Per tenere il passo con le continue innovazioni nell'IA generativa (IA gen) ci vogliono soluzioni potenti, flessibili ed efficienti per il deployment di modelli linguistici di grandi dimensioni (LLM). Ed è per questo che oggi presentiamo Red Hat AI Inference Server. Componente chiave della piattaforma Red Hat AI, è incluso all'interno di Red Hat OpenShift AI e Red Hat Enterprise Linux AI (RHEL AI). Ma AI Inference Server è disponibile anche come prodotto standalone, progettato per offrire funzionalità di inferenza LLM ottimizzate con una vera portabilità negli ambienti cloud ibridi.
In qualsiasi ambiente di deployment, AI Inference Server offre agli utenti una distribuzione consolidata e supportata di vLLM, strumenti di compressione per LLM intelligenti e un repository di modelli ottimizzato su Hugging Face, il tutto con supporto enterprise fornito da Red Hat e flessibilità nel deployment grazie alla policy sul supporto di terze parti di Red Hat.
Inferenza più rapida grazie a core vLLM e parallelismo avanzato
Alla base di AI Inference Server c'è un vLLM, un motore ottimizzato per il model serving, noto per le sue prestazioni ad alto rendimento ed efficienti in termini di memoria, ottenute grazie a tecniche innovative come PagedAttention (che prevede l'ottimizzazione della gestione della memoria della GPU, frutto di una ricerca presso l'Università della California a Berkeley) e il batching continuo, per performance di gran lunga superiori rispetto a quelle ottenute utilizzando i metodi tradizionali. Il server, inoltre, in genere presenta un endpoint API compatibile con OpenAI, per semplificarne l'integrazione.
vLLM ottimizza l'inferenza in modo affidabile per gestire i modelli di IA di ultima generazione su diversi tipi di hardware:
- Parallelismo tensoriale (Tensor Parallelism, TP): suddivide i singoli livelli del modello su più GPU, in genere all'interno di un nodo, riducendo la latenza e aumentando il throughput di elaborazione per quel livello.
- Parallelismo delle pipeline (Pipeline Parallelism, PP): organizza i gruppi sequenziali dei livelli del modello su diverse GPU o nodi. È un passaggio fondamentale per adattare modelli troppo grandi anche per un singolo nodo con più GPU.
- Parallelismo degli esperti (Expert Parallelism, EP) per i modelli Mixture of Expert (MoE): vLLM consente di ottimizzare dettagliatamente le risorse e gestire in modo efficiente le architetture dei modelli MoE, organizzando le specifiche esigenze di elaborazione e routing.
- Parallelismo dei dati (Data Parallelism, DP): vLLM supporta questo tipo di parallelismo per instradare le singole richieste a diversi motori vLLM che si uniscono nei livelli MoE, distribuendo gli esperti ai nodi di lavoro DP e TP. Questo è un aspetto particolarmente importante per modelli come DeepSeek V3 o Qwen3 con poche coppie chiave-valore (key-value, KV), in cui il TP causa una dispendiosa duplicazione della cache KV. In questo caso, il parallelismo dei dati consente di distribuire vLLM a un numero maggiore di GPU.
- Quantizzazione: il compressore LLM, un componente di AI Inference Server, fornisce una libreria unificata per la creazione di modelli compressi con quantizzazione del peso e dell'attivazione o quantizzazione del solo peso per un'inferenza più rapida con vLLM. vLLM dispone inoltre di kernel personalizzati, come Marlin e Machete, per sfruttare la quantizzazione per ottimizzare le prestazioni.
- Decodifica speculativa: migliora la latenza dell'inferenza utilizzando un modello di prova più piccolo e più veloce per generare diversi token futuri, che vengono poi convalidati o corretti dal modello principale più grande in meno passaggi. Questo approccio riduce la latenza di decodifica complessiva e aumenta il throughput senza sacrificare la qualità dell'output.
È importante tenere presente che queste tecniche spesso possono essere utilizzate in combinazione, ad esempio il parallelismo della pipeline sui nodi e il parallelismo tensoriale all'interno di ciascun nodo, per distribuire in modo efficace i modelli più grandi su topologie hardware complesse.
Containerizzazione per garantire la portabilità del deployment
