Uno de los elementos más importantes de una arquitectura basada en contenedores es la seguridad.
Hay muchos aspectos que se relacionan con ella (puedes consultar la lista de temas en la documentación oficial de OpenShift aquí), pero los requisitos más básicos son la autenticación y la autorización. En este artículo, explicaré el funcionamiento de ellas en Kubernetes y Red Hat OpenShift. Abarcaré las interacciones entre las diferentes capas de un ecosistema de Kubernetes, que incluyen la de infraestructura, la de Kubernetes y la de aplicaciones en contenedores.
¿Qué son la autenticación y la autorización?
En términos sencillos, la autenticación en un sistema informático responde a la pregunta "¿Quién eres?", mientras que la autorización pregunta "Ahora que sé que eres tú, ¿qué permisos tienes?"
En mi experiencia, cuando se trata de Kubernetes, la dificultad para comprender este tema surge por la cantidad de elementos (usuarios, interfaces de programación de aplicaciones, contenedores y pods) que interactúan entre sí. Cuando se trata de la autenticación, primero debes aclarar qué elementos están involucrados. ¿Te estás autenticando en el clúster de Kubernetes? ¿Se trata de un microservicio que intenta acceder a otro dentro del entorno? ¿Es un recurso de nube ubicado fuera del clúster de Kubernetes? ¿O es un extremo (un recurso de nube, un sistema o una persona) que intenta acceder a una de las aplicaciones que se ejecutan en el clúster y utilizarla?
Autenticación y autorización con OAuth 2.0 y OIDC
Supongamos que un usuario intenta acceder a un extremo. El usuario podría ser:
- una persona;
- una cuenta no humana (un pod de una aplicación, un elemento del sistema, un canal del software o una entidad física o lógica).
El extremo podría ser:
- una interfaz de programación de aplicaciones (API);
- un software (como una base de datos);
- un servidor físico o virtual.
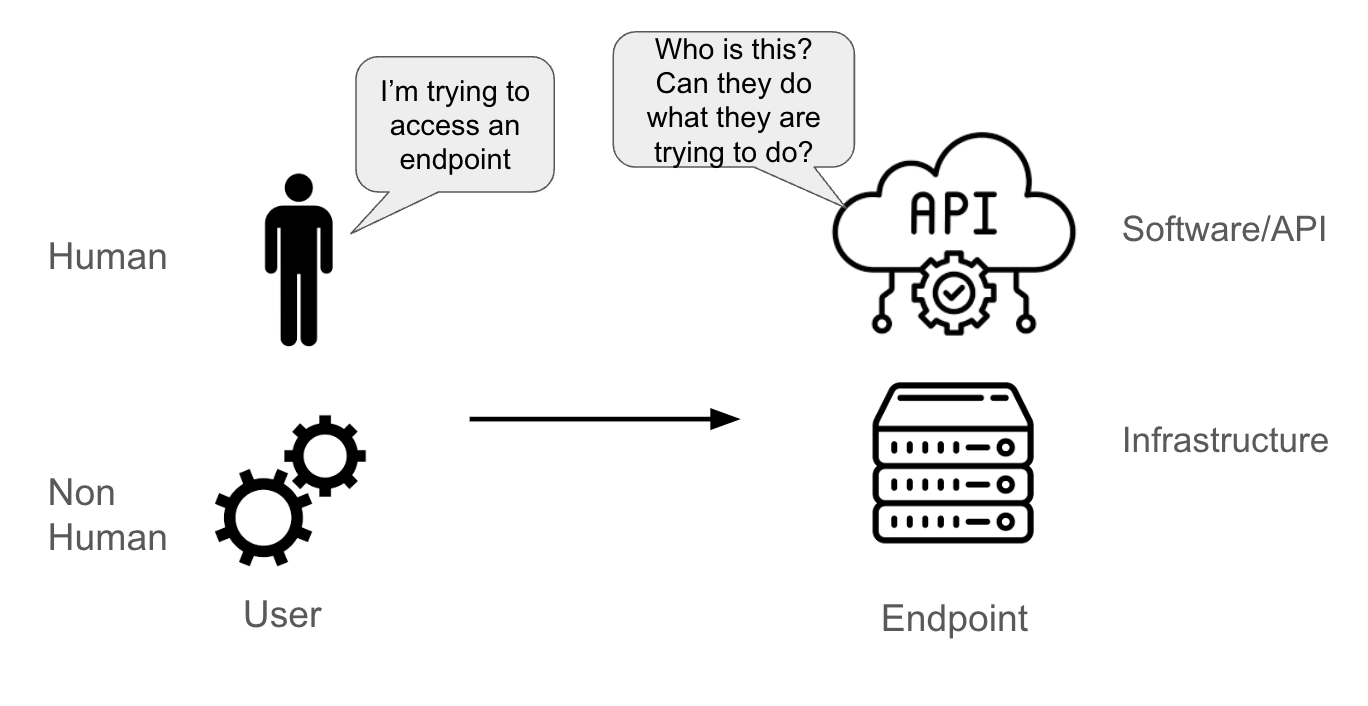
Cuando el extremo recibe una solicitud del usuario, debe ser capaz de comprender:
- quién envía la solicitud (esta es la parte de la autenticación);
- cuáles son los permisos que tiene el usuario (esta es la parte de la autorización).
