La sicurezza è uno dei componenti chiave di un'architettura containerizzata.
Benché presenti molte sfaccettature (puoi consultare l'elenco degli argomenti nella documentazione ufficiale di OpenShift qui), alcuni dei requisiti di base sono l'autenticazione e l'autorizzazione. In questo articolo spiego come funzionano l'autenticazione e l'autorizzazione in Kubernetes e in Red Hat OpenShift, illustrando le interazioni tra i diversi livelli di un ecosistema Kubernetes, inclusi il livello dell'infrastruttura, il livello Kubernetes e il livello delle applicazioni containerizzate.
Cosa sono l'autenticazione e l'autorizzazione?
In sostanza, in un sistema informatico l'autenticazione è un modo per rispondere alla domanda: "Chi sei?", mentre l'autorizzazione risponde alla domanda: "Ora che so che sei tu, cosa puoi fare?"
In base alla mia esperienza, la maggior parte delle difficoltà di comprensione di questo argomento in Kubernetes è dovuta al numero di componenti (utenti, API, container, pod) che interagiscono tra loro. Per parlare di autenticazione, è necessario chiarire innanzitutto quali componenti sono coinvolti. Esegui l'autenticazione al cluster Kubernetes? Oppure si tratta di un microservizio che tenta di accedere a un altro microservizio dello stesso ambiente? È forse una risorsa cloud esterna rispetto al cluster Kubernetes? O magari è un endpoint (una risorsa cloud, un sistema o una persona) che tenta di accedere e di utilizzare una delle applicazioni in esecuzione nel cluster?
Autenticazione e autorizzazione con OAuth 2.0 e OIDC
Supponiamo che un utente stia tentando di accedere a un endpoint. Tale utente può essere:
- Una persona reale
- Un account non umano (un pod applicativo, un componente di sistema, una pipeline software o un'entità fisica o logica)
L'endpoint può essere:
- Un'API
- Un elemento software (ad esempio un database)
- Un server fisico o virtuale
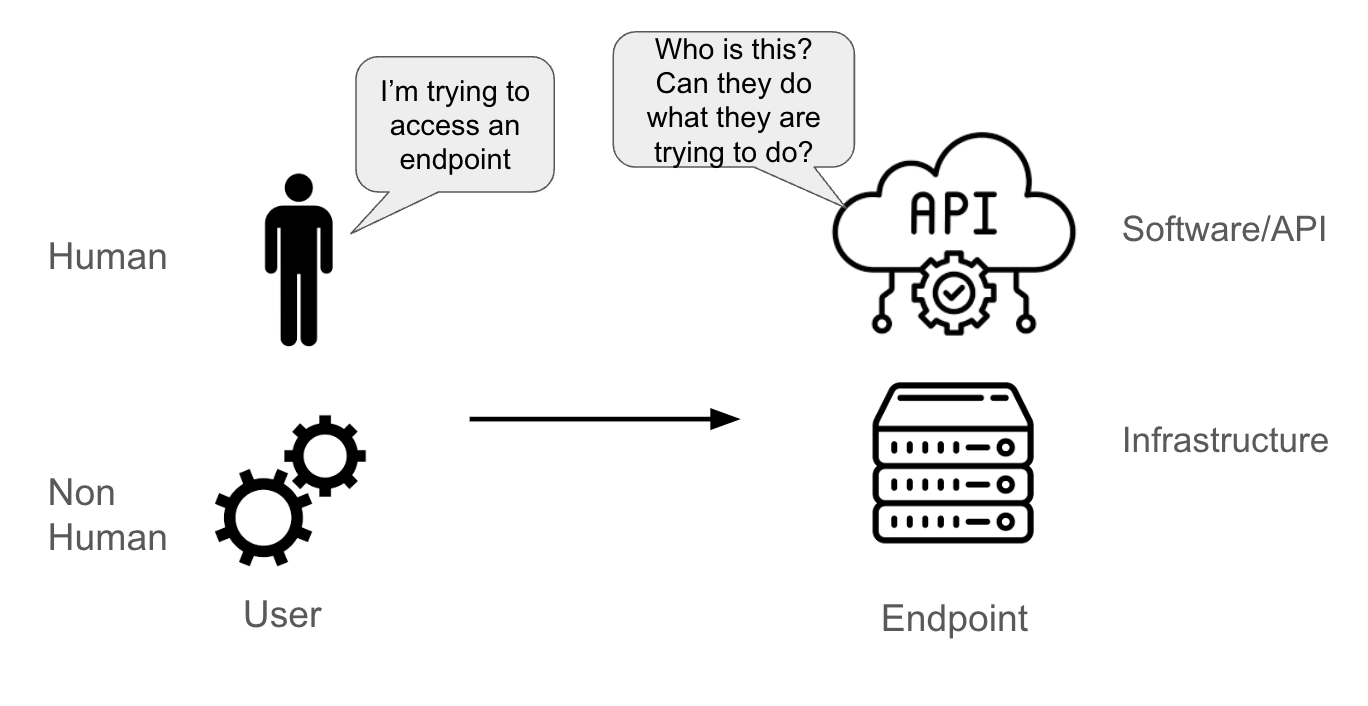
Quando l'endpoint riceve una richiesta dall'utente, deve essere in grado di comprendere:
- Chi sta inviando la richiesta (è un aspetto dell'autenticazione)
- Quali azioni l'utente è autorizzato a compiere (questo è l'aspetto relativo all'autorizzazione)
Nella documentazione ufficiale di Kubernetes è disponibile un'intera sezione dedicata all'autenticazione. Tale documentazione sottolinea come in Kubernetes l'autenticazione si riferisce al processo di autenticazione di una richiesta API inviata al server API Kubernetes. Queste richieste possono essere effettuate tramite i comandi kubectl o oc in un terminale, una GUI o tramite chiamate API, ma sostanzialmente tutto viene inviato al server API.
