Le rythme soutenu de l'innovation dans le domaine de l'IA générative exige des solutions puissantes, flexibles et efficaces pour le déploiement des grands modèles de langage (LLM). C'est pour relever ce défi que nous avons développé la solution Red Hat AI Inference Server. Elle est incluse dans la gamme Red Hat AI, avec les solutions Red Hat OpenShift AI et Red Hat Enterprise Linux AI (RHEL AI). Elle est également disponible sous forme de produit autonome, pour offrir les capacités optimisées d'inférence des LLM à tous les environnements de cloud hybride avec une véritable portabilité.
Dans tous les environnements de déploiement, la solution AI Inference Server permet une distribution facilitée et sécurisée du vLLM. Elle fournit aux utilisateurs des outils intelligents de compression des LLM, un référentiel de modèles optimisé sur Hugging Face, avec le soutien du service d'assistance aux entreprises de Red Hat et une prise en charge tierce pour un déploiement plus flexible, conformément à la politique d'assistance tierce de Red Hat.
Accélération des opérations d'inférence grâce à un noyau vLLM et au parallélisme avancé
La solution AI Inference Server repose sur un moteur vLLM. Le vLLM est réputé pour ses performances élevées en matière de débit et d'économie de mémoire, obtenues grâce à des techniques novatrices telles que PagedAttention (optimisation de la gestion de la mémoire des GPU développée par l'Université de Californie à Berkeley aux États-Unis) et le traitement par lots continu. Ces performances sont souvent plusieurs fois supérieures à celles obtenues avec les méthodes traditionnelles de distribution. En outre, le serveur expose généralement un point de terminaison d'API compatible avec OpenAI, ce qui simplifie l'intégration.
Pour gérer les énormes modèles actuels d'IA générative sur diverses plateformes matérielles, le vLLM offre de puissantes capacités d'inférence :
- Parallélisme des tenseurs : partitionnement des couches individuelles d'un modèle sur plusieurs GPU, généralement au sein d'un nœud afin de réduire la latence et d'augmenter le débit de calcul de cette couche.
- Parallélisme des pipelines : création de groupes séquentiels de couches de modèle sur différents GPU ou nœuds. Cette technique est cruciale pour l'ajustement des modèles qui sont trop volumineux même pour une configuration à plusieurs GPU sur un seul nœud.
- Parallélisme des experts pour les modèles MoE (Mixture of Experts) : fonctions d'optimisation spécialisées permettant de gérer efficacement les architectures de modèles MoE, en tenant compte de leurs besoins uniques en matière de routage et de calcul.
- Parallélisme des données : prise en charge du parallélisme des données qui permet d'acheminer les requêtes individuelles vers différents moteurs vLLM. Lors de la création des couches MoE, les moteurs de parallélisme des données se couplent pour fragmenter les experts entre tous les nœuds de parallélisme des données et des tenseurs. Cette technique est particulièrement utile pour les modèles tels que DeepSeek V3 ou Qwen3 qui hébergent un petit nombre de têtes d'attention clé-valeur, où le parallélisme des tenseurs entraîne une duplication inutile du cache clé-valeur. Dans ce cas, le parallélisme des données permet au vLLM de s'adapter à un plus grand nombre de GPU.
- Quantification : intégration de LLM Compressor, un composant de la solution AI Inference Server qui fournit une bibliothèque harmonisée pour créer des modèles compressés avec des méthodes de quantification des valeurs de poids et d'activation, ou de poids uniquement, pour accélérer les opérations d'inférence avec le vLLM. Le vLLM inclut des noyaux personnalisés (comme Marlin et Machete) pour optimiser les performances lors de la quantification.
- Décodage spéculatif : technique qui améliore la latence d'inférence grâce à l'utilisation d'un modèle type plus petit pour générer plusieurs jetons textuels pouvant ensuite être validés ou corrigés plus rapidement par le modèle principal, plus grand. Cette technique réduit la latence de décodage globale et augmente le débit sans sacrifier la qualité de la sortie.
Il est important de noter qu'il est souvent possible de combiner ces techniques (par exemple, en utilisant le parallélisme des pipelines sur les nœuds et le parallélisme des tenseurs au sein de chaque nœud), afin de mettre à l'échelle efficacement les modèles les plus volumineux sur des topologies matérielles complexes.
Portabilité du déploiement grâce à la conteneurisation