En la documentación oficial de Kubernetes hay una sección completa sobre la autenticación, en la que la idea principal es que la autenticación en Kubernetes se refiere al proceso para autenticar una solicitud de API dirigida al servidor de API de Kubernetes. Esas solicitudes se pueden realizar desde los comandos kubectl u oc en un terminal, una interfaz gráfica de usuario (GUI) o mediante llamadas a la API, pero, básicamente, todo se envía al servidor de la API.
Si bien hay muchas tecnologías y protocolos de autenticación disponibles (LDAP, SAML, Kerberos y más), el método de autenticación de API más exitoso y común es la combinación de OAuth 2.0 y OpenID Connect (OIDC).
OAuth 2.0 es un protocolo de autorización (no de autenticación) que está diseñado para otorgar acceso a un conjunto de recursos (por ejemplo, a una API remota o a datos de los usuarios). Para lograr esto, el protocolo usa un token de acceso, que son datos que representan la autorización para acceder a un recurso en nombre del usuario final.
OpenID Connect es un protocolo de autenticación que amplía el marco de OAuth 2.0 al proporcionar una capa de identidad sobre este. Ofrece un mecanismo para solicitar información específica del usuario, como el nombre o la dirección de correo electrónico, y permite a los usuarios otorgar o denegar el acceso a esta información. La ampliación principal que hace el protocolo sobre OAuth 2.0 es un campo adicional que se entrega con el token de acceso y se denomina ID token. Este es un token web JSON (JWT) con campos específicos, como el correo electrónico de un usuario, firmado por el servidor.
En el siguiente diagrama, se muestran los pasos que se deben seguir cuando un usuario intenta configurar un conjunto de acciones en un clúster de Kubernetes con el comando kubectl. El proceso completo es más complejo y se detalla en la documentación oficial.
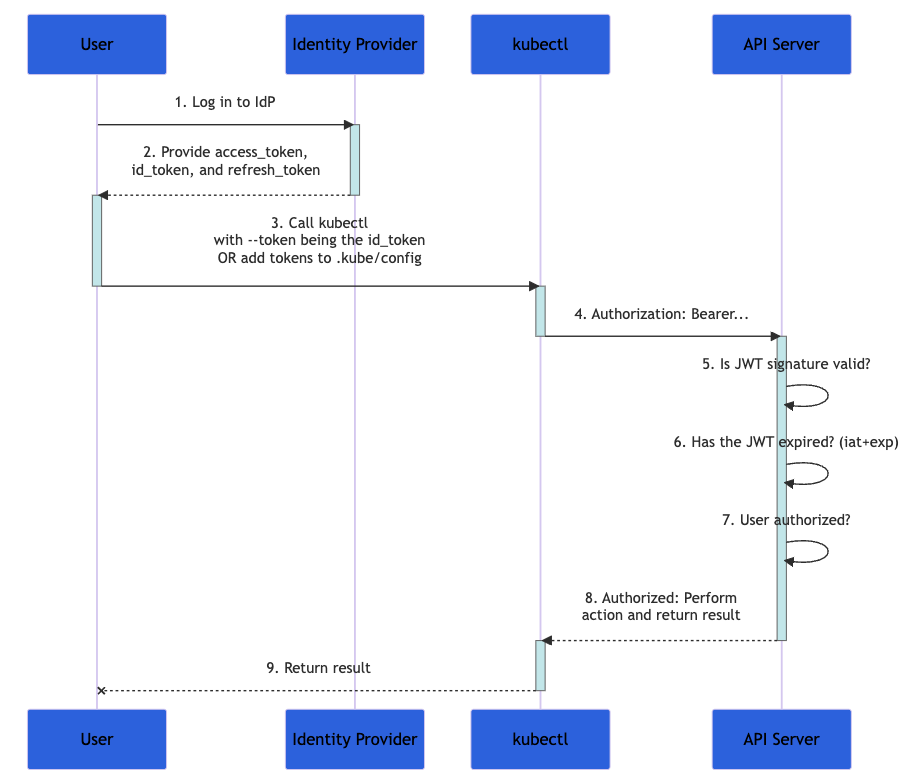
Pie de imagen: Diagrama de flujo de la documentación de Kubernetes en donde se demuestra el proceso de autenticación
- Primero, inicia sesión en un proveedor de identidad.
- Este proveedor proporciona los tokens
access_token, id_tokenyrefresh_token. - Con el comando
kubectl, usa tuid_tokencon el parámetro--token, o agrégalo akubeconfig. - El comando
kubectlenvía elid_tokenen una cabecera denominada "Authorization" al servidor de la API. - Este comprueba que la firma JWT sea válida, que el
id_tokenno haya caducado y que el usuario esté autorizado para esta operación. - El servidor da una respuesta al comando
kubectl, que te proporciona comentarios.
Debido a que tu id_token contiene todos los datos necesarios para validar tu identidad, Kubernetes no necesita interactuar más con el proveedor de identidades. Esta solución para la autenticación es altamente flexible, especialmente cuando ninguna de las solicitudes tiene estado.
¿Qué es el control de acceso basado en funciones?
