The pace of generative AI (gen AI) innovation demands powerful, flexible and efficient solutions for deploying large language models (LLMs). Today, we're introducing Red Hat AI Inference Server. As a key component of the Red Hat AI platform, it is included in Red Hat OpenShift AI and Red Hat Enterprise Linux AI (RHEL AI). AI Inference Server is also available as a standalone product, designed to bring optimized LLM inference capabilities with true portability across your hybrid cloud environments.
Across any deployment environment, AI Inference Server provides users with a hardened, supported distribution of vLLM along with intelligent LLM compression tools and an optimized model repository on Hugging Face, all backed by Red Hat's enterprise support and third-party deployment flexibility pursuant to Red Hat’s third-party support policy.
Accelerating inference with a vLLM core & advanced parallelism
At the heart of AI Inference Server lies the vLLM serving engine. vLLM is renowned for its high-throughput and memory-efficient performance, achieved through innovative techniques like PagedAttention (optimizing GPU memory management, originating from research at University of California, Berkeley) and continuous batching, often achieving several times higher performance compared to traditional serving methods. The server, additionally, typically exposes an OpenAI-compatible API endpoint, simplifying integration.
To handle today's massive gen AI models across diverse hardware, vLLM provides robust inference optimizations:
- Tensor parallelism (TP): Splits individual model layers across multiple GPUs, typically within a node, reducing latency and increasing computational throughput for that layer.
- Pipeline parallelism (PP): Stages sequential groups of model layers across different GPUs or nodes. This is crucial for fitting models that are too large even for a single multi-GPU node.
- Expert parallelism (EP) for mixture of experts (MoE) models: vLLM includes specialized optimizations for efficiently handling MoE model architectures, managing their unique routing and computation needs.
- Data parallelism (DP): vLLM supports data parallel attention which routes individual requests to different vLLM engines. During MoE layers, the data parallel engines join together, sharding experts across all data parallel and tensor parallel workers. This is particularly important on models like DeepSeek V3 or Qwen3 with a small number of key-value attention (KV) heads, where tensor parallelism causes wasteful KV cache duplication. Data parallelism lets vLLM scale to a larger number of GPUs in this case.
- Quantization: LLM Compressor, a component of AI Inference Server, provides a unified library for creating compressed models with weight and activation quantization or weight-only quantization for faster inference with vLLM. vLLM has custom kernels, like Marlin and Machete, for optimized performance with quantization.
- Speculative decoding: Speculative decoding improves the inference latency by using a smaller, faster draft model to generate several future tokens, which are then validated or corrected by the main, larger model in fewer steps. This approach reduces overall decoding latency and increases throughput without sacrificing output quality.
It's important to note that these techniques can often be combined — for instance, using pipeline parallelism across nodes and tensor parallelism within each node — to effectively scale the largest models across complex hardware topologies.
Deployment portability via containerization
Delivered as a standard container image, AI Inference Server offers unparalleled deployment flexibility. This containerized format is key to its hybrid cloud portability, providing that the exact same inference environment runs consistently whether deployed via Red Hat OpenShift, Red Hat Enterprise Linux (RHEL), non-Red Hat Kubernetes platforms or other standard Linux systems. It provides a standardized, predictable foundation to serve LLMs anywhere your business requires, simplifying operations across diverse infrastructure.
Multi accelerator support
AI Inference Server is engineered with robust multi-accelerator support as a core design principle. This capability allows the platform to seamlessly leverage a diverse range of hardware accelerators, including NVIDIA, AMD GPUs and Google TPUs. By providing a unified inference serving layer that abstracts away the complexities of underlying hardware, AI Inference Server offers significant flexibility and optimization opportunities.
This multi-accelerator support enables users to:
- Optimize for performance and cost: Deploy inference workloads on the most suitable accelerator based on the specific model characteristics, latency requirements and cost considerations. Different accelerators excel in different areas, and the ability to choose the right hardware for the job leads to better performance and resource utilization.
- Future-proof deployments: As new and more efficient accelerator technologies become available, AI Inference Server's architecture allows for their integration without requiring significant changes to the serving infrastructure or application code. This provides long-term viability and adaptability.
- Scale inference capacity: Easily scale inference capacity by adding more accelerators of the same type or by incorporating different types of accelerators to handle diverse workload demands. This provides the agility needed to meet fluctuating user traffic and evolving AI model complexities.
- Accelerator choice: By supporting a variety of accelerator vendors with the same software interface, the platform reduces dependency on a single hardware provider, offering greater control over hardware procurement and cost management.
