Um dos principais componentes de uma arquitetura baseada em containers é a segurança.
Há muitos aspectos relacionados a isso (confira a lista de tópicos na documentação oficial do OpenShift aqui), mas alguns dos requisitos mais básicos são autenticação e autorização. Neste artigo, explico como a autenticação e a autorização funcionam no Kubernetes e no Red Hat OpenShift. Abordarei as interações entre as diferentes camadas de um ecossistema do Kubernetes, como a de infraestrutura, a do Kubernetes e a de aplicações em containers.
O que são a autenticação e a autorização?
Em termos simples, a autenticação em um sistema computacional é uma maneira de responder "Quem é você?", e a autorização é "Agora que sei que é você, o que você tem permissão para fazer?".
Na minha experiência, grande parte da dificuldade em entender esse assunto no Kubernetes se deve à quantidade de componentes (usuários, APIs, containers e pods) que interagem entre si. Ao falar sobre autenticação, primeiro você precisa esclarecer quais componentes estão envolvidos. Você está autenticando no cluster do Kubernetes? Está falando de um microsserviço tentando acessar outro microsserviço dentro do ambiente? Ou talvez de um recurso de nuvem fora do cluster do Kubernetes? Ou de um endpoint (um recurso de nuvem, um sistema ou uma pessoa) tentando acessar e usar uma das aplicações em execução no cluster?
Autenticação e autorização com OAuth 2.0 e OIDC
Digamos que um usuário esteja tentando acessar um endpoint. O usuário pode ser:
- Uma pessoa de verdade
- Uma conta não humana (pod de aplicação, componente do sistema, pipeline de software ou uma entidade física ou lógica)
O endpoint pode ser:
- Uma API
- Um software (como um banco de dados)
- Um servidor físico ou virtual
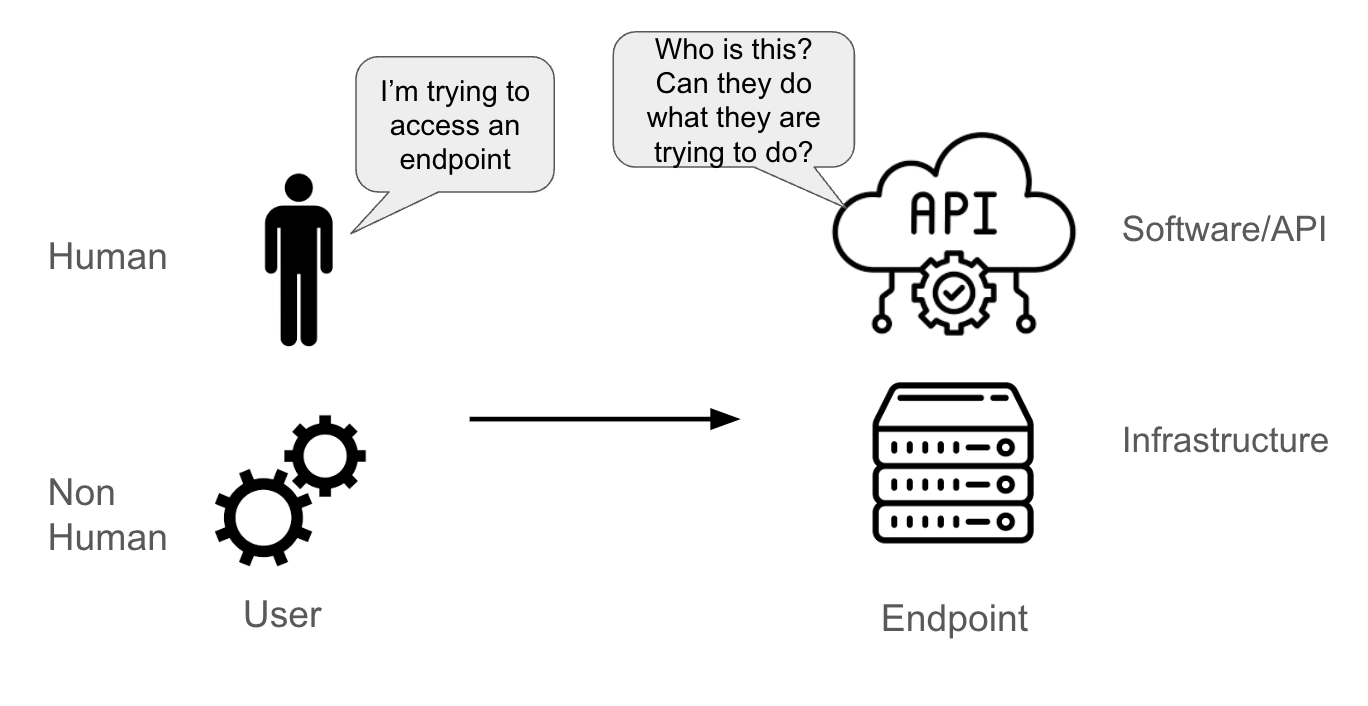
Quando o endpoint recebe uma solicitação do usuário, ele precisa conseguir entender:
- Quem está enviando a solicitação (essa é a parte da autenticação)
- O que esse usuário tem permissão para fazer (essa é a parte da autorização)
Há uma seção inteira na documentação oficial do Kubernetes sobre autenticação. O ponto principal dessa documentação é que a autenticação no Kubernetes se refere ao processo de autenticação de uma solicitação de API feita ao servidor da API do Kubernetes. Essas solicitações podem ser feitas com os comandos kubectl ou oc em um terminal, uma GUI ou por chamadas de API. Mas, no fim, tudo é enviado ao servidor da API.