El control de acceso basado en funciones (RBAC) es un método para regular el acceso a los recursos informáticos o de red según las funciones de los usuarios individuales dentro de una empresa. Por ejemplo, un administrador del sistema en una plataforma puede tener permiso para realizar modificaciones en todo el entorno (lo que podría afectar a todas las aplicaciones del clúster). Sin embargo, si eres el responsable de administrar solo una aplicación en el clúster, probablemente solo tengas permitido realizar modificaciones en esa aplicación.
En la siguiente figura, se muestran dos ejemplos de usuarios. El ícono verde es un usuario que pertenece al equipo de recursos humanos y el ícono negro es un administrador de la plataforma. El usuario de recursos humanos puede acceder solo a los recursos del grupo de aplicaciones de su área, pero el administrador de la plataforma puede acceder a todo lo que se encuentre dentro de ella.
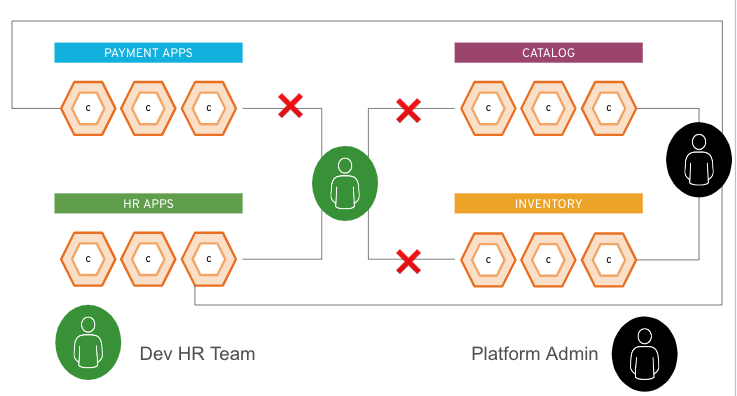
Al usuario de recursos humanos se le otorga un token verde durante el paso de autorización, y al de administrador se le otorga un token negro. Como parte de su interacción con el extremo (el clúster de Kubernetes o la API de OpenShift), cada usuario agregaría su token (verde o negro) a sus solicitudes. Con ellos, el clúster sabe a qué aplicaciones puede acceder cada usuario.
Capa de transporte y extremos
El mecanismo de transporte más común para llegar a un extremo de Kubernetes es la seguridad de la capa de transporte (TLS), que proporciona un túnel cifrado para HTTPS.
Si eres un administrador de sistemas de una máquina virtual de Linux o de Windows, tu metodología de acceso a esos extremos probablemente sea SSH o RDP. Estos protocolos cifran el tráfico entre tú (el usuario) y el extremo (el servidor de Linux o de Windows). De manera similar, cuando se trata de una API, un software o un software como servicio (SaaS) de terceros, el mecanismo de transporte más común es TLS.
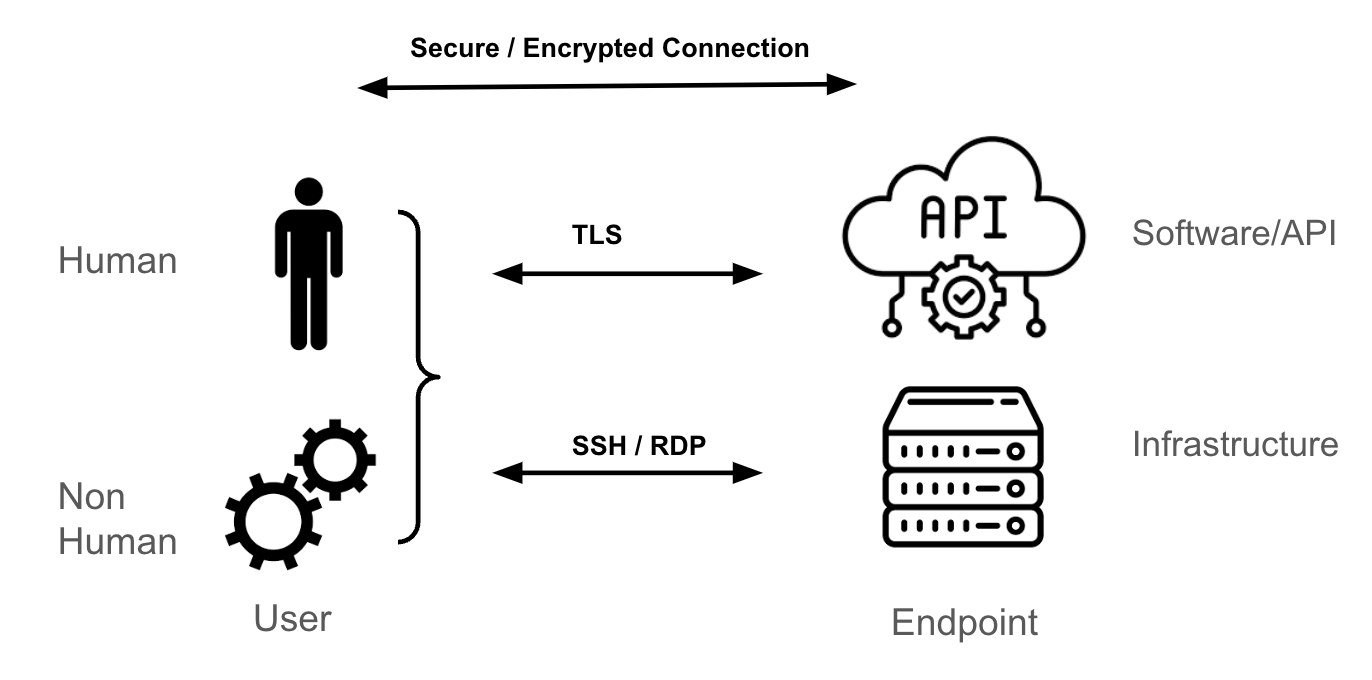
En este blog no se explica la forma en que se establece una sesión segura y cifrada entre el extremo y el usuario, pero se basa en túneles y claves (o certificados) que se usan para autenticar los extremos (ya sea el usuario, el extremo o ambos), además de cifrar y descifrar los paquetes que se envían entre los extremos.