Sebbene siano disponibili molte tecnologie e protocolli di autenticazione (LDAP, SAML, Kerberos e altri), il metodo di autenticazione API più efficace e diffuso è la combinazione di OAuth 2.0 e OpenID Connect (OIDC).
OAuth 2.0 è un protocollo di autorizzazione (non di autenticazione) progettato per concedere l'accesso a un set di risorse (ad esempio un'API remota o dei dati utente). Per concedere l'accesso, OAuth 2.0 si avvale di un token di accesso, ovvero dei dati specifici che rappresentano l'autorizzazione ad accedere a una risorsa per conto dell'utente finale.
OpenID Connect (OIDC) è invece un protocollo di autenticazione che amplia il framework OAuth 2.0 con l'aggiunta di un livello di identità e di un meccanismo per richiedere informazioni specifiche sull'utente, come il nome o l'indirizzo e-mail, e che permette agli utenti di concedere o negare l'accesso a tali informazioni. L'estensione principale del protocollo OAuth2 è un campo aggiuntivo restituito con il token di accesso, denominato token ID, ovvero un JSON Web Token (JWT) con campi specifici, come l'email di un utente, firmati dal server.
Il diagramma seguente mostra i passaggi eseguiti quando un utente tenta di configurare una serie di azioni in un cluster Kubernetes utilizzando il comando kubectl. L'intero processo è in realtà più complesso, ma è ben documentato nella documentazione ufficiale.
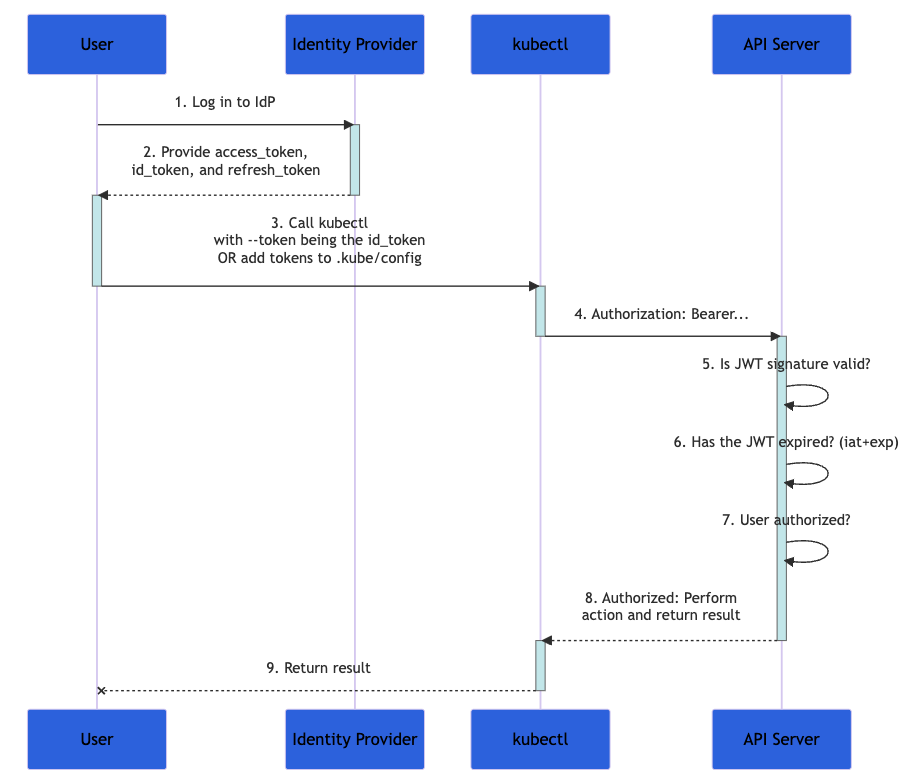
Didascalia: diagramma di flusso tratto dalla documentazione di Kubernetes che illustra il processo di autenticazione
- Innanzitutto, accedi a un provider di identità
- Il provider di identità fornisce un
access_token, un id_tokene unrefresh_token - Con
kubectl, usa il tuoid_tokencon il parametro--tokeno aggiungi il token akubeconfig kubectlinviaid_tokenal server API, in un'intestazione denominata "Authorization"- Il server API verifica che la firma JWT sia valida, che
id_tokennon sia scaduto e che l'utente sia autorizzato per questa transazione - Il server API restituisce una risposta a
kubectl, che ti restituisce un feedback
Poiché il tuo id_token contiene tutti i dati necessari per convalidare la tua identità, Kubernetes non richiede ulteriori interazioni con il provider di identità. Questa soluzione per l'autenticazione è altamente scalabile, soprattutto quando ogni richiesta è stateless.
Cos'è il controllo degli accessi basato sui ruoli (RBAC)?