Embora existam muitos protocolos e tecnologias de autenticação disponíveis (LDAP, SAML, Kerberos, entre outros), o método de autenticação de API mais bem-sucedido e comum é a combinação do OAuth 2.0 com o OpenID Connect (OIDC).
O OAuth 2.0 é um protocolo de autorização (e não de autenticação) projetado para conceder acesso a um conjunto de recursos (por exemplo, uma API remota ou dados de usuário). Para isso, o OAuth 2.0 usa um token de acesso, ou seja, um dado que representa a autorização para acessar um recurso em nome do usuário final.
O OpenID Connect (OIDC) é um protocolo de autenticação que amplia o framework do OAuth 2.0 adicionando uma camada de identificação. Ele fornece um mecanismo que solicita dados específicos do usuário, como nome ou endereço de e-mail, e permite que os usuários concedam ou neguem acesso a essas informações. A principal extensão do OAuth2 apresentada por esse protocolo é um campo extra que retorna com o token de acesso chamado de token de ID. Esse token é um JSON Web Token (JWT) com campos específicos, como o e-mail de um usuário, assinados pelo servidor.
O diagrama abaixo mostra as etapas realizadas quando um usuário tenta configurar um conjunto de ações em um cluster do Kubernetes usando o comando kubectl. O processo completo é mais complexo, mas está bem explicado na documentação oficial.
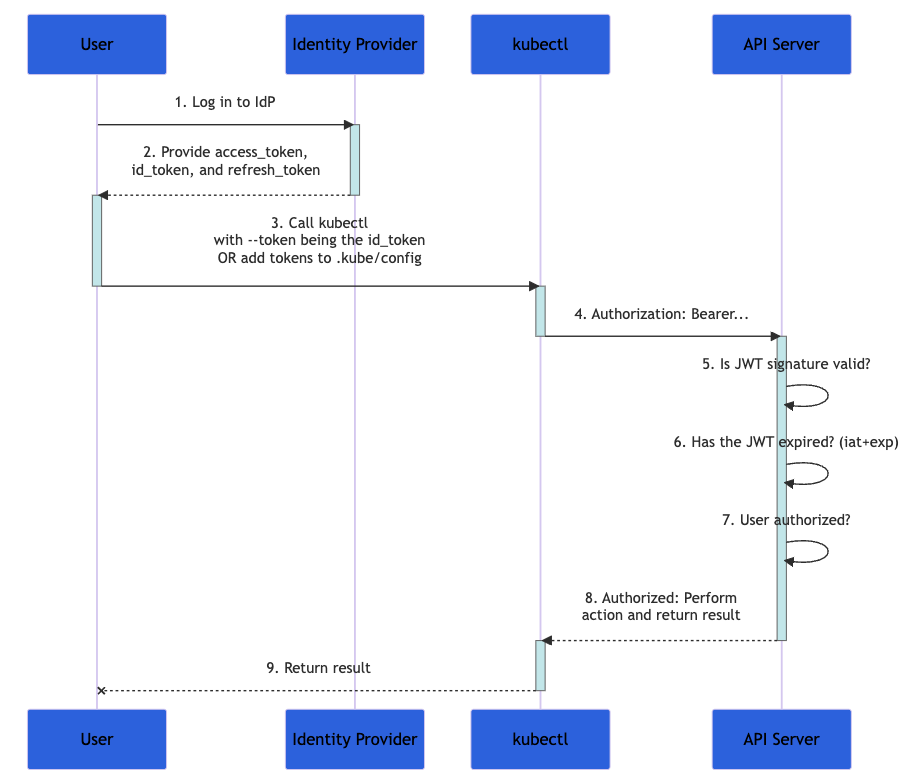
Legenda: um fluxograma da documentação do Kubernetes demonstrando o processo de autenticação.
- Primeiro, você acessa um provedor de identidade.
- O provedor de identidade fornece um
access_token, id_tokene umrefresh_token. - Com o
kubectl, use seuid_tokencom o parâmetro--tokenou adicione o token akubeconfig. - O
kubectlenvia oid_tokenem um cabeçalho chamado "Authorization" para o servidor da API. - O servidor da API verifica se a assinatura JWT é válida, se o
id_tokennão expirou e se o usuário tem autorização para essa transação. - O servidor da API retorna uma resposta para
kubectl, que dá feedback para você.
Como seu id_token contém todos os dados necessários para validar sua identidade, o Kubernetes não precisa mais interagir com o provedor de identidade. Essa é uma solução altamente escalável para a autenticação, especialmente quando cada solicitação é stateless.
O que é o controle de acesso baseado em função (RBAC)?
O controle de acesso baseado em função (RBAC) é uma maneira de regular o acesso de usuários individuais a recursos de rede e computadores com base nas funções deles em uma organização. Por exemplo, um administrador de sistema em uma plataforma pode ter o direito de fazer modificações em todo o ambiente (possivelmente impactando todas as aplicações no cluster). Mas se você for responsável pelo gerenciamento de somente uma aplicação no cluster, provavelmente só terá permissão para fazer modificações nessa aplicação.