Capas de acceso de Kubernetes y OpenShift
Una vez que los conoces, los tres conceptos de autenticación, autorización y transporte son relativamente sencillos. Sin embargo, en cualquier entorno de TI, hay varias capas que se deben tener en cuenta, y aquí es donde surge gran parte de la complejidad y la confusión.
En una arquitectura de Kubernetes, hay tres capas principales:
- Capa de infraestructura: incluye la informática, el almacenamiento y las redes. Puede ser una nube pública, un centro de datos local o de colocación o una combinación de todos estos.
- Capa de Kubernetes: allí se alojan y se gestionan todas las aplicaciones en contenedores.
- Aplicaciones en contenedores: son un grupo de contenedores que forman aplicaciones específicas. Estas pueden incluir las comerciales listas para usar (COTS), las de proveedores de software independientes (ISV), las desarrolladas de forma interna o cualquier combinación de ellas.
Cada capa proporciona y requiere funciones de autenticación y autorización.
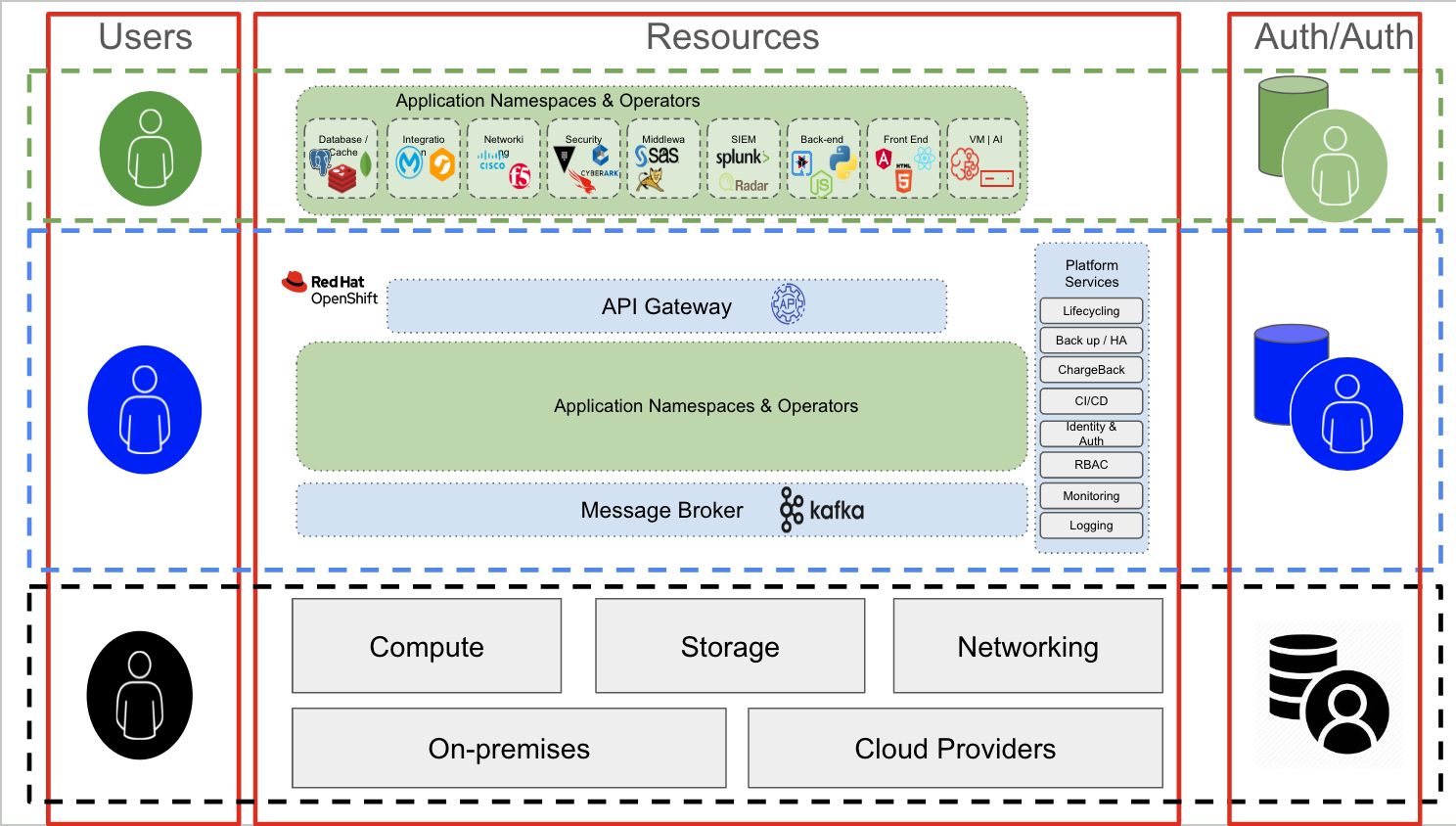
Autenticación y autorización en la capa de infraestructura
Los usuarios de la capa de infraestructura suelen ser administradores de sistemas que requieren acceso a elementos específicos (ya sea de almacenamiento, de redes, de informática o de virtualización). Para acceder a esta (la capa inferior negra de la figura anterior), un usuario administrativo suele conectarse a un servidor con SSH, usando interfaces exclusivas para los nodos de almacenamiento, de redes o de informática (iLO, iDRAC, etc.). El mecanismo de autenticación puede ser una combinación de RADIUS/TACACS (redes), el protocolo ligero de acceso a directorios (LDAP) o Kerberos (servidores y almacenamiento) u otros mecanismos específicos del área.