Il controllo degli accessi basato sui ruoli (RBAC) è un metodo per concedere l'accesso ai computer o alle risorse di rete in base ai ruoli dei singoli utenti all'interno di un'organizzazione. Un amministratore di sistema, ad esempio, su una piattaforma potrebbe avere il diritto di apportare modifiche all'intero ambiente, con possibili ripercussioni su ogni applicazione del cluster. Se, tuttavia, sei responsabile della gestione di una sola applicazione nel cluster, potrai probabilmente apportare modifiche solo a tale applicazione.
La figura seguente mostra questi due utenti di esempio. L'icona verde è un utente che appartiene al team delle risorse umane (HR), mentre l'icona nera è un amministratore della piattaforma. L'utente HR può accedere solo alle risorse incluse nel gruppo delle app HR, mentre l'amministratore può accedere a qualsiasi elemento della piattaforma.
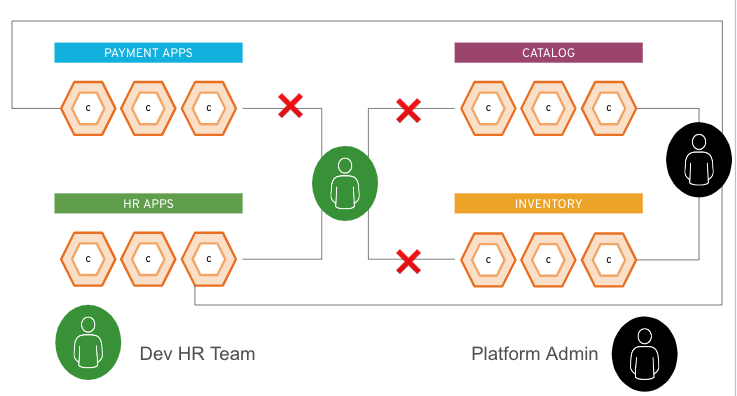
Durante la fase di autorizzazione, all'utente HR viene concesso un token verde e all'amministratore un token nero. Durante l'interazione con l'endpoint (il cluster Kubernetes o l'API OpenShift), ogni utente aggiunge il proprio token (verde o nero) alle proprie richieste. In base al token aggiunto, il cluster riconosce le applicazioni alle quali ogni utente può accedere.
Livello di trasporto ed endpoint
Il meccanismo di trasporto più comune per raggiungere un endpoint Kubernetes è la crittografia TLS (Transport Layer Security), che fornisce un tunnel crittografato per HTTPS.
Se sei un amministratore di sistema per una macchina virtuale Linux o Windows, per accedere a questi endpoint utilizzi probabilmente la metodologia di accesso SSH o RDP. Questi protocolli crittografano il traffico tra l'utente e l'endpoint (il server Linux o Windows). Allo stesso modo, quando si tratta di API, software o Software-as-a-Service (SaaS) di terze parti, il meccanismo di trasporto più comune è il TLS.
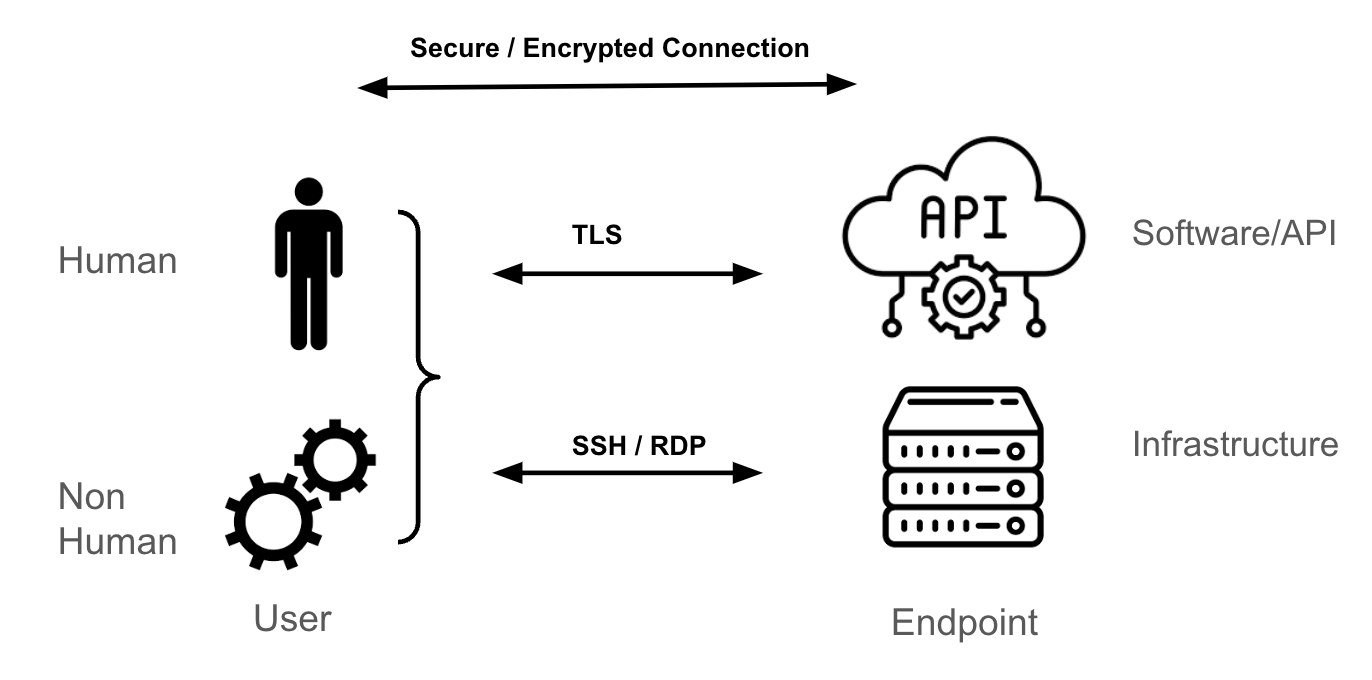
Le modalità di definizione di una sessione sicura e crittografata tra l'endpoint e l'utente va oltre lo scopo di questo blog, ma è bene sapere che si affida a tunnel e chiavi (o certificati) utilizzati per autenticare gli endpoint (l'utente, l'endpoint o entrambi) e crittografare e decrittografare i pacchetti trasmessi tra gli endpoint.