A figura abaixo ilustra esses dois exemplos de usuários. O ícone verde pertence à equipe de RH, enquanto o ícone preto é um administrador da plataforma. O usuário do RH pode acessar somente os recursos do grupo de apps de RH, mas o administrador da plataforma pode acessar tudo que estiver na plataforma.
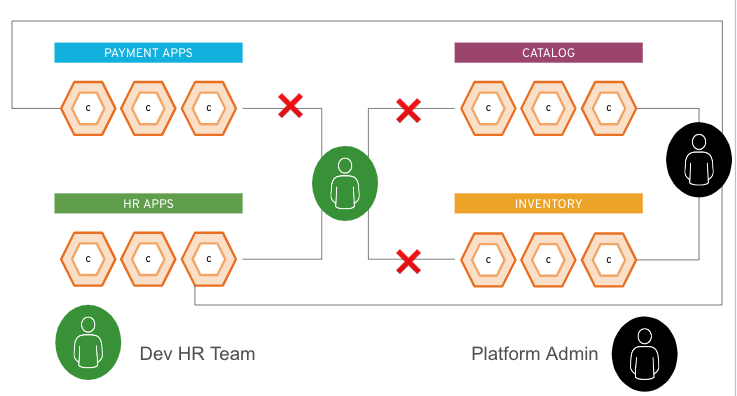
O usuário do RH recebe um token verde durante a etapa de autorização, e o administrador recebe um token preto. Como parte da interação com o endpoint (o cluster do Kubernetes ou a API do OpenShift), cada usuário adicionaria seu respectivo token (verde ou preto) às devidas solicitações. Com base nesse token, o cluster sabe quais aplicações cada usuário pode acessar.
Camada de transporte e endpoints
O mecanismo de transporte mais comum para chegar a um endpoint do Kubernetes é o Transport Layer Security (TLS), que fornece um túnel criptografado para HTTPS.
Se você for um administrador de sistemas de uma máquina virtual Linux ou Windows, sua metodologia de acesso para esses endpoints provavelmente será SSH ou RDP. Esses protocolos criptografam o tráfego entre você (usuário) e o endpoint (servidor Linux ou Windows). Da mesma forma, ao lidar com uma API, um software ou um Software como Serviço (SaaS) de terceiros, o mecanismo de transporte mais comum é o TLS.
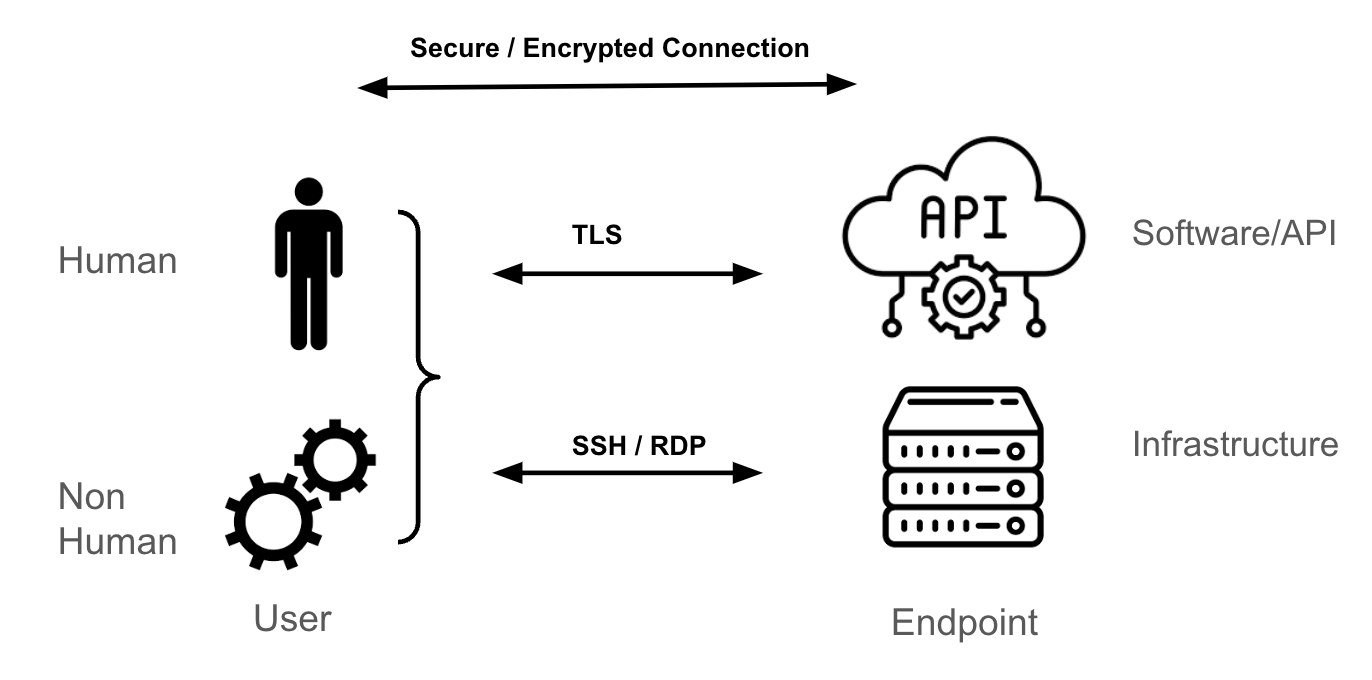
Este artigo não detalha como uma sessão segura e criptografada é estabelecida entre o endpoint e o usuário, mas é algo que depende de túneis e chaves (ou certificados) usados para autenticar os endpoints (usuário, endpoint ou ambos) e criptografar e descriptografar os pacotes enviados entre esses endpoints.