Fornito come immagine dei container standard, AI Inference Server offre una flessibilità senza precedenti per i deployment. Questo formato containerizzato è fondamentale per la portabilità del cloud ibrido, perché lo stesso ambiente di inferenza viene eseguito in modo coerente indipendentemente dal fatto che venga distribuito tramite Red Hat OpenShift, Red Hat Enterprise Linux (RHEL), piattaforme Kubernetes non Red Hat o altri sistemi Linux standard. Fornisce una base standardizzata e prevedibile per distribuire gli LLM ovunque la tua azienda lo richieda, semplificando le operazioni su infrastrutture diverse.
Supporto per più acceleratori
Il principio alla base di AI Inference Server è poter supportare più acceleratori e sfruttare in modo lineare una vasta gamma di acceleratori hardware, tra cui NVIDIA, GPU AMD e TPU di Google. Fornendo un livello di inferenza unificato che elimina le complessità dell'hardware sottostante, AI Inference Server offre notevoli opportunità di flessibilità e ottimizzazione.
Grazie al supporto di più acceleratori puoi:
- Ottimizzare prestazioni e costi: esegui il deployment dei carichi di lavoro di inferenza sull'acceleratore più adatto in base alle caratteristiche specifiche del modello, ai requisiti di latenza e ai costi. Accelerati diversi funzionano meglio in aree diverse e potendo scegliere l'hardware giusto per ciascuna attività puoi migliorare prestazioni e utilizzo delle risorse.
- Eseguire deployment a prova di futuro: man mano che diventano disponibili nuove e più efficienti tecnologie di accelerazione, l'architettura di AI Inference Server ne consente l'integrazione senza richiedere modifiche significative all'infrastruttura o al codice dell'applicazione. Il risultato? Compatibilità e adattabilità a lungo termine.
- Ottenere scalabilità per la capacità di inferenza: aggiungendo più acceleratori dello stesso tipo o incorporando diversi tipi di acceleratori per gestire le diverse esigenze dei carichi di lavoro. Avrai l'agilità necessaria per far fronte alle fluttuazioni nel traffico degli utenti e alle complessità dei modelli di IA in continua evoluzione.
- Scegliere l'acceleratore: la stessa interfaccia software supporta diversi acceleratori, anche di fornitori diversi, quindi non sei più dipendente da un singolo provider hardware, ma puoi scegliere quello che vuoi e gestire al meglio i costi.
- Semplificare la gestione dell'infrastruttura: AI Inference Server fornisce un'interfaccia di gestione coerente per i diversi tipi di acceleratore, semplificando il sovraccarico operativo associato al deployment e al monitoraggio dei servizi di inferenza su un hardware eterogeneo.
Ottimizzazione dei modelli basata sull'esperienza di Neural Magic con Red Hat
Per distribuire in modo efficiente gli LLM spesso è necessario ottimizzare le operazioni. AI Inference Server integra potenti funzionalità di compressione LLM, sfruttando la pionieristica esperienza nell'ottimizzazione dei modelli di Neural Magic, ora parte di Red Hat. Utilizzando tecniche di quantizzazione e sparsità leader del settore, come SparseGPT, il compressore integrato riduce drasticamente le dimensioni del modello e le esigenze di elaborazione, senza perdite significative in termini di accuratezza. La velocità di inferenza risulta così maggiore e le risorse meglio utilizzate, riducendo notevolmente l'ingombro e consentendo l'esecuzione efficace dei modelli anche su sistemi con memoria GPU limitata.
Accesso semplificato con un repository di modelli ottimizzato
Per semplificare ulteriormente il deployment, AI Inference Server include un repository curato dei più diffusi LLM (come Llama, Mistral e Granite), comodamente ospitato sulla pagina Red Hat AI su Hugging Face.
Non sono solo modelli standard, ma anche ottimizzati utilizzando le tecniche di compressione integrate, in particolare per l'esecuzione ad alte prestazioni sul motore vLLM. In questo modo hai immediatamente a disposizione modelli efficienti e pronti all'uso, riducendo drasticamente i tempi e l'impegno necessari per avviare la produzione delle applicazioni di IA e ottenere più rapidamente i risultati previsti.
Panoramica tecnica di Red Hat AI Inference Server