I livelli Kubernetes e l'accesso OpenShift
I tre concetti di autenticazione, autorizzazione e trasporto sono relativamente semplici, se li conosci. In ogni ambiente IT, tuttavia, ci sono più livelli da considerare, ed è qui che nascono complessità e confusione.
In un'architettura Kubernetes esistono tre livelli principali:
- Livello dell'infrastruttura: elaborazione, storage e rete. Questo livello può essere costituito da un cloud pubblico, un datacenter on premise o in colocation o da una combinazione di questi.
- Livello Kubernetes: è responsabile dell'hosting e della gestione di tutte le applicazioni containerizzate.
- Applicazioni containerizzate: il gruppo di container che costituisce un'applicazione specifica. Le applicazioni possono includere software commerciali standard, ISV (Independent Software Vendor), applicazioni sviluppate internamente o una loro combinazione.
Ogni livello fornisce e richiede funzionalità di autenticazione e autorizzazione.
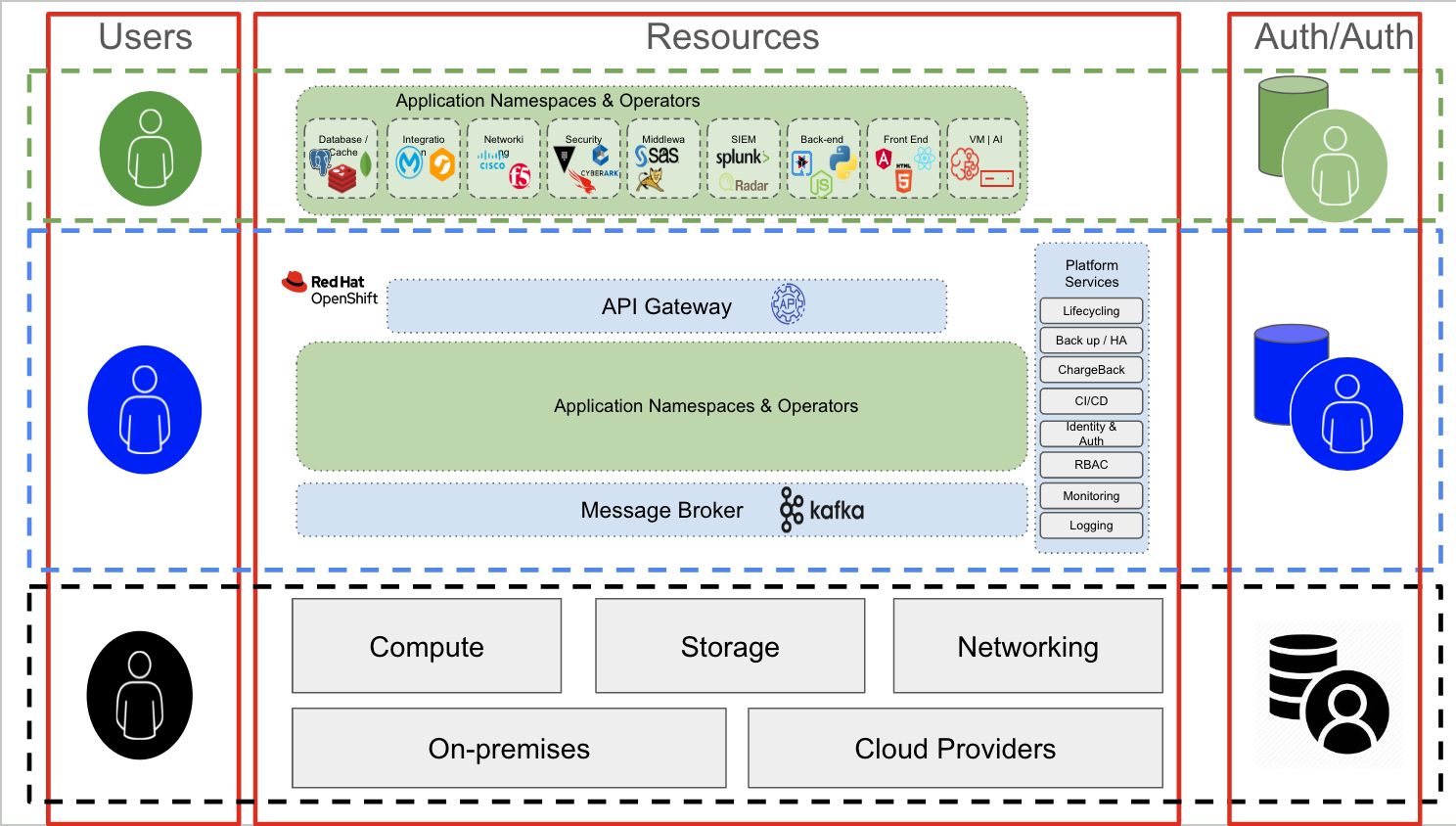
Autenticazione e autorizzazione a livello dell'infrastruttura
Gli utenti del livello dell'infrastruttura sono in genere amministratori di sistema che richiedono l'accesso a componenti specifici (storage, rete, elaborazione o virtualizzazione). Per accedere a questo livello (nell'immagine è il livello inferiore, in nero), un utente amministrativo si connette in genere a un server tramite SSH, utilizzando interfacce dedicate ai nodi di storage, di rete o di elaborazione (iLO, iDRAC e così via). Il meccanismo di autenticazione può essere una combinazione di RADIUS/TACACS (rete), LDAP o Kerberos (server e storage) o di altri meccanismi di autenticazione specifici del dominio.