As camadas de acesso ao Kubernetes e OpenShift
Os três conceitos de autenticação, autorização e transporte são relativamente simples quando você os conhece. No entanto, em qualquer ambiente de TI, há várias camadas a serem consideradas, e é daí que vem grande parte da complexidade e confusão.
Em uma arquitetura do Kubernetes, existem três camadas principais:
- Camada de infraestrutura: computação, armazenamento e rede. Pode ser uma nuvem pública, um data center on-premise ou de colocation ou uma combinação de tudo isso.
- Camada do Kubernetes: responsável pela hospedagem e pelo gerenciamento de todas as aplicações em containers.
- Aplicações em containers: o grupo de containers que forma uma aplicação específica. Essas aplicações podem incluir soluções comerciais prontas para uso (COTS), de fornecedor de software independente (ISV), desenvolvidas internamente ou uma combinação entre elas.
Cada camada oferece e exige recursos de autenticação e autorização.
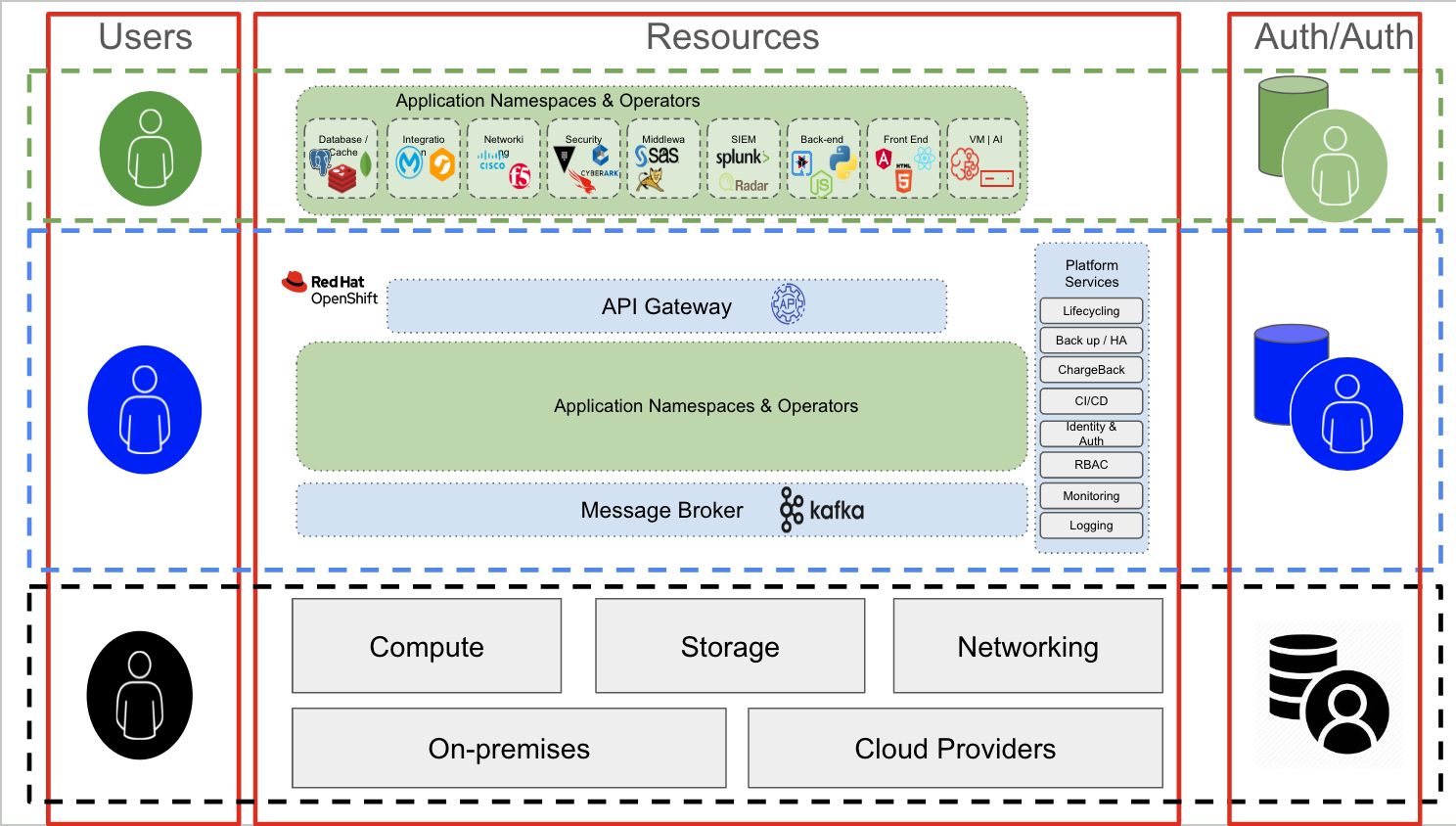
Autenticação e autorização na camada de infraestrutura
Geralmente, os usuários da camada de infraestrutura são administradores de sistemas que precisam de acesso a componentes específicos (armazenamento, rede, computação ou virtualização). Para acessar essa camada (a última da figura acima, em preto), um usuário administrativo normalmente se conecta a um servidor por SSH, usando interfaces dedicadas para os nós de armazenamento, rede ou computação (iLOs, iDRAC e assim por diante). O mecanismo de autenticação pode ser uma combinação de RADIUS/TACACS (redes), LDAP ou Kerberos (servidores e armazenamento) ou outros mecanismos de autenticação específicos do domínio.