Curiosamente, el mismo usuario administrativo de la infraestructura puede usar una aplicación (en la capa verde), alojada en OpenShift (la capa azul) para realizar sus actividades.
Por ejemplo, la stack de gestión de redes puede ser una aplicación en contenedores que se ejecuta en OpenShift. Pero en ese contexto, el usuario de administración es, en la práctica, un usuario normal (verde) que intenta acceder a una aplicación (la stack de administración de redes en este ejemplo). Los mecanismos de autenticación y autorización son diferentes en esta capa. Por ejemplo, para conectarse a la aplicación, probablemente se debe utilizar una conexión TLS/SSL y pueden requerirse credenciales para acceder a la consola de la stack de gestión de la red.
Autenticación y autorización en OpenShift
Para subir en las capas y centrarte en la capa azul (es decir, interactuar con OpenShift o Kubernetes en general), debes comunicarte con el servidor de la API de Kubernetes. Esto es así tanto para usuarios humanos como no humanos, ya sea que estén usando una consola GUI o un terminal. Básicamente, toda interacción con OpenShift o Kubernetes pasa por el servidor de la API.
La combinación de OAuth 2.0 y OIDC es adecuada para la autenticación y autorización de la API, por lo que OpenShift cuenta con un servidor OAuth 2.0 integrado. Como parte de la configuración del servidor OAuth 2.0, se debe agregar un proveedor de identidad compatible. Este proveedor ayuda al servidor a confirmar quién es el usuario. Una vez que se haya configurado esta parte, OpenShift está listo para autenticar a los usuarios.
Para los usuarios autenticados, OpenShift crea un token de acceso y lo envía al usuario. Se denomina token de acceso de OAuth 2.0. Un usuario puede usar este token durante cada interacción con la API de OpenShift hasta que caduque o se revoque.
Usuarios y cuentas de servicio
Un usuario puede ser humano o no humano. En OpenShift, hay funciones conceptualmente diferentes que cualquier usuario puede adoptar:
- Usuarios regulares: son personas que interactúan con un clúster de Kubernetes.
- Usuarios del sistema: se trata de personas (por ejemplo, un administrador de plataforma) y elementos de un clúster no humano (por ejemplo, el registro, varios nodos de plano de control y de aplicación).
- Otros usuarios no humanos: incluyen las cuentas de servicio. En general, representan aplicaciones (dentro o fuera del clúster) que deben interactuar con la API de Kubernetes. Por ejemplo, un canal que usa GitLab, GitHub y Tekton usaría una cuenta de servicio para interactuar con OpenShift.
Los usuarios y las cuentas de servicio se pueden organizar en grupos dentro de OpenShift. Los grupos son útiles cuando se gestionan las políticas de autorización para otorgar permisos a varios usuarios a la vez. Por ejemplo, puedes permitir que un grupo acceda a los objetos dentro de un proyecto en lugar de otorgar acceso a cada usuario.
Un usuario puede asignarse a uno o más grupos, cada uno de los cuales representa un conjunto determinado. La mayoría de las empresas ya tienen grupos (por ejemplo, en un servidor de Active Directory). Es posible sincronizar los registros de LDAP con los registros de los grupos internos de OpenShift.
Control de acceso basado en funciones y autorización
Cuando un usuario se ha autenticado correctamente y ha recibido un token de acceso de OAuth 2.0, se le otorga un conjunto de privilegios de acceso que se basan en RBAC. Un objeto RBAC determina si un usuario tiene permiso para realizar una determinada acción en un recurso. Una definición de RBAC puede ser válida para todo el clúster o el proyecto.
El control de acceso basado en funciones se gestiona mediante:
- Reglas: son acciones que se permiten en un conjunto de objetos. Estos se conocen colectivamente como crear, leer, actualizar y eliminar (CRUD). Son las operaciones básicas del almacenamiento permanente. En el contexto de una API de RESTful, corresponden a los métodos POST, GET, PUT o PATCH y DELETE del protocolo HTTP. Por ejemplo, un usuario o una cuenta de servicio pueden tener permiso para crear un pod.
- Funciones: son conjuntos de reglas. Puedes asociar o vincular usuarios y grupos a varias funciones.
- Enlaces: se asocian los usuarios y los grupos a una función.
OpenShift proporciona funciones predefinidas (administrador del clúster, usuario básico y mucho más). En la siguiente figura (que se extrajo de la documentación de OpenShift), puedes ver una buena descripción general del RBAC con reglas, funciones y enlaces.