È interessante notare come, per svolgere le proprie attività, lo stesso utente amministratore dell'infrastruttura può utilizzare un'applicazione (livello verde) ospitata su OpenShift (livello blu).
Ad esempio, lo stack di gestione della rete può essere costituito da un'applicazione containerizzata eseguita su OpenShift. In questo contesto, tuttavia, in termini funzionali l'utente amministratore è un normale utente (verde) che tenta di accedere a un'applicazione (nel nostro esempio, lo stack di gestione della rete). A questo livello, i meccanismi di autenticazione e autorizzazione sono diversi. Ad esempio, la connessione all'applicazione avviene probabilmente tramite una connessione TLS/SSL e può richiedere le credenziali per accedere alla console dello stack di gestione della rete.
Autenticazione e autorizzazione in OpenShift
Spostandoci verso i livelli superiori, osserviamo il livello blu (ovvero l'interazione generica con OpenShift o Kubernetes), che corrisponde alla comunicazione con il server API Kubernetes. Ciò vale sia per gli utenti umani che per quelli non umani, che utilizzino una console GUI o un terminale. Di fatto, tutte le interazioni con OpenShift o Kubernetes passano attraverso il server API.
Poiché la combinazione OAuth2/OIDC è perfetta per l'autenticazione e l'autorizzazione delle API, OpenShift dispone di un server OAuth2 integrato. La configurazione del server OAuth2 deve prevedere l'aggiunta di un provider di identità supportato, che aiuta il server OAuth2 a confermare l'identità dell'utente. Completata questa configurazione, OpenShift è pronto per l'autenticazione degli utenti.
Per ogni utente autenticato, OpenShift crea un token di accesso che viene poi restituito all'utente. Questo token è chiamato token di accesso OAuth. Un utente può utilizzare i token di accesso OAuth durante ogni interazione con l'API OpenShift fino alla loro scadenza o revoca.
Utenti e account di servizio
Esistono utenti umani e non umani. In OpenShift, ogni utente può assumere ruoli concettualmente diversi:
- Utenti standard: persone che interagiscono con un cluster Kubernetes.
- Utenti del sistema: componenti umani (ad esempio un amministratore della piattaforma) e componenti non umani del cluster (ad esempio il registro, vari nodi del piano di controllo e nodi applicativi).
- Altri utenti non umani: includono gli account di servizio e in genere rappresentano applicazioni (interne o esterne al cluster) che devono interagire con l'API Kubernetes. Una pipeline che utilizza GitLab, GitHub e Tekton, ad esempio, utilizza un account di servizio per interagire con OpenShift.
In OpenShift, gli utenti e gli account di servizio possono essere organizzati in gruppi, un'opzione utile quando si gestiscono i criteri per concedere autorizzazioni a più utenti contemporaneamente. Ad esempio, puoi consentire a un gruppo di accedere agli oggetti di un progetto invece di concedere l'accesso a ogni singolo utente.
Un utente può essere assegnato a uno o più gruppi, ognuno dei quali rappresenta un determinato insieme di utenti. La maggior parte delle organizzazioni dispone già di gruppi di utenti, ad esempio in un server Active Directory. È possibile sincronizzare i record LDAP con i record del gruppo OpenShift interno.