Curiosamente, o mesmo usuário administrativo de infraestrutura pode usar uma aplicação (na camada verde) hospedada no OpenShift (camada azul) para realizar as atividades dele.
Por exemplo, o stack de gerenciamento de rede pode ser uma aplicação em containers em execução no OpenShift. Mas nesse contexto, o usuário administrativo é funcionalmente um usuário normal (verde) tentando acessar uma aplicação (o stack de gerenciamento de rede, neste exemplo). Os mecanismos de autenticação e autorização são diferentes nessa camada. Por exemplo, uma conexão com a aplicação é provavelmente feita por uma conexão TLS/SSL e pode exigir credenciais para acessar o console do stack de gerenciamento de rede.
Autenticação e autorização no OpenShift
Agora vamos subir um nível e observar a camada azul (isto é, a interação com o OpenShift ou o Kubernetes em geral), que significa se comunicar com o servidor da API do Kubernetes. Isso é válido tanto para usuários humanos quanto não humanos, não importa se estão usando um console de GUI ou um terminal. No final das contas, toda a interação com o OpenShift ou o Kubernetes passa pelo servidor da API.
A combinação OAuth2/OIDC faz todo o sentido para autenticação e autorização de APIs. Por isso, o OpenShift conta com um servidor OAuth2 integrado. Como parte da configuração desse servidor OAuth2, um provedor de identidade compatível precisa ser adicionado. O provedor de identidade ajuda o servidor OAuth2 a confirmar quem é o usuário. Quando essa parte for configurada, o OpenShift estará pronto para autenticar usuários.
No caso dos usuários autenticados, o OpenShift cria um token de acesso e retorna esse token para o usuário. Esse token é chamado de token de acesso OAuth. Um usuário pode usar esses tokens de acesso OAuth durante cada interação com a API do OpenShift até que ela expire, ou seja revogada.
Usuários e contas de serviço
Um usuário pode ser humano ou não. No OpenShift, existem funções conceitualmente diferentes que um usuário pode assumir:
- Usuários comuns: humanos que interagem com um cluster do Kubernetes.
- Usuários do sistema: humanos (como um administrador de plataforma) e componentes de cluster não humanos (por exemplo, o registro, vários nós de control plane e nós de aplicação).
- Outros usuários não humanos: incluem contas de serviço. Eles normalmente representam aplicações (dentro ou fora do cluster) que precisam interagir com a API do Kubernetes. Por exemplo, um pipeline que faz uso do GitLab, GitHub e Tekton usaria uma conta de serviço para interagir com o OpenShift.
Usuários e contas de serviço podem ser organizados em grupos no OpenShift. Os grupos são úteis ao gerenciar políticas de autorização para conceder permissões a vários usuários ao mesmo tempo. Por exemplo, você pode permitir que um grupo acesse objetos em um projeto em vez de conceder acesso a cada usuário individualmente.
Um usuário pode ser atribuído a um ou mais grupos, cada um representando um determinado conjunto de usuários. A maioria das organizações já tem grupos de usuários (por exemplo, em um servidor do Active Directory). É possível sincronizar registros de LDAP com registros de grupo internos do OpenShift.