L'architettura vLLM mira a massimizzare il throughput e ridurre al minimo la latenza dell'inferenza LLM, in particolare nei sistemi che gestiscono un'elevata simultaneità con richieste con lunghezze diverse. Al centro di tutto c'è EngineCore, un motore di inferenza dedicato che coordina i calcoli in avanti, gestisce la cache KV e invia dinamicamente in batch i token provenienti da più prompt simultanei.
EngineCore non riduce solo il carico di lavoro dovuto alla gestione di finestre di contesto lunghe, ma previene o alterna in modo intelligente le richieste brevi e sensibili alla latenza con query più lunghe. Questo risultato si ottiene combinando la pianificazione basata sulle code e PagedAttention, un nuovo approccio che virtualizza la cache chiave-valore per ogni richiesta. EngineCore utilizza quindi la memoria della GPU in modo efficiente e riduce i tempi di inattività tra le fasi di elaborazione.
Per interfacciarsi con i servizi rivolti agli utenti, un EngineCoreClient funge da adattatore che interagisce con le API (HTTP, gRPC e così via) e inoltra le richieste a EngineCore. Più EngineCoreClient possono comunicare con uno o più EngineCore, semplificando i processi di deployment distribuiti o multinodo. Separando nettamente la gestione delle richieste dalle operazioni di inferenza di routine, vLLM consente di adottare strategie di infrastruttura flessibili, come il bilanciamento del carico su più EngineCore o la scalabilità del numero di client per soddisfare le esigenze degli utenti.