Controllo degli accessi basato sui ruoli (RBAC) e autorizzazione
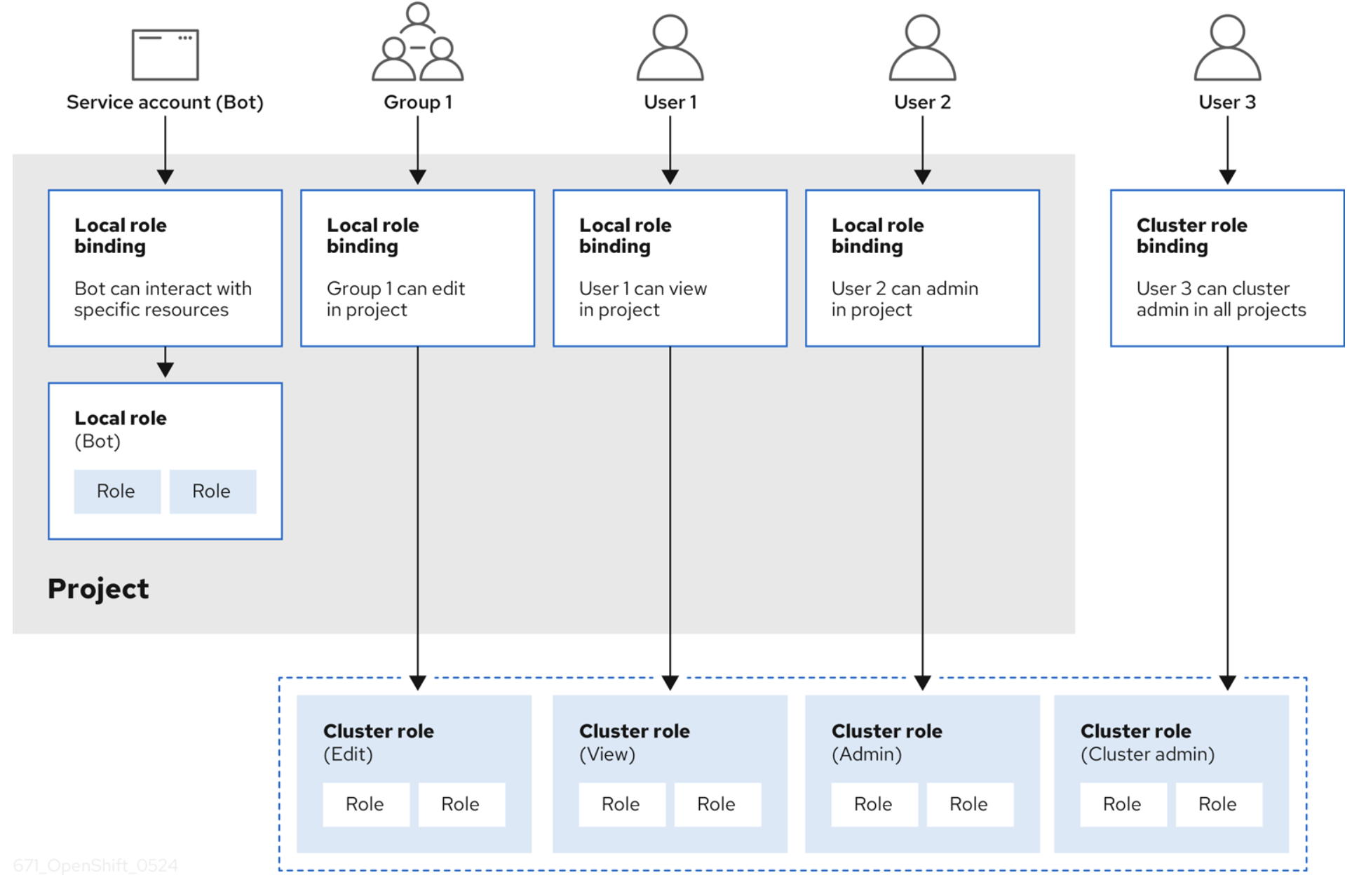
A un utente che si è autenticato e ha ricevuto un token di accesso OAuth2, viene concesso un set di privilegi di accesso basati su RBAC. Un oggetto RBAC determina se un utente può eseguire una determinata azione su una risorsa. Una definizione RBAC può essere valida per l'intero cluster o l'intero progetto.
Il controllo RBAC viene gestito utilizzando:
- Regole: insiemi di verbi consentiti che possono essere eseguiti su un insieme di oggetti, noti collettivamente come CRUD: create, read, update, delete. Sono le operazioni fondamentali eseguibili sullo storage permanente. Nel contesto di un'API RESTful, corrispondono a POST, GET, PUT o PATCH e DELETE del protocollo HTTP.Ad esempio, un utente o un account di servizio può essere autorizzato a creare un pod.
- Ruoli: raccolte di regole. È possibile associare (bind) utenti e gruppi a più ruoli
- Associazioni: associazioni tra utenti e gruppi con un ruolo
OpenShift fornisce ruoli predefiniti (permanente, utente di base e altro). La figura seguente (estratta dalla documentazione di OpenShift) illustra una panoramica completa del controllo RBAC con regole, ruoli e associazioni.
Autenticazione e autorizzazione dalle risorse al livello OpenShift
Una risorsa all'interno del livello Kubernetes (in genere un pod) può richiedere l'accesso per eseguire una delle azioni seguenti:
- Interazione con l'API Kubernetes
- Interazione con l'host (il livello dell'infrastruttura) su cui è ospitata la risorsa
- Interazione con le risorse esterne al cluster (ad esempio una risorsa cloud)
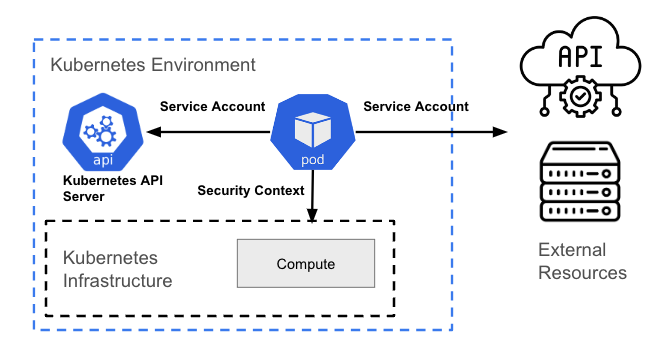
Interazione con l'API Kubernetes
Qualsiasi interazione con l'API Kubernetes richiede un'autenticazione tramite OAuth. Poiché rappresenta un utente non umano, un pod richiede un account di servizio per interagire con il server API.