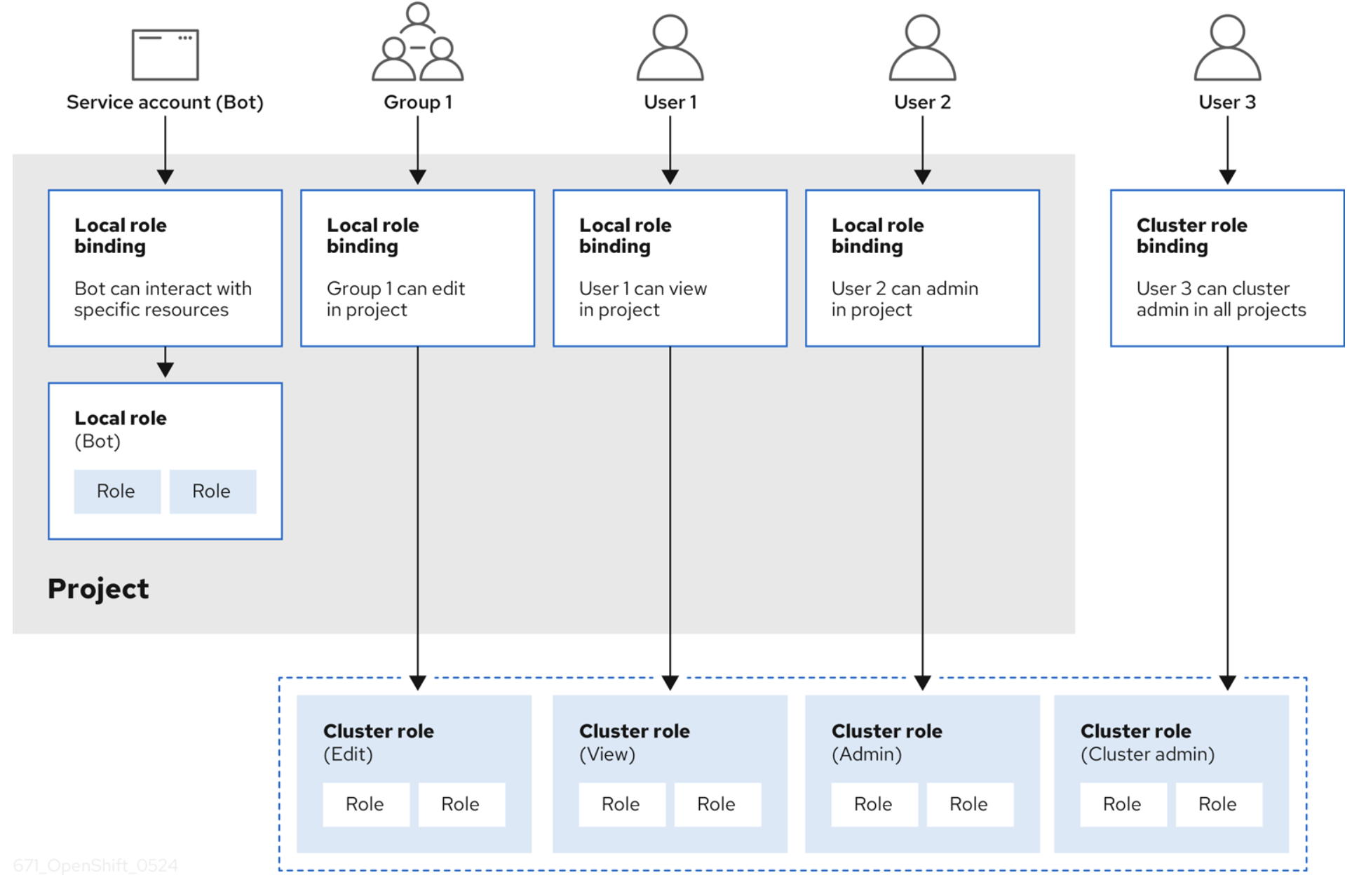
Autorização e controle de acesso baseado em função (RBAC)
Quando um usuário é autenticado e recebe um token de acesso OAuth2, ele ganha vários privilégios de acesso com base no RBAC. Um objeto de RBAC determina se um usuário tem permissão para executar uma determinada ação em um recurso. Um RBAC pode ser implementado em um cluster ou em um projeto.
Ele é gerenciado usando:
- Regras: conjuntos de verbos permitidos em um grupo de objetos. Eles são conhecidos coletivamente como CRUD: "create" (criar), "read" (ler), "update" (atualizar), "delete" (excluir). São as operações fundamentais do armazenamento persistente. No contexto de uma API RESTful, eles correspondem a POST, GET, PUT ou PATCH e DELETE do protocolo HTTP. Por exemplo, um usuário ou conta de serviço pode ter permissão para criar um pod.
- Funções: coleções de regras. Você pode associar, ou vincular, usuários e grupos a várias funções.
- Vinculações: associações entre usuários e grupos com uma função.
O OpenShift fornece funções predefinidas (cluster-admin, basic user e mais). Uma boa visão geral do RBAC usando regras, funções e vinculações é ilustrada na figura abaixo (extraída da documentação do OpenShift).
Autenticação e autorização de recursos na camada do OpenShift
Um recurso na camada do Kubernetes (geralmente um pod) pode exigir acesso para realizar uma das seguintes ações:
- Interagir com a API do Kubernetes
- Interagir com o host (a camada de infraestrutura) onde o recurso está hospedado
- Interagir com recursos fora do cluster (por exemplo, um recurso de nuvem)
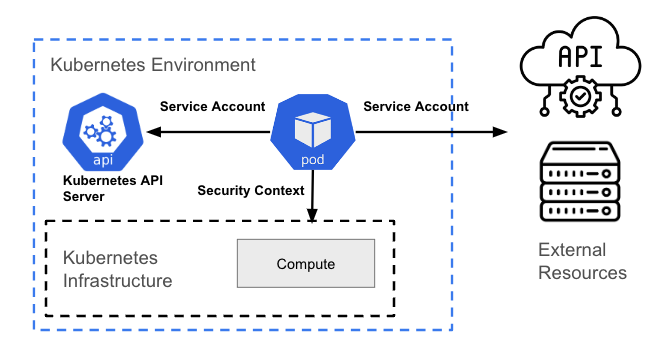
Interação com a API do Kubernetes
Qualquer interação com a API do Kubernetes exige algum tipo de autenticação usando OAuth. Um pod representa um usuário não humano, então ele necessita de uma conta de serviço para interagir com o servidor da API.
