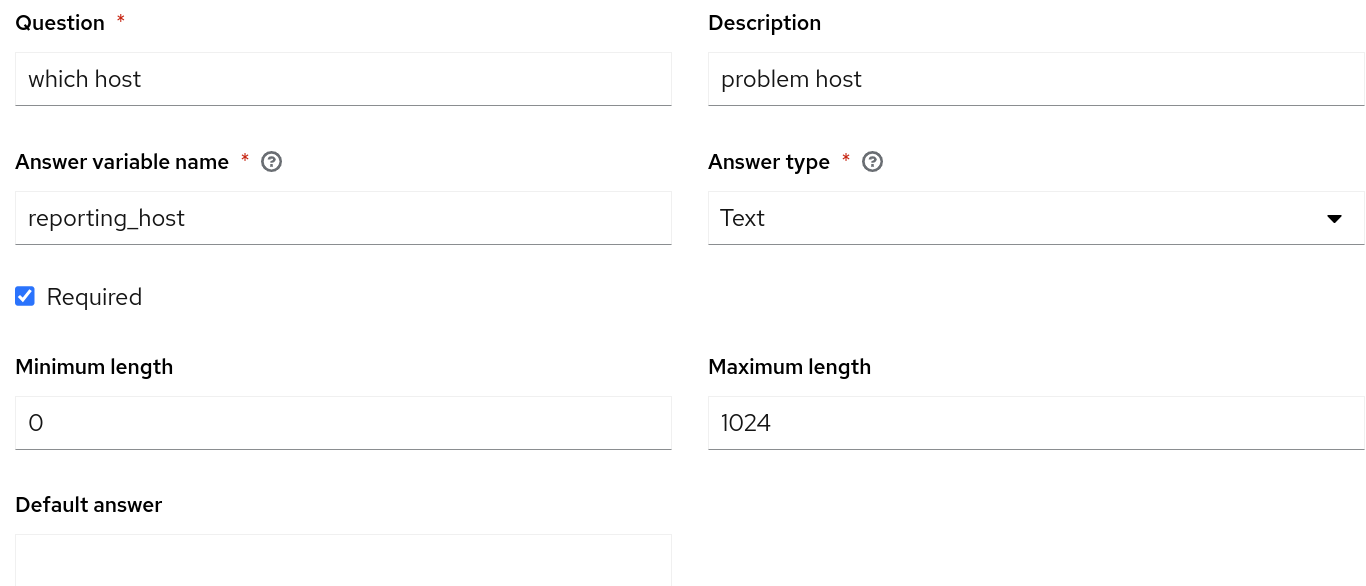
Para que nuestro caso práctico funcione, necesitarás que tu controlador de automatización esté integrado a ServiceNow y tenga un entorno de ejecución de la automatización con el conjunto ITSM ServiceNow configurado en el controlador de la automatización para usarlo con la plantilla de trabajo. Además, asegúrate de haber creado un proyecto en el controlador de la automatización que contenga el playbook de corrección y de que el nombre de host que aloja el servidor web NGINX esté incluido en el inventario del controlador de la automatización. Por último, asegúrate de haber integrado correctamente el controlador de Event-Driven Ansible y el controlador de la automatización.
Ahora que todo está configurado de manera correcta, debes probarlo finalizando el proceso de NGINX en el host y observar lo siguiente:
Se genera una alerta en Dynatrace.
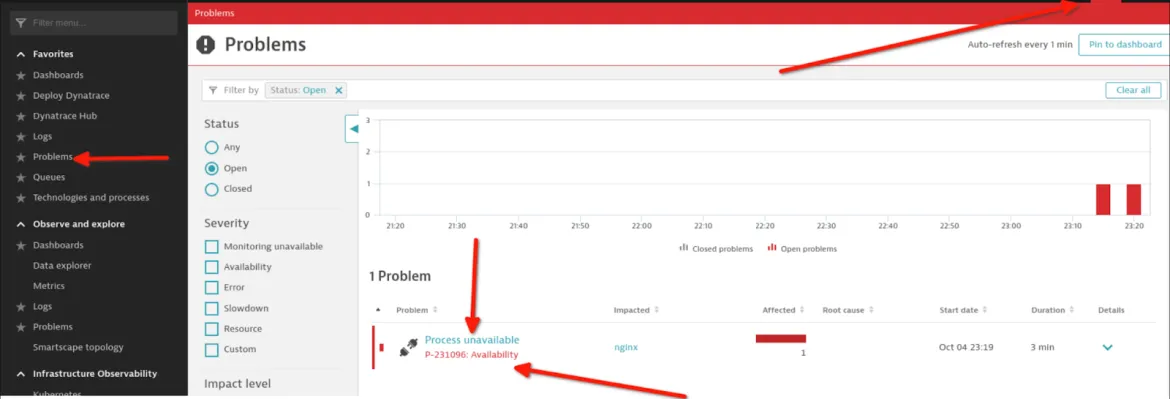
Se produce un evento de auditoría de reglas en Event-Driven Ansible.
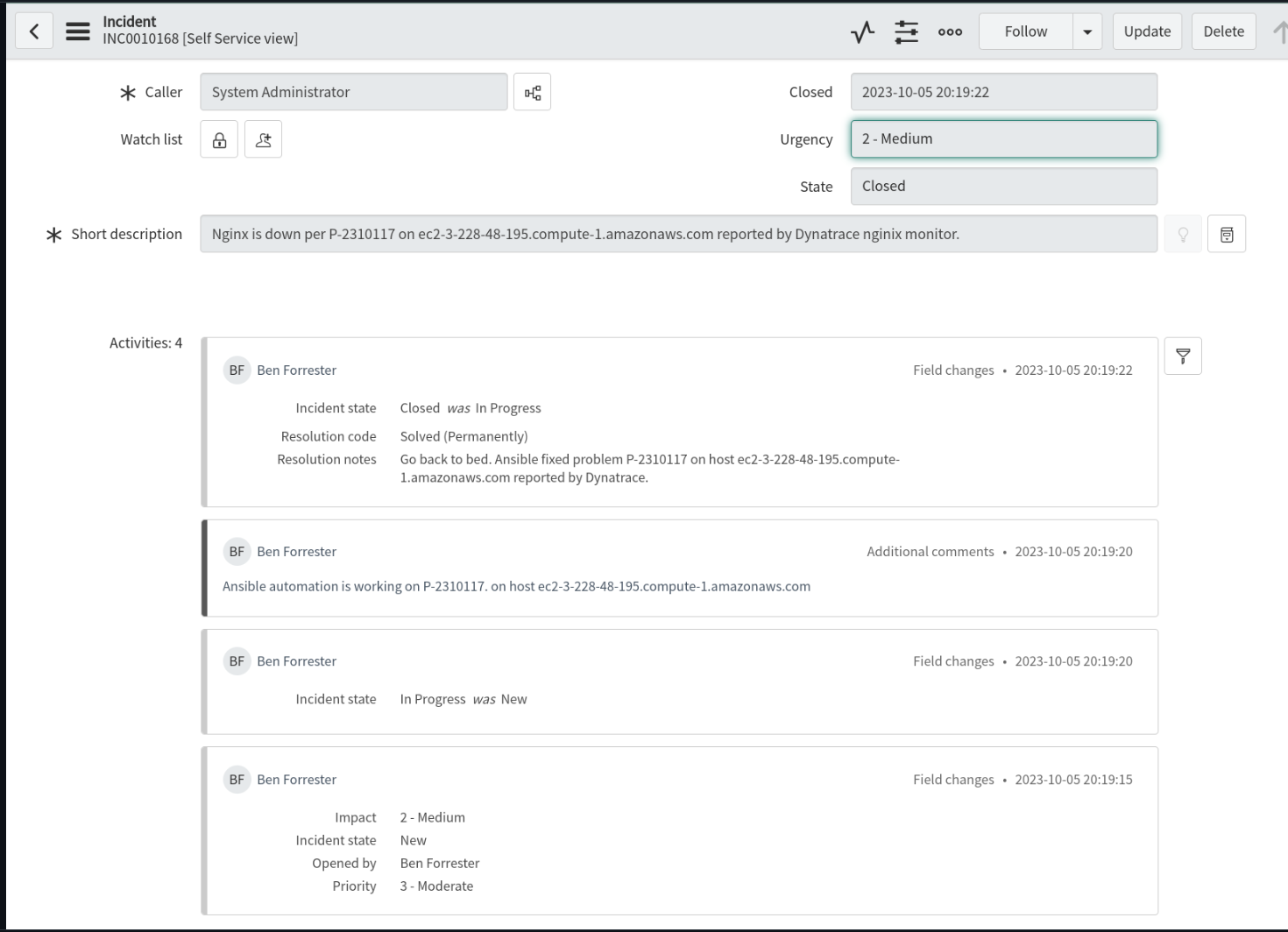
Se produce un evento de trabajo en el que la plantilla de trabajo de corrección se ejecuta en el controlador de la automatización.