Per impostazione predefinita, un pod è associato a un account di servizio; la credenziale (token) dell'account di servizio viene inserita nel file system di ogni container presente nel pod, nel percorso /var/run/secrets/kubernetes.io/serviceaccount/token.È in corso una discussione sul fatto che questo modello sia o meno una buona idea; attualmente è configurabile in OpenShift e può essere applicato tramite criteri con strumenti come ACS.
Interazione con il livello dell'infrastruttura host/Kubernetes
Questo tipo di interazione non si basa sulle chiamate API Kubernetes, ma è correlato alla gestione delle autorizzazioni a livello di processo (autorizzazioni a livello Linux) dell'host alla base.
Il mapping delle azioni (autorizzazioni) che un pod può eseguire nell'infrastruttura alla base e delle risorse a cui può accedere viene eseguito utilizzando i vincoli del contesto di sicurezza (SCC). Un vincolo SCC è una risorsa OpenShift che limita un pod a un gruppo di risorse ed è simile alla risorsa del contesto di sicurezza Kubernetes.
Ad esempio, un processo può disporre o meno dell'autorizzazione per creare un file in un determinato percorso, oppure può non disporre delle autorizzazioni di scrittura per un file esistente (potrebbe avere solo le autorizzazioni di lettura). La finalità principale in entrambi i casi è limitare l'accesso di un pod all'ambiente host. Un vincolo SCC può essere utilizzato per controllare le autorizzazioni del pod, così come il controllo degli accessi basato sui ruoli è utilizzato per gestire i privilegi degli utenti.
Interazione con risorse esterne
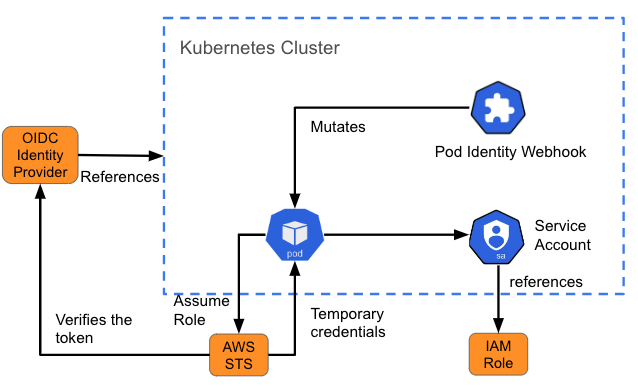
A volte un pod deve accedere a una risorsa esterna al cluster. Ad esempio, potrebbe richiedere l'accesso a un object store (come un bucket S3) per i dati o file di registro. In questi casi, è necessario comprendere in che modo la risorsa autentica gli utenti e cosa è necessario integrare nel pod che comunicherà con la risorsa.
La gestione delle identità e degli accessi (IAM) di Amazon per i ruoli degli account di servizio (IRSA) è un esempio di progettazione che fornisce ai pod un set di credenziali per accedere ai servizi su AWS. Quando viene creato un pod, un webhook inserisce le variabili (il percorso del token dell'account di servizio Kubernetes e l'ARN del ruolo assunto) nel pod di riferimento dell'account di servizio. Questa attività è chiamata anche "mutazione". Se il ruolo assunto da IAM dispone delle autorizzazioni AWS richieste, il pod può eseguire le operazioni SDK di AWS utilizzando le credenziali STS temporanee.
Autenticazione e autorizzazione per le applicazioni containerizzate in OpenShift
Il livello finale è quello delle applicazioni containerizzate. Analogamente al livello precedente, ogni container può tentare di accedere a:
- L'API Kubernetes
- Un'altra API fornita da un altro container all'interno del cluster o da una risorsa esterna al cluster
- Una connessione non API, ad esempio per contattare una porta specifica per l'accesso al database
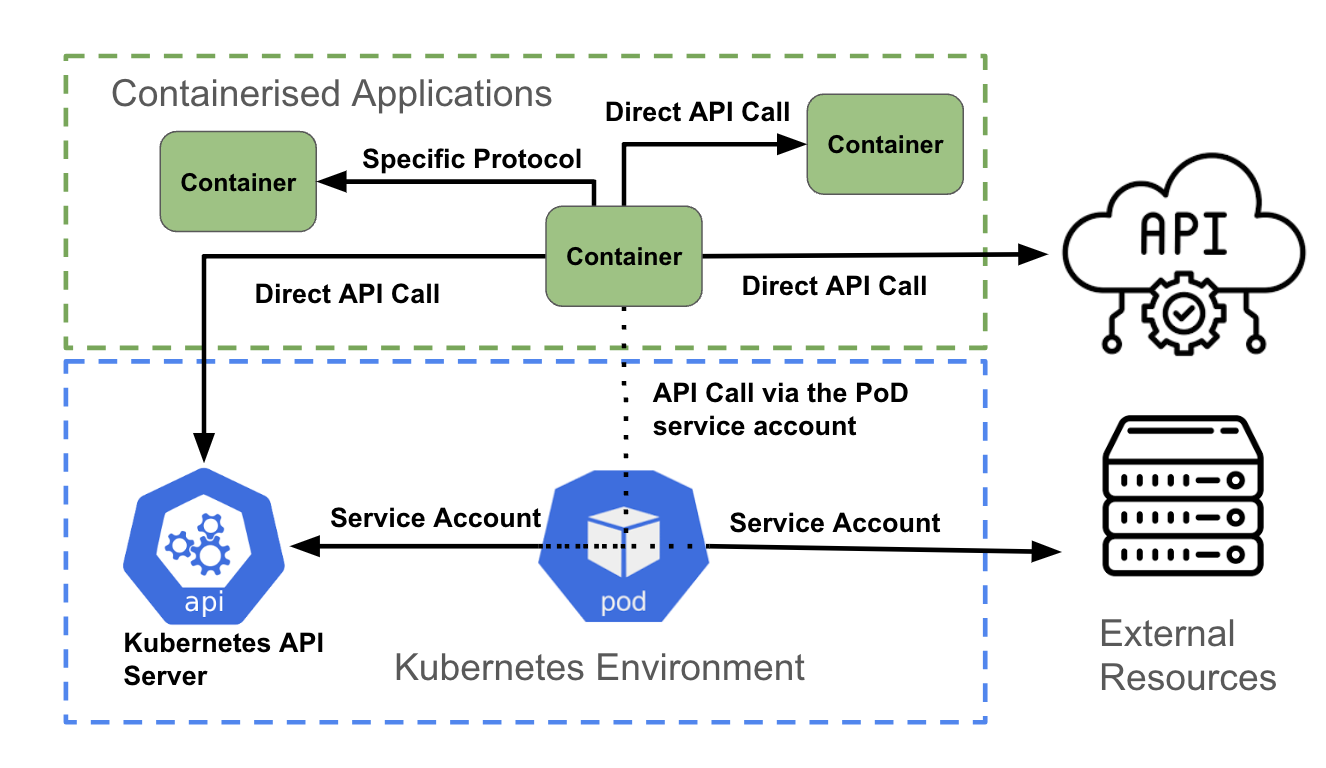
Come illustrato nella figura precedente, un container che accede a un'API può:
- Accedere direttamente a un'altra API utilizzando le credenziali di autenticazione associate all'applicazione (ad esempio utilizzando i segreti Kubernetes)