Por padrão, um pod é associado a uma conta de serviço, e uma credencial (token) para essa conta de serviço é inserida no sistema de arquivos de cada container no pod, em /var/run/secrets/kubernetes.io/serviceaccount/token. Existe um debate se esse modelo é uma boa ideia ou não, então isso é configurável no OpenShift e pode ser aplicado usando políticas com ferramentas como o ACS.
Interação com a camada do host/infraestrutura do Kubernetes
Esse tipo de interação não depende de chamadas de API do Kubernetes. Na verdade, ela está relacionada ao gerenciamento de permissões no nível do processo (permissões no nível do Linux) do host subjacente.
As ações (ou permissões) que um pod está autorizado a realizar na infraestrutura subjacente, além dos recursos que ele pode acessar, são definidas pelas restrições de contexto de segurança (SCC). Uma SCC é um recurso do OpenShift que restringe um pod a um grupo de recursos e é semelhante ao recurso de contexto de segurança do Kubernetes.
Por exemplo, um processo pode ou não ter permissão para criar um arquivo em um determinado caminho, ou pode não ter permissões de gravação (somente de leitura) em um arquivo existente. A principal finalidade de ambos é limitar o acesso de um pod ao ambiente do host. Você pode usar uma SCC para controlar as permissões dos pods, quase da mesma maneira que o controle de acesso baseado em função é usado para gerenciar privilégios de usuários.
Interação com recursos externos
Às vezes, um pod precisa acessar um recurso fora do cluster. Por exemplo, ele pode exigir acesso a um armazenamento de objetos (como um bucket S3) para dados ou arquivos de log. Para isso, você precisa entender como o recurso autentica os usuários e o que é necessário criar no pod que se comunicará com esse recurso.
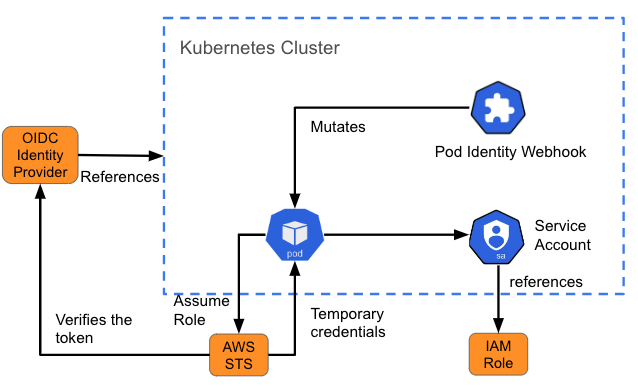
O gerenciamento de identidade e acesso (IAM) da Amazon para funções de contas de serviço (IRSA) é um exemplo desse tipo de modelo que fornece aos pods credenciais de acesso a serviços na AWS. Quando um pod é criado, um webhook injeta variáveis (o caminho para o token de conta de serviço do Kubernetes e o ARN da função assumida) no pod que faz referência à conta de serviço. Isso também é chamado de "mutação". Se a função assumida pelo IAM tiver as permissões necessárias da AWS, o pod poderá executar as operações do SDK da AWS usando credenciais temporárias do STS.
Autenticação e autorização para aplicações em containers no OpenShift
A camada final são as aplicações em containers. Semelhante à camada anterior, cada container pode tentar acessar:
- A API do Kubernetes
- Outra API fornecida por outro container dentro do cluster ou por um recurso fora do cluster
- Uma conexão sem ser de API, como contatar uma porta específica para acesso ao banco de dados
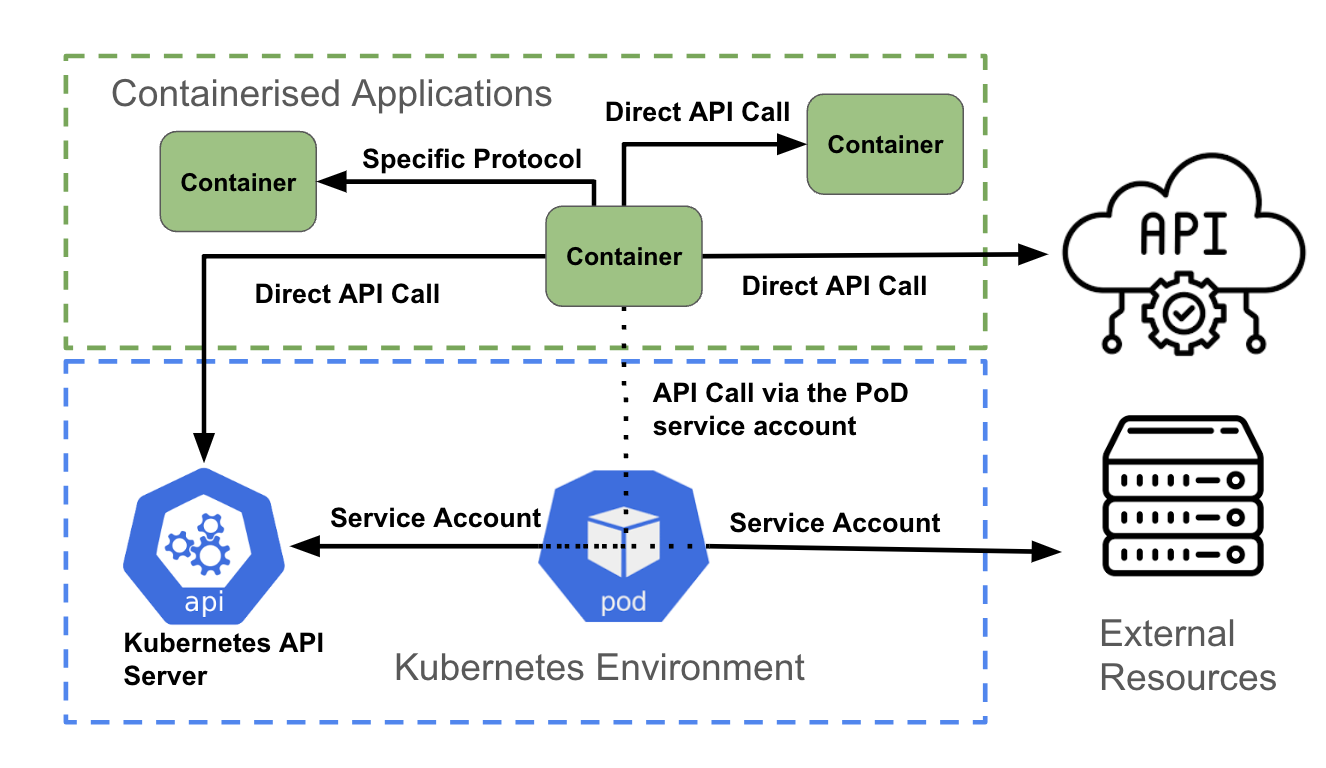
Como a figura acima ilustra, um container acessando uma API pode:
- Acessar diretamente outra API usando credenciais de autenticação associadas à aplicação (usando os segredos do Kubernetes, por exemplo).
- Acessar diretamente um endpoint sem ser de API, usando os mecanismos de autenticação compatíveis com o endpoint.