- Simplify infrastructure management: AI Inference Server provides a consistent management interface across different accelerator types, simplifying the operational overhead associated with deploying and monitoring inference services on heterogeneous hardware.
Model optimization powered by Neural Magic expertise within Red Hat
Deploying massive LLMs efficiently often requires optimization. AI Inference Server integrates powerful LLM compression capabilities, leveraging the pioneering model optimization expertise brought in by Neural Magic, now part of Red Hat. Using industry-leading quantization and sparsity techniques like SparseGPT, the integrated compressor drastically reduces model size and computational needs without significant accuracy loss. This allows for faster inference speeds and better resource utilization, leading to substantial reductions in memory footprint and enabling models to run effectively even on systems with constrained GPU memory.
Streamlined access with an optimized model repository
To simplify deployment further, AI Inference Server includes access to a curated repository of popular LLMs (such as Llama, Mistral and Granite families), conveniently hosted on the Red Hat AI page on Hugging Face.
These aren't just standard models — they have been optimized using the integrated compression techniques, specifically for high-performance execution on the vLLM engine. This means you get readily deployable, efficient models out-of-the-box, drastically reducing the time and effort needed to get your AI applications into production and delivering value faster.
Technical overview of Red Hat AI Inference Server

The vLLM architecture seeks to maximize throughput and minimize latency for LLM inference, particularly in systems handling high concurrency with varied request lengths. At the center of this design is the EngineCore, a dedicated inference engine that coordinates forward computations, manages KV cache and dynamically batches tokens coming from multiple simultaneous prompts.