- Accedere direttamente a un endpoint non API, utilizzando i meccanismi di autenticazione supportati dall'endpoint
- Utilizzare l'account del servizio pod
Eseguire una chiamata API diretta
Un container può accedere all'API Kubernetes recuperando le variabili di ambiente KUBERNETES_SERVICE_HOST e KUBERNETES_SERVICE_PORT_HTTPS. Per il traffico diverso dalle API Kubernetes, un'applicazione può utilizzare una libreria client (ad esempio un'API AWS) o un'integrazione personalizzata creata dallo sviluppatore.
Comunicazione non basata su API
Un'applicazione potrebbe doversi connettere a un database per recuperare o inviare dati. In questo caso, l'autenticazione viene in genere gestita come parte del codice all'interno del container e aggiornata in fase di runtime utilizzando variabili di ambiente, segreti, ConfigMaps e così via.
Utilizzo dell'account di servizio
Il metodo consigliato per l'autenticazione al server API Kubernetes è l'utilizzo di una credenziale dell'account di servizio. La maggior parte dei linguaggi di programmazione dispone di un set di librerie client Kubernetes supportate. A partire da queste librerie, le credenziali dell'account di servizio di un pod vengono utilizzate per comunicare con il server API. In ogni pod, OpenShift monta automaticamente un account di servizio che consente di accedere al token dell'ambito.
Per le chiamate API non Kubernetes, un container può utilizzare anche l'account di servizio del pod durante l'autenticazione a un servizio API esterno.
Autenticazione e autorizzazione
Un computer deve poter riconoscere chi è un utente e quali azioni è autorizzato a fare. È questo il dominio dell'autenticazione e dell'autorizzazione e con questo articolo hai compreso come viene gestito all'interno di Kubernetes e OpenShift.
Ringrazio Shane Boulden e Derek Waters per l'attenta rilettura e i commenti approfonditi su questo articolo.
Sull'autore

Simon Delord is a Solution Architect at Red Hat. He works with enterprises on their container/Kubernetes practices and driving business value from open source technology. The majority of his time is spent on introducing OpenShift Container Platform (OCP) to teams and helping break down silos to create cultures of collaboration.Prior to Red Hat, Simon worked with many Telco carriers and vendors in Europe and APAC specializing in networking, data-centres and hybrid cloud architectures.Simon is also a regular speaker at public conferences and has co-authored multiple RFCs in the IETF and other standard bodies.
Ricerca per canale

Automazione
Novità sull'automazione IT di tecnologie, team e ambienti

Intelligenza artificiale
Aggiornamenti sulle piattaforme che consentono alle aziende di eseguire carichi di lavoro IA ovunque

Hybrid cloud open source
Scopri come affrontare il futuro in modo più agile grazie al cloud ibrido

Sicurezza
Le ultime novità sulle nostre soluzioni per ridurre i rischi nelle tecnologie e negli ambienti

Edge computing
Aggiornamenti sulle piattaforme che semplificano l'operatività edge

Infrastruttura
Le ultime novità sulla piattaforma Linux aziendale leader a livello mondiale

Applicazioni
Approfondimenti sulle nostre soluzioni alle sfide applicative più difficili
Virtualizzazione
Il futuro della virtualizzazione negli ambienti aziendali per i carichi di lavoro on premise o nel cloud