Distribuée sous forme d'image de conteneur standard, la solution AI Inference Server offre un niveau inégalé de flexibilité de déploiement. Ce format conteneurisé est essentiel à la portabilité dans le cloud hybride, à condition que le même environnement d'inférence s'exécute de manière cohérente sur Red Hat OpenShift, Red Hat Enterprise Linux (RHEL), des plateformes Kubernetes tierces ou d'autres systèmes Linux standards. Cette solution fournit une base standardisée et prévisible qui permet de déployer des LLM dans tous les environnements, avec à la clé une simplification des processus d'exploitation sur de nombreuses infrastructures.
Prise en charge de plusieurs accélérateurs
La solution AI Inference Server inclut une prise en charge fiable de plusieurs accélérateurs. Cette caractéristique permet à la plateforme d'exploiter facilement divers accélérateurs matériels, notamment les processeurs graphiques NVIDIA, AMD et les Google TPU. La couche unifiée de distribution des charges de travail d'inférence élimine la complexité du matériel sous-jacent, ce qui permet à la solution AI Inference Server d'offrir une grande flexibilité et de multiples possibilités d'optimisation.
La prise en charge de plusieurs accélérateurs apporte les avantages suivants aux utilisateurs :
- Optimisation des performances et des coûts : les charges de travail d'inférence peuvent être déployées sur l'accélérateur le plus adapté en fonction des caractéristiques du modèle, des exigences en matière de latence et des coûts. Chaque accélérateur excelle dans un domaine différent, et la possibilité de choisir le matériel adapté à la tâche permet d'améliorer les performances et l'utilisation des ressources.
- Pérennité des déploiements : l'architecture de la solution AI Inference Server permet d'intégrer les nouvelles technologies d'accélérateur pour profiter de leurs avantages sans modification importante de l'infrastructure de distribution ou du code de l'application. Cette caractéristique permet d'assurer la viabilité et l'adaptabilité de la solution à long terme.
- Mise à l'échelle de la capacité d'inférence : la capacité d'inférence peut être facilement mise à l'échelle en ajoutant d'autres accélérateurs du même type ou en intégrant différents types d'accélérateurs pour faire face à l'évolution des besoins des charges de travail. Cette agilité permet de s'adapter aux fluctuations du trafic utilisateur et à l'évolution des modèles d'IA.
- Choix des accélérateurs : la plateforme est compatible avec différents accélérateurs utilisant la même interface logicielle. Elle offre donc une plus grande indépendance vis-à-vis des fournisseurs de matériel et un meilleur contrôle sur l'approvisionnement et la gestion des coûts.
- Simplification de la gestion de l'infrastructure : la solution AI Inference Server fournit une interface de gestion compatible avec différents types d'accélérateurs, ce qui simplifie les processus d'exploitation associés au déploiement et à la surveillance des services d'inférence sur du matériel varié.
Optimisation des modèles basée sur Neural Magic
Pour déployer efficacement des LLM, il est souvent nécessaire d'effectuer des optimisations. La solution AI Inference Server inclut de puissantes capacités de compression des LLM grâce à l'intégration des fonctions novatrices d'optimisation des modèles de Neural Magic, récemment acquis par Red Hat. Les techniques avancées de quantification et de parcimonie (tel que SparseGPT) permettent au processeur intégré de réduire considérablement la taille du modèle et les besoins en matière de calcul sans perte majeure de précision. De cette manière, il est possible d'accélérer la vitesse d'inférence et d'améliorer l'utilisation des ressources, avec à la clé une réduction considérable de l'empreinte mémoire et une exécution efficace des modèles même sur les systèmes ayant une mémoire GPU limitée.
Optimisation du référentiel de modèles pour un accès rationalisé
Pour simplifier davantage le déploiement, la solution AI Inference Server inclut une sélection de LLM courants (tels que les familles Llama, Mistral et Granite) dans un référentiel facilement accessible depuis la page Red Hat AI sur Hugging Face.
Ces modèles sont loin d'être standards : ils ont été optimisés à l'aide de techniques intégrées de compression, conçues notamment pour permettre une exécution hautes performances sur le moteur vLLM. Les utilisateurs disposent ainsi de modèles efficaces et prêts à l'emploi, ce qui permet de réduire considérablement le temps et les efforts nécessaires à la mise en production des applications d'IA, ainsi que d'accélérer la création de valeur.
Présentation technique de Red Hat AI Inference Server