Se inicia una solicitud de seguimiento de incidentes, se actualiza y se cierra si el proceso de NGINX se restaura en el host problemático que informó Dynatrace.
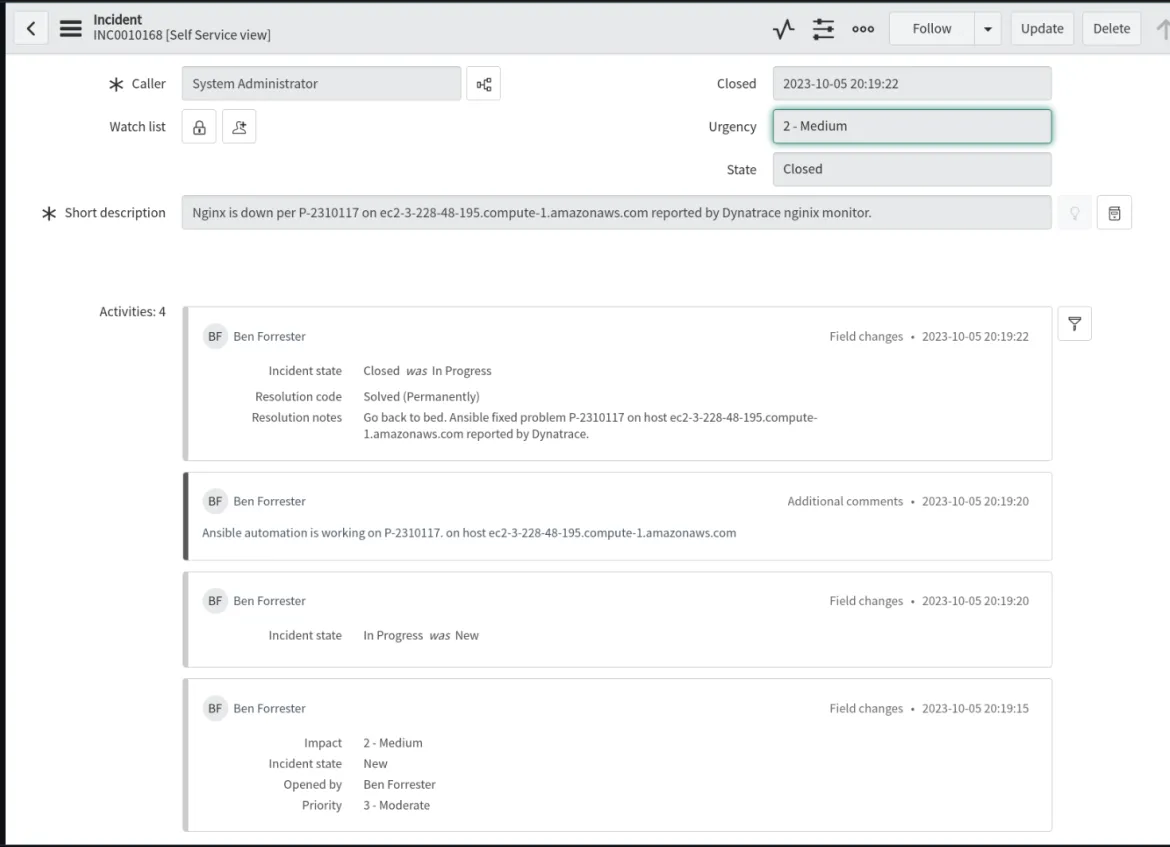