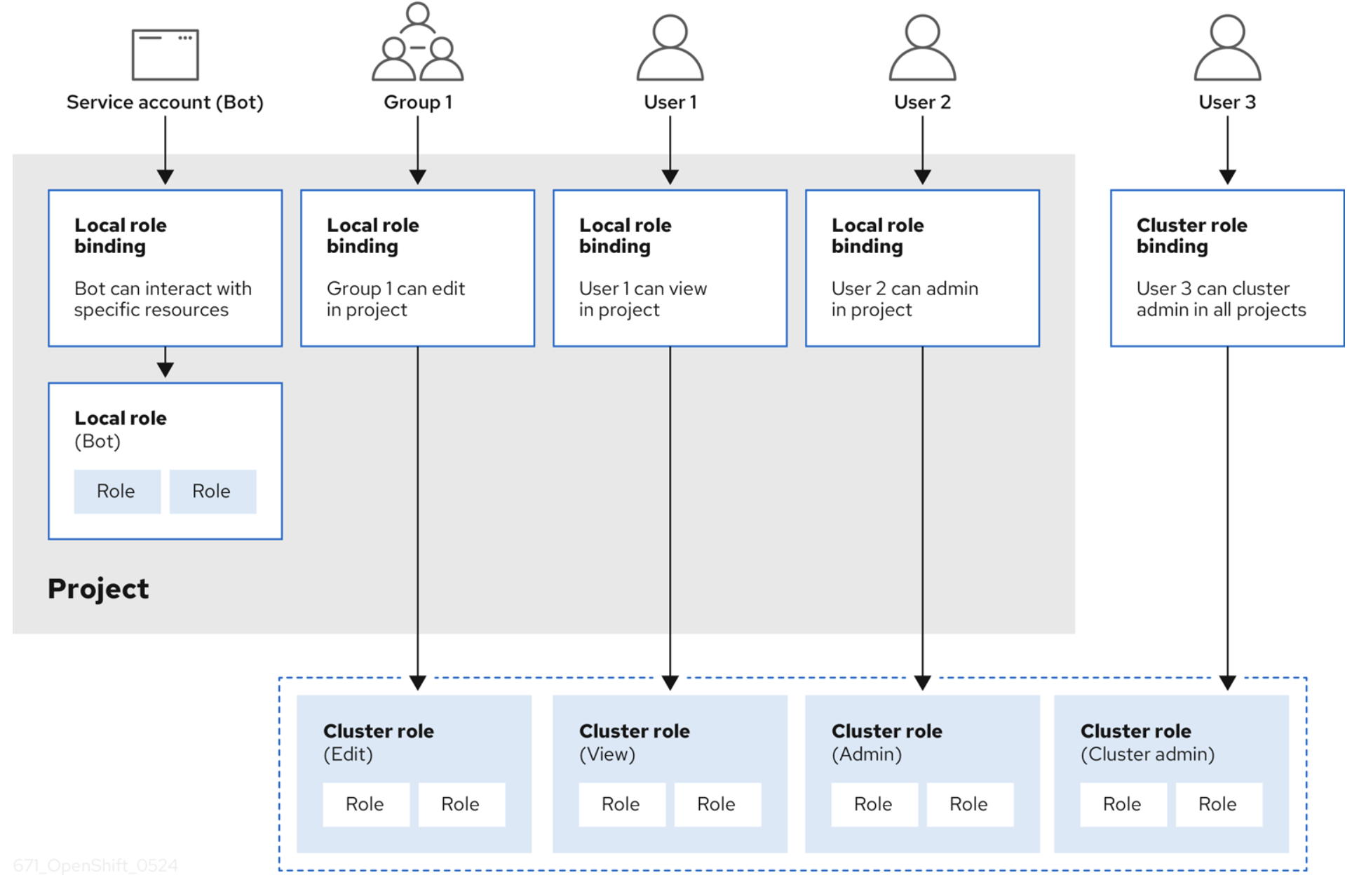
Autenticación y autorización de recursos que están dentro de la capa de OpenShift
Un recurso que está dentro de la capa de Kubernetes (generalmente un pod) puede requerir acceso para realizar una de las siguientes acciones:
- interactuar con la API de Kubernetes;
- interactuar con el host (capa de infraestructura) en el que se aloja el recurso;
- interactuar con recursos fuera del clúster (por ejemplo, uno de nube).
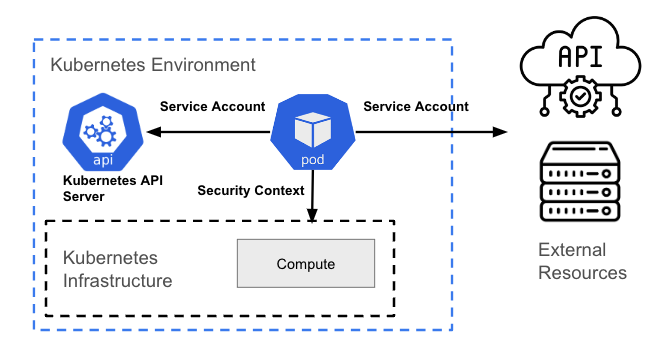
Interacción con la API de Kubernetes
Cualquier interacción con la API de Kubernetes requiere algún tipo de autenticación mediante OAuth 2.0. Un pod representa un usuario no humano, por lo que requiere una cuenta de servicio para interactuar con el servidor de la API.