Questa separazione non consente solo un'integrazione flessibile con varie interfacce di servizio, ma consente anche un deployment distribuito e scalabile. Gli EngineCoreClient possono essere eseguiti su processi separati, comunicando con uno o più EngineCore sulla rete per bilanciare il carico e ridurre i costi della CPU.
Come eseguire Red Hat AI Inference Server
Su RHEL
$ podman run --rm -it --device nvidia.com/gpu=all -p 8000:8000 \
--ipc=host \
--env "HUGGING_FACE_HUB_TOKEN=$HF_TOKEN" \
--env "HF_HUB_OFFLINE=0" -v ~/.cache/vllm:/home/vllm/.cache \
--name=vllm \
registry.access.redhat.com/rhaiis/rh-vllm-cuda \
vllm serve \
--tensor-parallel-size 8 \
--max-model-len 32768 \
--enforce-eager --model RedHatAI/Llama-4-Scout-17B-16E-Instruct-FP8-dynamicSu OpenShift
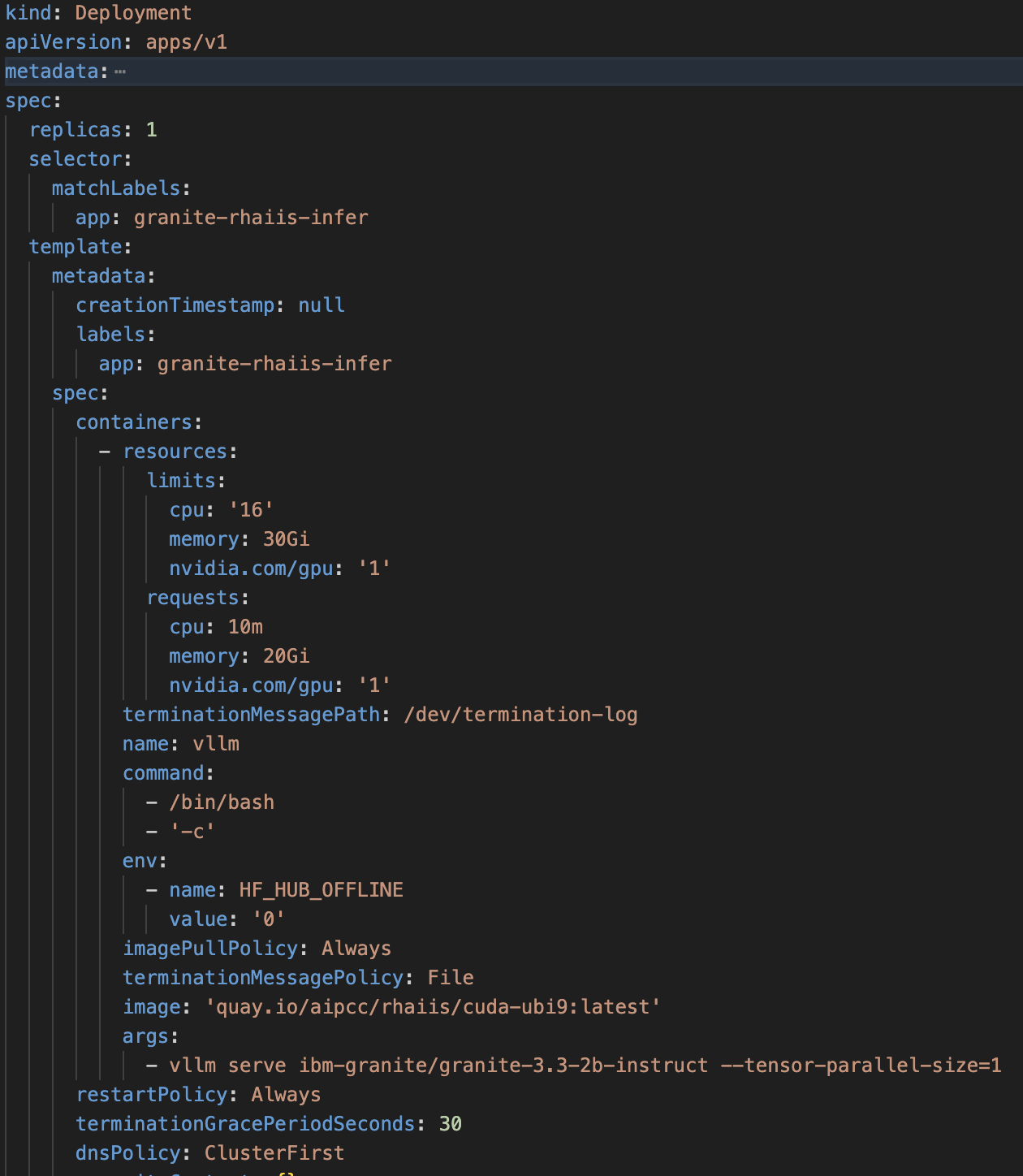
Esempio di specifiche per il deployment di OpenShift per AI Inference Server:
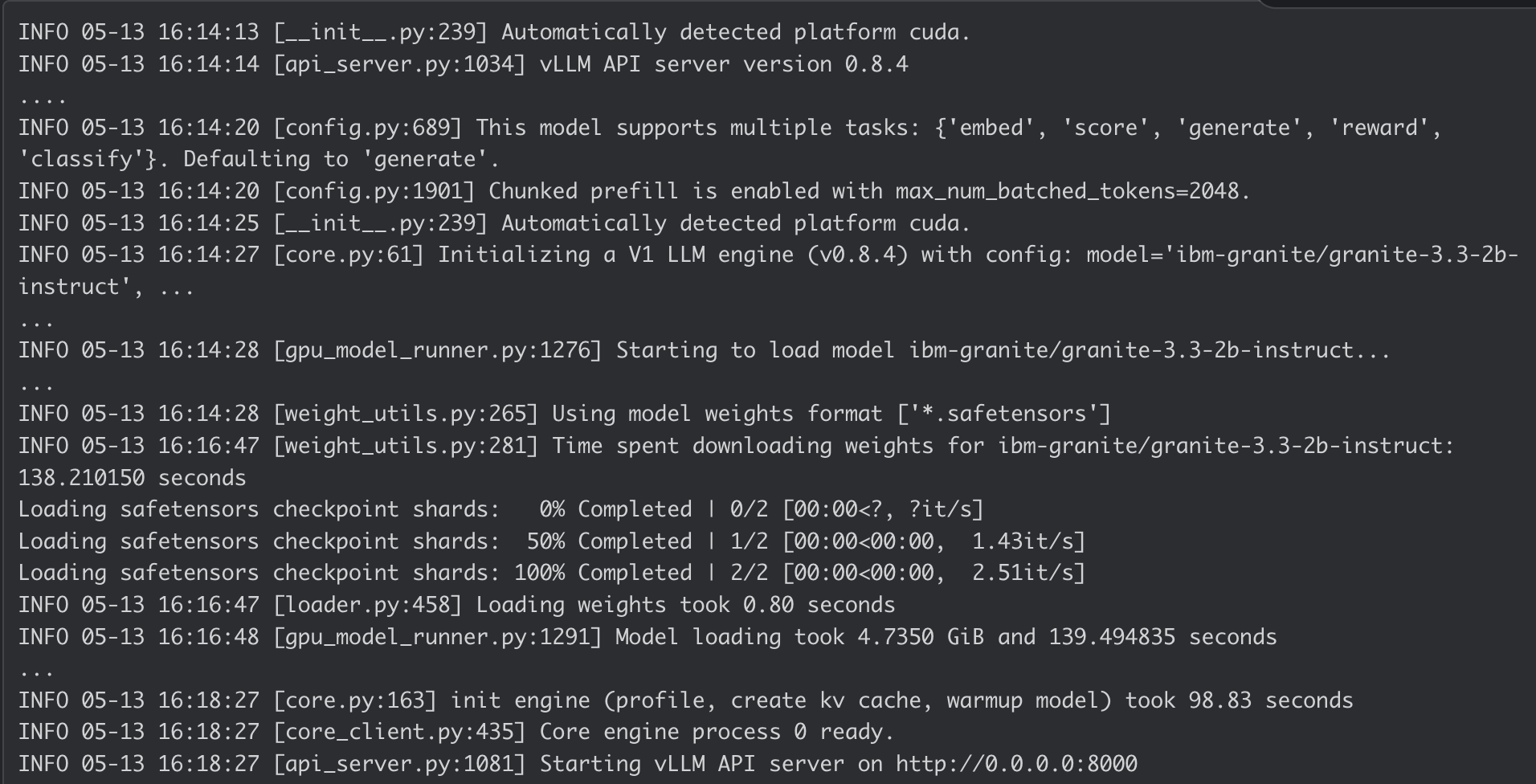
Log dei container di AI Inference Server:
Conclusioni
Red Hat AI Inference Server unisce prestazioni all'avanguardia alla flessibilità di deployment che cerchi. La sua natura containerizzata consente di ottenere un ambiente di cloud ibrido realmente flessibile, per distribuire l'inferenza dell'IA in modo coerente ovunque risiedano dati e applicazioni e disporre di una base solida per i carichi di lavoro IA aziendali.
Visita lapagina web di Red Hat AI Inference Server e guarda la demo guidata per saperne di più, oppure consulta la documentazione tecnica per avere informazioni dettagliate sulle configurazioni.
Product
Red Hat AI Inference Server
Sugli autori