En este caso práctico de ejemplo, presentamos el plugin de Dynatrace y los entornos de toma de decisiones, y analizamos los datos de los eventos de la carga útil de muestra de nuestra fuente para demostrar cómo completar dinámicamente las variables. Implementamos un supervisor de procesos en el nivel del host para el proceso de NGINX en Dynatrace. También podríamos haber empleado un supervisor sintético en Dynatrace para que lleve a cabo la supervisión en el nivel de las aplicaciones.
Nuestro playbook de corrección, que enfatiza la importancia de la adaptabilidad, sigue siendo dinámico y está específicamente diseñado para ejecutarse únicamente en los hosts informados como problemáticos por Dynatrace. Si bien este ejemplo abarca una gran cantidad de temas, es fundamental reconocer que la automatización de tareas complejas no requiere un enfoque integral desde el principio. En cambio, considera la posibilidad de integrar gradualmente las tareas de corrección en el playbook a medida que aprendas a automatizar las correcciones. Al comienzo, puedes optar por iniciar una solicitud de seguimiento de incidentes antes de implementar cualquier acción de corrección, y pasar gradualmente a la automatización de los problemas comunes. La aplicación de principios ágiles estándares al proceso de automatización permite adoptar un enfoque flexible que se puede repetir. Vale la pena señalar que la era en la que los problemas comunes se solucionan manualmente a las 3:00 de la mañana está llegando a su fin, lo que te ofrece la oportunidad de recuperar las horas de sueño gracias a la aplicación de prácticas efectivas de automatización empresarial.
Ya puedes comenzar a automatizar los procesos.
Recursos adicionales y próximos pasos
¿Deseas obtener más información sobre Event-Driven Ansible?
- Página web de Event-Driven Ansible
- Laboratorios autorregulados: Experiencia práctica con Event-Driven Ansible y mucho más
- Lista de reproducción de videos de Event-Driven Ansible
Sobre el autor

Navegar por canal

Automatización
Las últimas novedades en la automatización de la TI para los equipos, la tecnología y los entornos

Inteligencia artificial
Descubra las actualizaciones en las plataformas que permiten a los clientes ejecutar cargas de trabajo de inteligecia artificial en cualquier lugar

Nube híbrida abierta
Vea como construimos un futuro flexible con la nube híbrida

Seguridad
Vea las últimas novedades sobre cómo reducimos los riesgos en entornos y tecnologías

Edge computing
Conozca las actualizaciones en las plataformas que simplifican las operaciones en el edge

Infraestructura
Vea las últimas novedades sobre la plataforma Linux empresarial líder en el mundo

Aplicaciones
Conozca nuestras soluciones para abordar los desafíos más complejos de las aplicaciones
Virtualización
El futuro de la virtualización empresarial para tus cargas de trabajo locales o en la nube