L'architecture du vLLM vise à optimiser le débit et à minimiser la latence pour l'inférence des LLM, en particulier dans les systèmes gérant une haute simultanéité avec différentes longueurs de requêtes. Cette architecture repose sur EngineCore, un moteur d'inférence dédié qui coordonne les calculs directs, gère le cache clé-valeur et regroupe de manière dynamique les jetons textuels issus de multiples instructions génératives simultanées.
En plus de réduire les frais liés à la gestion des longues fenêtres de contexte, EngineCore permet la préemption ou l'entrelacement des requêtes courtes et sensibles à la latence avec des requêtes plus longues. Son fonctionnement repose sur l'ordonnancement basé sur des files d'attente et la technique PagedAttention, une approche novatrice qui virtualise le cache clé-valeur de chaque requête. EngineCore améliore en fait l'utilisation de la mémoire du GPU tout en réduisant le temps d'inactivité entre les étapes de calcul.
Pour interagir avec les services utilisateur, une instance EngineCoreClient fait le lien entre les API (HTTP, gRPC, etc.) et les requêtes auprès d'EngineCore. Plusieurs instances EngineCoreClient peuvent communiquer avec un ou plusieurs moteurs EngineCore, ce qui facilite les déploiements distribués ou sur plusieurs nœuds. Grâce à la séparation nette entre la gestion des requêtes et les opérations d'inférence de bas niveau, le vLLM offre la possibilité d'adopter différentes stratégies d'infrastructure, comme l'équilibrage de charge entre plusieurs moteurs EngineCore ou la mise à l'échelle du nombre d'instances EngineCoreClient pour répondre à la demande des utilisateurs.