Erwan Gallen is Senior Principal Product Manager, Generative AI, at Red Hat, where he follows Red Hat AI Inference Server product and manages hardware-accelerator enablement across OpenShift, RHEL AI, and OpenShift AI. His remit covers strategy, roadmap, and lifecycle management for GPUs, NPUs, and emerging silicon, ensuring customers can run state-of-the-art generative workloads seamlessly in hybrid clouds.
Before joining Red Hat, Erwan was CTO and Director of Engineering at a media firm, guiding distributed teams that built and operated 100 % open-source platforms serving more than 60 million monthly visitors. The experience sharpened his skills in hyperscale infrastructure, real-time content delivery, and data-driven decision-making.
Since moving to Red Hat he has launched foundational accelerator plugins, expanded the company’s AI partner ecosystem, and advised Fortune 500 global enterprises on production AI adoption. An active voice in the community, he speaks regularly at NVIDIA GTC, Red Hat Summit, OpenShift Commons, CERN, and the Open Infra Summit.

Carlos Condado is a Senior Product Marketing Manager for Red Hat AI. He helps organizations navigate the path from AI experimentation to enterprise-scale deployment by guiding the adoption of MLOps practices and integration of AI models into existing hybrid cloud infrastructures. As part of the Red Hat AI team, he works across engineering, product, and go-to-market functions to help shape strategy, messaging, and customer enablement around Red Hat’s open, flexible, and consistent AI portfolio.
With a diverse background spanning data analytics, integration, cybersecurity, and AI, Carlos brings a cross-functional perspective to emerging technologies. He is passionate about technological innovations and helping enterprises unlock the value of their data and gain a competitive advantage through scalable, production-ready AI solutions.

Altri risultati simili a questo
Ricerca per canale

Automazione
Novità sull'automazione IT di tecnologie, team e ambienti

Intelligenza artificiale
Aggiornamenti sulle piattaforme che consentono alle aziende di eseguire carichi di lavoro IA ovunque

Hybrid cloud open source
Scopri come affrontare il futuro in modo più agile grazie al cloud ibrido

Sicurezza
Le ultime novità sulle nostre soluzioni per ridurre i rischi nelle tecnologie e negli ambienti

Edge computing
Aggiornamenti sulle piattaforme che semplificano l'operatività edge

Infrastruttura
Le ultime novità sulla piattaforma Linux aziendale leader a livello mondiale

Applicazioni
Approfondimenti sulle nostre soluzioni alle sfide applicative più difficili
Virtualizzazione
Il futuro della virtualizzazione negli ambienti aziendali per i carichi di lavoro on premise o nel cloud