De manera predeterminada, un pod se asocia con una cuenta de servicio, y se coloca una credencial (token) para esa cuenta en el sistema de archivos de cada contenedor en el pod en /var/run/secrets/kubernetes. io/serviceaccount/token. Hay un debate sobre si este modelo es útil o no, por lo que se puede configurar en OpenShift y aplicar mediante políticas con herramientas como ACS.
Interacción con la capa de infraestructura de host o Kubernetes
Este tipo de interacción no depende de las llamadas a la API de Kubernetes. De hecho, está relacionado con la gestión de permisos a nivel de proceso (permisos de Linux) del host fundamental.
La asignación de las acciones (permisos) que un pod puede realizar con la infraestructura y los recursos a los que puede acceder se lleva a cabo con las restricciones de contexto de seguridad (SCC). Una SCC es un recurso de OpenShift que restringe un pod a un grupo de recursos y es similar al de contexto de seguridad de Kubernetes.
Por ejemplo, un proceso puede tener o no permiso para crear un archivo en una ruta determinada, o puede tener solo permisos de lectura y no de escritura en un archivo que ya exista. El propósito principal de ambos es limitar el acceso de un pod al entorno del host. Puedes usar una SCC para controlar los permisos del pod, de manera similar a la forma en que se usa el RBAC para administrar los privilegios del usuario.
Interacción con recursos externos
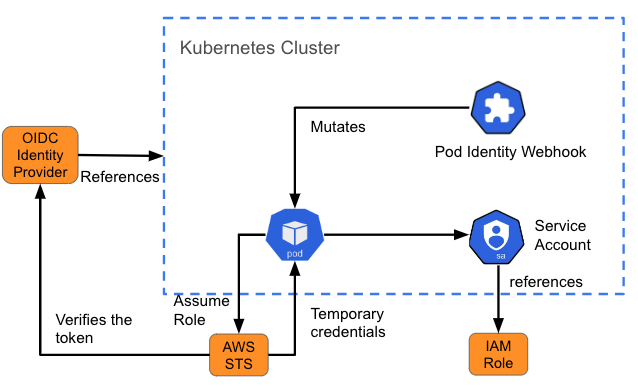
A veces, un pod necesita acceder a un recurso fuera del clúster. Por ejemplo, puede requerir acceso a un almacén de objetos (como un bucket de S3) para los datos o los archivos de registro. En estos casos, debes comprender de qué manera autentica a los usuarios el recurso y qué necesitas incorporar en el pod para que se comunique con él.
La gestión de identidades y accesos (IAM) para las funciones de las cuentas de servicio (IRSA) de Amazon es un ejemplo de un diseño de este tipo para proporcionar a los pods un conjunto de credenciales para acceder a los servicios en Amazon Web Services (AWS). Cuando se crea un pod, un webhook inserta variables (la ruta al token de la cuenta de servicio de Kubernetes y el ARN de la función que se adopta) en el pod que hace referencia a la cuenta de servicio. Esto también se denomina "mutación". Si la función que adopta IAM tiene los permisos de AWS requeridos, el pod puede ejecutar las operaciones del kit de desarrollo de software (SDK) de AWS usando credenciales de AWS Security Token Service (STS) temporales.
Autenticación y autorización para las aplicaciones en contenedores en OpenShift
La capa final son las aplicaciones en contenedores. Como ocurre en la capa anterior, cada contenedor puede intentar acceder a lo siguiente:
- la API de Kubernetes;
- otra API que ofrece otro contenedor dentro del clúster o un recurso fuera de él;
- una conexión que no es de API, como el contacto con un puerto específico para acceder a la base de datos.