The EngineCore not only reduces the overhead of managing long context windows but also intelligently preempts or interleaves short, latency-sensitive requests with longer running queries. This is achieved through a combination of queue-based scheduling and PagedAttention, a novel approach that virtualizes the key-value cache for each request. In effect, the EngineCore improves efficient GPU memory usage while reducing the idle time between computation steps.
To interface with user-facing services, the EngineCoreClient serves as an adapter that interacts with APIs (HTTP, gRPC, etc.) and relays requests to EngineCore. Multiple EngineCoreClients can communicate with one or more EngineCores, facilitating distributed or multinode deployments. By cleanly separating request handling from the low-level inference operations, vLLM allows for flexible infrastructure strategies, such as load balancing across multiple EngineCores or scaling the number of clients to match user demand.
This separation not only allows for flexible integration with various serving interfaces, it also enables distributed and scalable deployment. EngineCoreClients can run on separate processes, communicating with one or more EngineCores over the network to balance load and decrease CPU overheads.
Running Red Hat AI Inference Server
Running on RHEL
$ podman run --rm -it --device nvidia.com/gpu=all -p 8000:8000 \
--ipc=host \
--env "HUGGING_FACE_HUB_TOKEN=$HF_TOKEN" \
--env "HF_HUB_OFFLINE=0" -v ~/.cache/vllm:/home/vllm/.cache \
--name=vllm \
registry.redhat.io/rhaiis/vllm-cuda-rhel9 \
--tensor-parallel-size 8 \
--max-model-len 32768 \
--enforce-eager --model RedHatAI/Llama-4-Scout-17B-16E-Instruct-FP8-dynamicRunning on OpenShift
Sample OpenShift deployment spec for AI Inference Server:
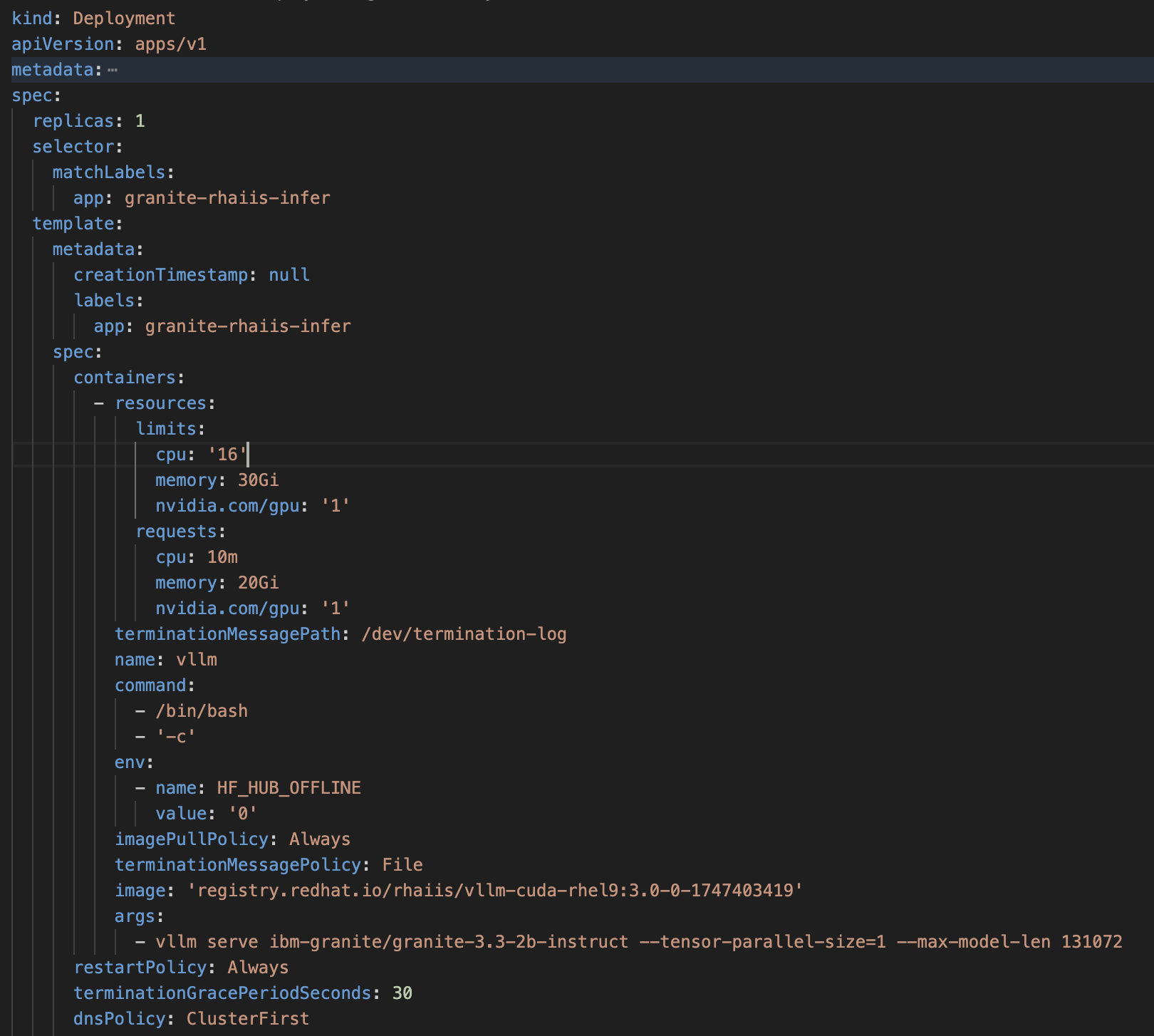
AI Inference Server container log:
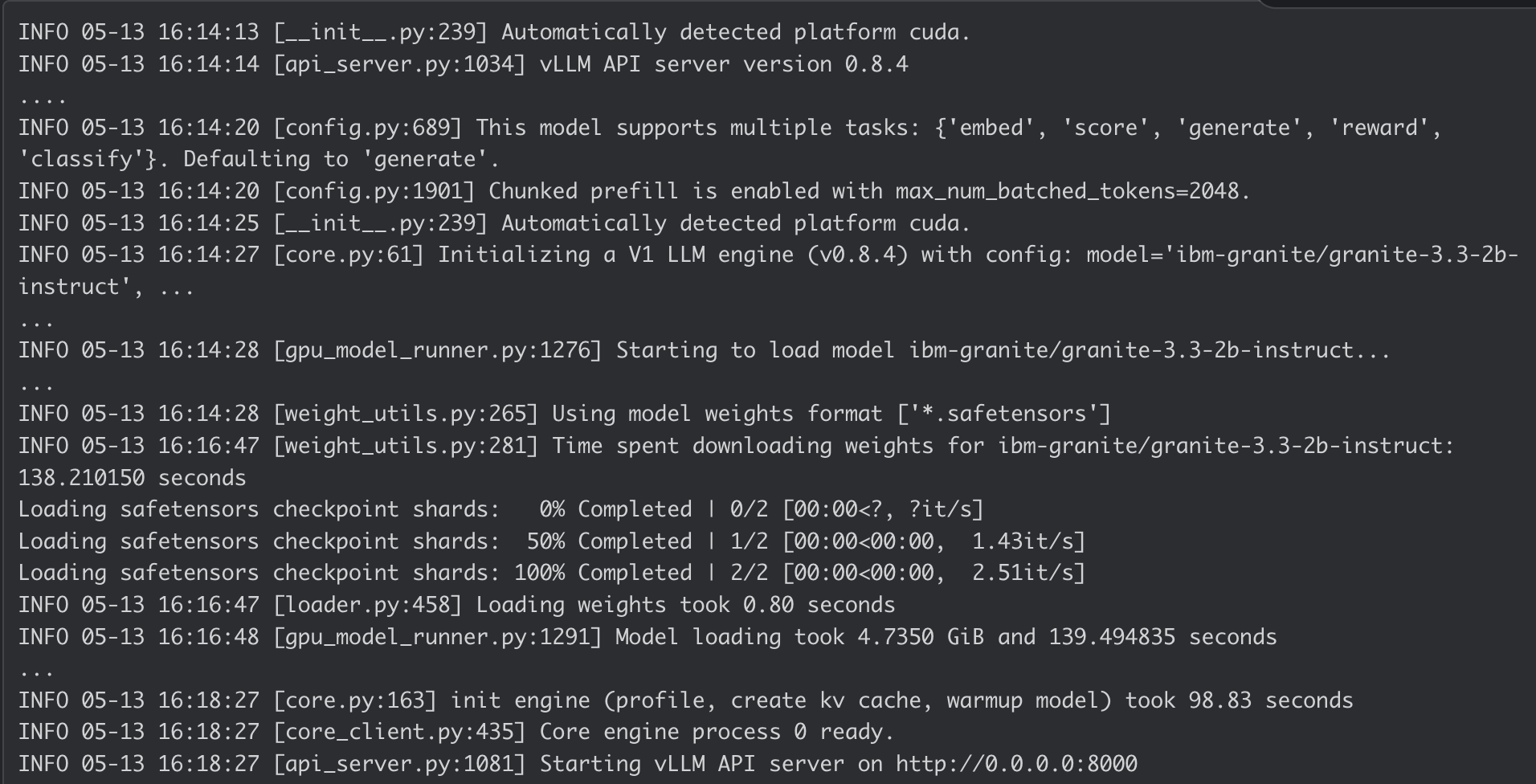
Conclusion
Red Hat AI Inference Server combines state-of-the-art performance with the deployment flexibility you need. Its containerized nature brings true hybrid cloud flexibility, allowing you to deploy cutting-edge AI inference consistently wherever your data and applications reside, delivering a powerful foundation for your enterprise AI workloads.