Cette séparation permet non seulement une intégration flexible à diverses interfaces de distribution, mais aussi un déploiement distribué et évolutif. Les instances EngineCoreClient peuvent s'exécuter sur des processus distincts, tout en communiquant avec un ou plusieurs moteurs EngineCore sur le réseau pour équilibrer la charge et réduire la surcharge du processeur.
Exécution de Red Hat AI Inference Server
Exécution sur RHEL
$ podman run --rm -it --device nvidia.com/gpu=all -p 8000:8000 \
--ipc=host \
--env "HUGGING_FACE_HUB_TOKEN=$HF_TOKEN" \
--env "HF_HUB_OFFLINE=0" -v ~/.cache/vllm:/home/vllm/.cache \
--name=vllm \
registry.access.redhat.com/rhaiis/rh-vllm-cuda \
vllm serve \
--tensor-parallel-size 8 \
--max-model-len 32768 \
--enforce-eager --model RedHatAI/Llama-4-Scout-17B-16E-Instruct-FP8-dynamicExécution sur OpenShift
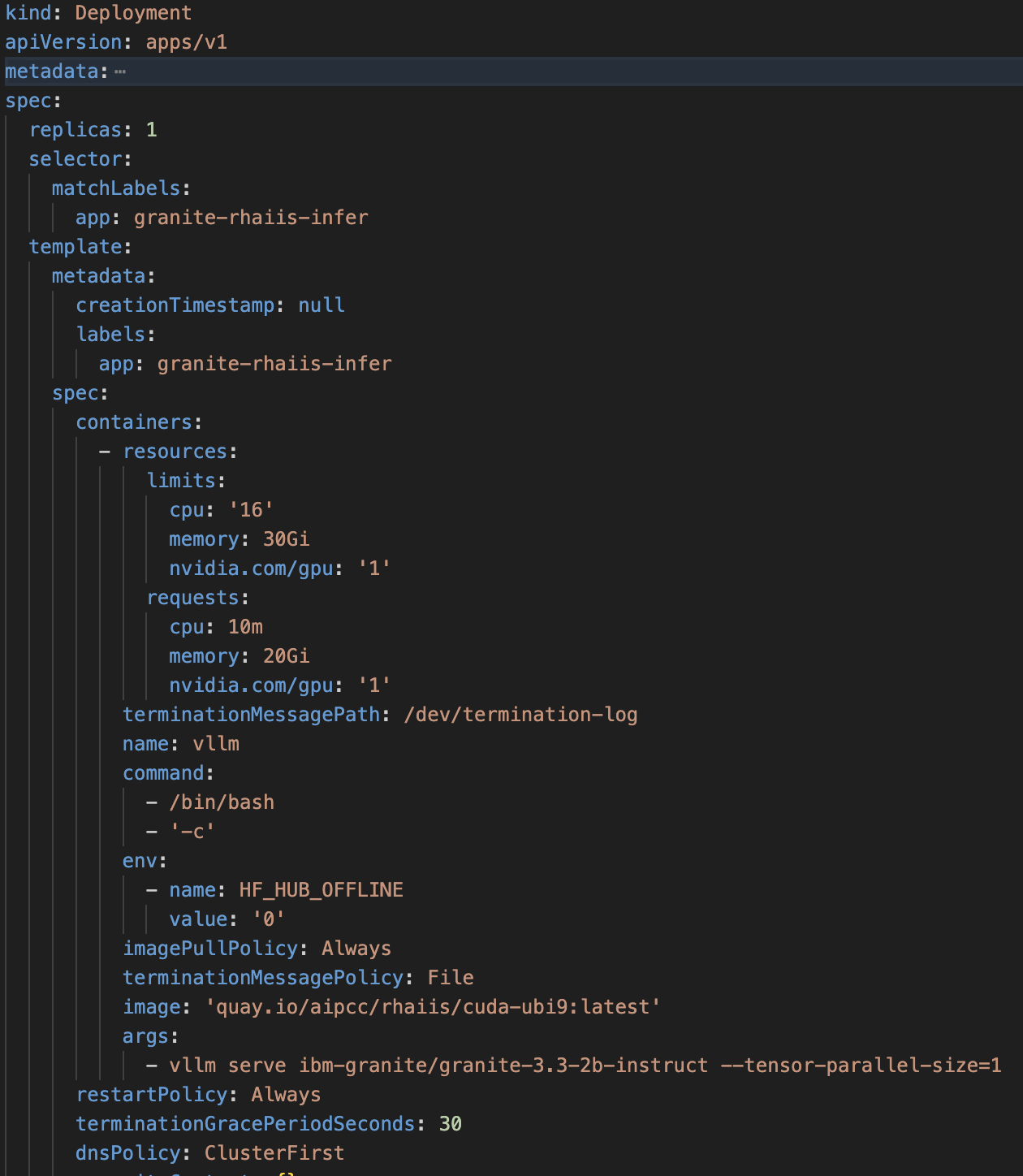
Exemple de spécification de déploiement OpenShift pour AI Inference Server :
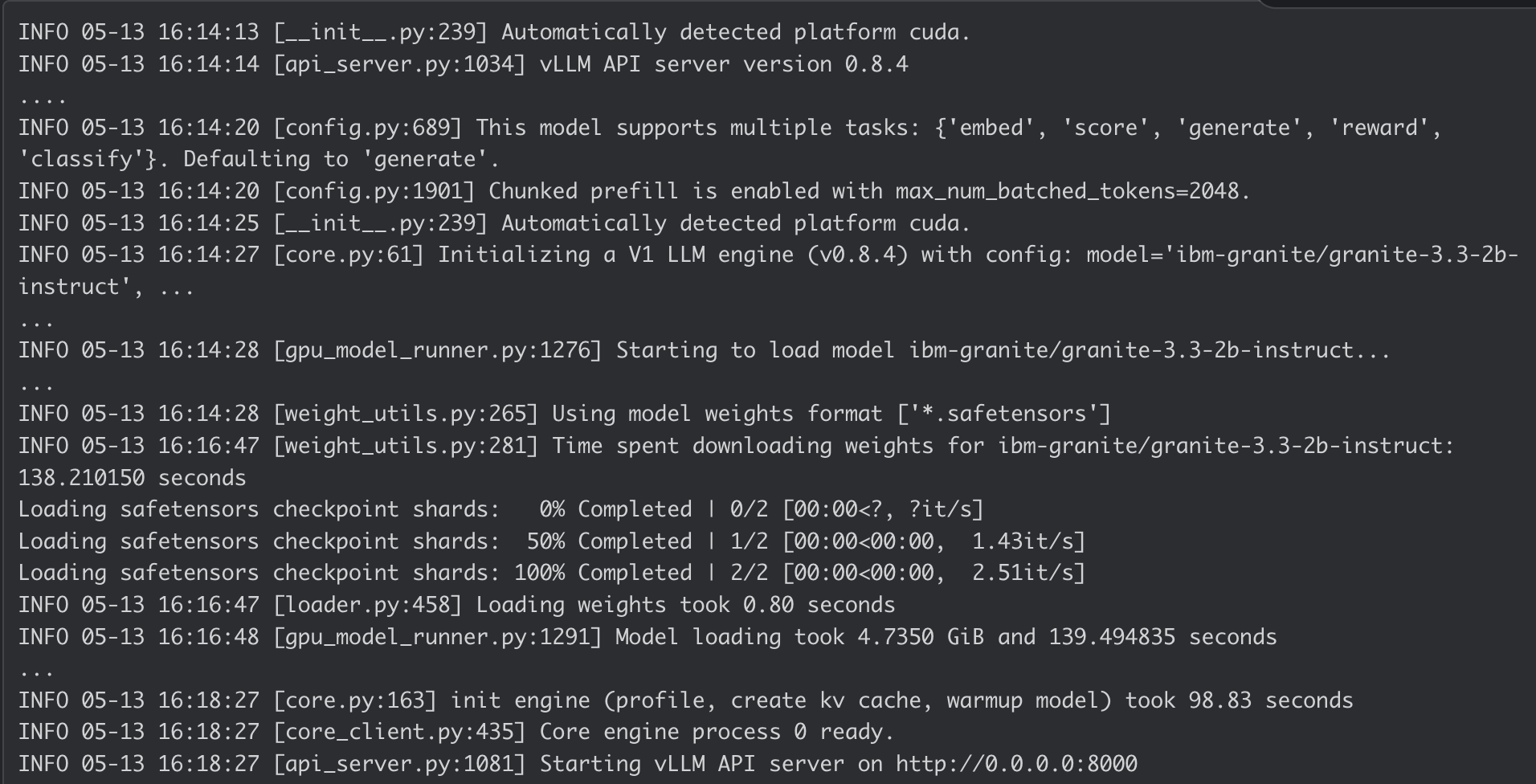
Journal du conteneur d'AI Inference Server :
Conclusion
La solution Red Hat AI Inference Server offre à la fois des performances de pointe et une flexibilité de déploiement indispensable. Parce qu'elle est conteneurisée, elle s'adapte parfaitement au cloud hybride. Elle permet d'exécuter des opérations d'inférence d'IA avancées de manière cohérente, où que se trouvent les données et les applications, offrant ainsi une base solide pour les charges de travail d'IA des entreprises.
Explorez la page web de Red Hat AI Inference Server et notre démonstration guidée pour plus d'informations, ou consultez la documentation technique pour obtenir des détails sur la configuration.
Product
Red Hat AI Inference Server
À propos des auteurs