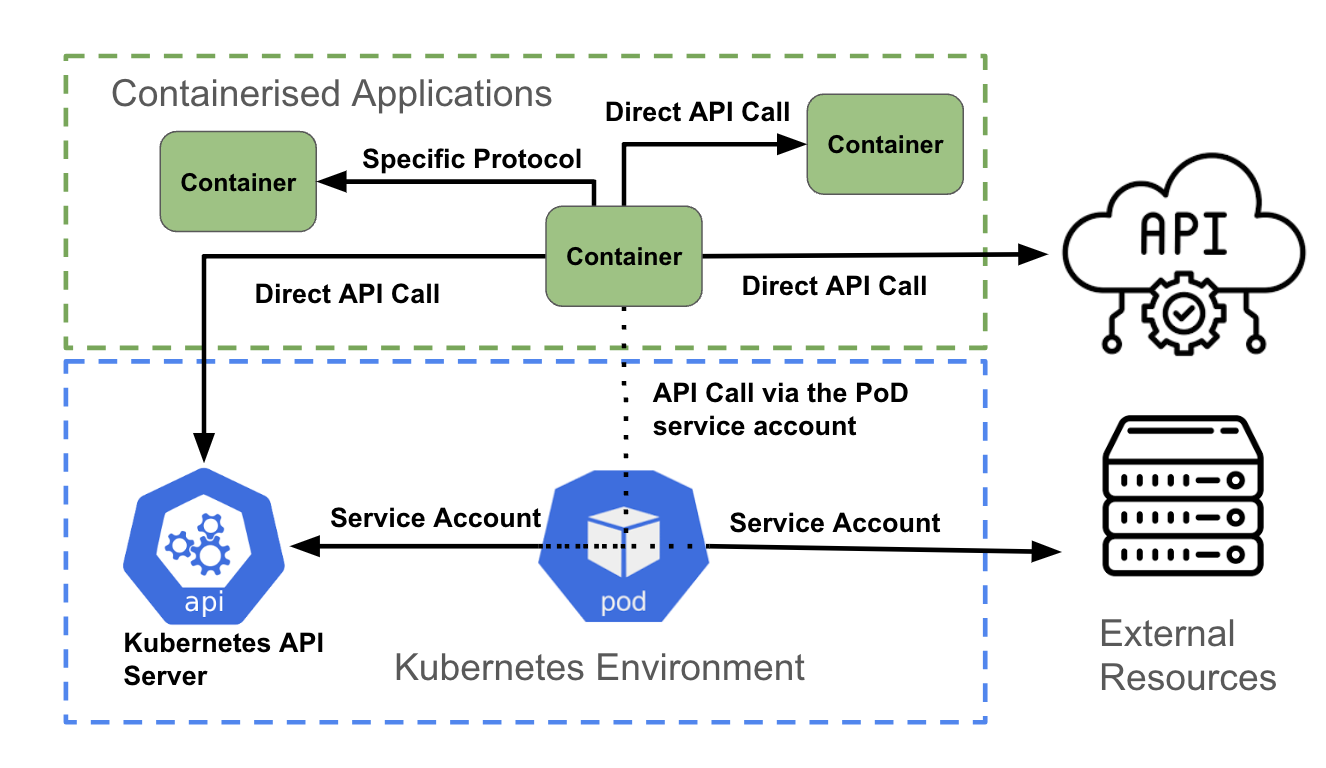
Como se ilustra en la figura anterior, un contenedor que accede a una API puede:
- acceder directamente a otra API con las credenciales de autenticación asociadas a la aplicación (por ejemplo, con los secretos de Kubernetes);
- acceder directamente a un extremo que no pertenece a la API, mediante los mecanismos de autenticación que admite el extremo;
- usar la cuenta de servicio del pod.
Llamada directa a la API
Un contenedor puede acceder a la API de Kubernetes obteniendo las variables de entorno KUBERNETES_SERVICE_HOST y KUBERNETES_SERVICE_PORT_HTTPS. Para el tráfico de la API que no es de Kubernetes, una aplicación puede usar una biblioteca de clientes (por ejemplo, una API de AWS) o una integración personalizada que creó el desarrollador.
Comunicación que no se basa en la API
Es posible que una aplicación deba conectarse a una base de datos para recuperar o enviar información. En tal caso, la autenticación suele gestionarse como parte del código dentro del contenedor y, por lo general, se puede actualizar en el tiempo de ejecución usando variables de entorno, secretos, ConfigMaps, etc.
Uso de la cuenta de servicio
La forma recomendada para autenticarse en el servidor de la API de Kubernetes es con una credencial de cuenta de servicio. La mayoría de los lenguajes de codificación tienen un conjunto de bibliotecas de clientes de Kubernetes compatibles. A partir de esas bibliotecas, las credenciales de la cuenta de servicio de un pod se usan para comunicarse con el servidor de la API. OpenShift monta automáticamente una cuenta de servicio dentro de cada pod, lo que permite acceder al token con alcance limitado.
Para las llamadas a la API que no son de Kubernetes, un contenedor también puede usar la cuenta de servicio del pod cuando se autentica en un servicio de API externo.
La autenticación y la autorización
Una computadora debe saber quién es el usuario y qué permisos tiene. Esas son las áreas de la autenticación y la autorización, y ahora comprendes de qué manera se gestionan dentro de Kubernetes y OpenShift.
Gracias a Shane Boulden y Derek Waters por su revisión exhaustiva y sus comentarios sobre este artículo.
Sobre el autor

Simon Delord is a Solution Architect at Red Hat. He works with enterprises on their container/Kubernetes practices and driving business value from open source technology. The majority of his time is spent on introducing OpenShift Container Platform (OCP) to teams and helping break down silos to create cultures of collaboration.Prior to Red Hat, Simon worked with many Telco carriers and vendors in Europe and APAC specializing in networking, data-centres and hybrid cloud architectures.Simon is also a regular speaker at public conferences and has co-authored multiple RFCs in the IETF and other standard bodies.
Navegar por canal

Automatización
Las últimas novedades en la automatización de la TI para los equipos, la tecnología y los entornos

Inteligencia artificial
Descubra las actualizaciones en las plataformas que permiten a los clientes ejecutar cargas de trabajo de inteligecia artificial en cualquier lugar

Nube híbrida abierta
Vea como construimos un futuro flexible con la nube híbrida

Seguridad
Vea las últimas novedades sobre cómo reducimos los riesgos en entornos y tecnologías

Edge computing
Conozca las actualizaciones en las plataformas que simplifican las operaciones en el edge

Infraestructura
Vea las últimas novedades sobre la plataforma Linux empresarial líder en el mundo

Aplicaciones
Conozca nuestras soluciones para abordar los desafíos más complejos de las aplicaciones
Virtualización
El futuro de la virtualización empresarial para tus cargas de trabajo locales o en la nube