- Usar a conta de serviço do pod.
Chamada de API direta
Um container pode acessar a API do Kubernetes ao obter as variáveis de ambiente KUBERNETES_SERVICE_HOST e KUBERNETES_SERVICE_PORT_HTTPS. Para tráfego de API que não seja do Kubernetes, uma aplicação pode usar uma biblioteca de cliente (por exemplo, uma API da AWS) ou uma integração personalizada criada pelo desenvolvedor.
Comunicação não baseada em API
Uma aplicação talvez precise se conectar a um banco de dados para recuperar ou enviar dados. Nesse caso, a autenticação é normalmente tratada como parte do código dentro do container e pode ser atualizada no runtime usando variáveis de ambiente, segredos, ConfigMaps etc.
Uso da conta de serviço
A maneira recomendada de fazer a autenticação no servidor da API do Kubernetes é com uma credencial de conta de serviço. A maioria das linguagens de codificação tem um conjunto de bibliotecas de clientes do Kubernetes compatíveis. Com base nessas bibliotecas, as credenciais da conta de serviço de um pod são usadas para se comunicar com o servidor da API. O OpenShift monta automaticamente uma conta de serviço dentro de cada pod, permitindo que ele acesse o token abrangido.
Para chamadas de API que não são do Kubernetes, um container também pode usar a conta de serviço do pod ao fazer a autenticação em um serviço de API externo.
Autenticação e autorização
Um computador precisa saber quem é um usuário e o que ele tem permissão para fazer. Esse é o domínio da autenticação e da autorização, que você agora entende como são gerenciadas no Kubernetes e no OpenShift.
Agradeço a Shane Boulden e Derek Waters pela revisão minuciosa deste artigo e pelo feedback.
Sobre o autor

Simon Delord is a Solution Architect at Red Hat. He works with enterprises on their container/Kubernetes practices and driving business value from open source technology. The majority of his time is spent on introducing OpenShift Container Platform (OCP) to teams and helping break down silos to create cultures of collaboration.Prior to Red Hat, Simon worked with many Telco carriers and vendors in Europe and APAC specializing in networking, data-centres and hybrid cloud architectures.Simon is also a regular speaker at public conferences and has co-authored multiple RFCs in the IETF and other standard bodies.
Navegue por canal

Automação
Últimas novidades em automação de TI para empresas de tecnologia, equipes e ambientes

Inteligência artificial
Descubra as atualizações nas plataformas que proporcionam aos clientes executar suas cargas de trabalho de IA em qualquer ambiente

Nuvem híbrida aberta
Veja como construímos um futuro mais flexível com a nuvem híbrida

Segurança
Veja as últimas novidades sobre como reduzimos riscos em ambientes e tecnologias

Edge computing
Saiba quais são as atualizações nas plataformas que simplificam as operações na borda

Infraestrutura
Saiba o que há de mais recente na plataforma Linux empresarial líder mundial

Aplicações
Conheça nossas soluções desenvolvidas para ajudar você a superar os desafios mais complexos de aplicações
Virtualização
O futuro da virtualização empresarial para suas cargas de trabalho on-premise ou na nuvem