Erwan Gallen is Senior Principal Product Manager, Generative AI, at Red Hat, where he follows Red Hat AI Inference Server product and manages hardware-accelerator enablement across OpenShift, RHEL AI, and OpenShift AI. His remit covers strategy, roadmap, and lifecycle management for GPUs, NPUs, and emerging silicon, ensuring customers can run state-of-the-art generative workloads seamlessly in hybrid clouds.
Before joining Red Hat, Erwan was CTO and Director of Engineering at a media firm, guiding distributed teams that built and operated 100 % open-source platforms serving more than 60 million monthly visitors. The experience sharpened his skills in hyperscale infrastructure, real-time content delivery, and data-driven decision-making.
Since moving to Red Hat he has launched foundational accelerator plugins, expanded the company’s AI partner ecosystem, and advised Fortune 500 global enterprises on production AI adoption. An active voice in the community, he speaks regularly at NVIDIA GTC, Red Hat Summit, OpenShift Commons, CERN, and the Open Infra Summit.

Carlos Condado is a Senior Product Marketing Manager for Red Hat AI. He helps organizations navigate the path from AI experimentation to enterprise-scale deployment by guiding the adoption of MLOps practices and integration of AI models into existing hybrid cloud infrastructures. As part of the Red Hat AI team, he works across engineering, product, and go-to-market functions to help shape strategy, messaging, and customer enablement around Red Hat’s open, flexible, and consistent AI portfolio.
With a diverse background spanning data analytics, integration, cybersecurity, and AI, Carlos brings a cross-functional perspective to emerging technologies. He is passionate about technological innovations and helping enterprises unlock the value of their data and gain a competitive advantage through scalable, production-ready AI solutions.

Contenu similaire
Parcourir par canal

Automatisation
Les dernières nouveautés en matière d'automatisation informatique pour les technologies, les équipes et les environnements

Intelligence artificielle
Actualité sur les plateformes qui permettent aux clients d'exécuter des charges de travail d'IA sur tout type d'environnement

Cloud hybride ouvert
Découvrez comment créer un avenir flexible grâce au cloud hybride

Sécurité
Les dernières actualités sur la façon dont nous réduisons les risques dans tous les environnements et technologies

Edge computing
Actualité sur les plateformes qui simplifient les opérations en périphérie

Infrastructure
Les dernières nouveautés sur la plateforme Linux d'entreprise leader au monde

Applications
À l’intérieur de nos solutions aux défis d’application les plus difficiles
Virtualisation
L'avenir de la virtualisation d'entreprise pour vos charges de travail sur site ou sur le cloud