Explore the Red Hat AI Inference Server webpage and our guided demo for more information or check out our technical documentation for detailed configurations.
Product
Red Hat AI Inference Server
About the authors

Erwan Gallen is Senior Principal Product Manager, Generative AI, at Red Hat, where he follows Red Hat AI Inference Server product and manages hardware-accelerator enablement across OpenShift, RHEL AI, and OpenShift AI. His remit covers strategy, roadmap, and lifecycle management for GPUs, NPUs, and emerging silicon, ensuring customers can run state-of-the-art generative workloads seamlessly in hybrid clouds.
Before joining Red Hat, Erwan was CTO and Director of Engineering at a media firm, guiding distributed teams that built and operated 100 % open-source platforms serving more than 60 million monthly visitors. The experience sharpened his skills in hyperscale infrastructure, real-time content delivery, and data-driven decision-making.
Since moving to Red Hat he has launched foundational accelerator plugins, expanded the company’s AI partner ecosystem, and advised Fortune 500 global enterprises on production AI adoption. An active voice in the community, he speaks regularly at NVIDIA GTC, Red Hat Summit, OpenShift Commons, CERN, and the Open Infra Summit.

Carlos Condado is a Senior Product Marketing Manager for Red Hat AI. He helps organizations navigate the path from AI experimentation to enterprise-scale deployment by guiding the adoption of MLOps practices and integration of AI models into existing hybrid cloud infrastructures. As part of the Red Hat AI team, he works across engineering, product, and go-to-market functions to help shape strategy, messaging, and customer enablement around Red Hat’s open, flexible, and consistent AI portfolio.
With a diverse background spanning data analytics, integration, cybersecurity, and AI, Carlos brings a cross-functional perspective to emerging technologies. He is passionate about technological innovations and helping enterprises unlock the value of their data and gain a competitive advantage through scalable, production-ready AI solutions.

More like this
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds