生成 AI のイノベーションのペースに対応するには、大規模言語モデル (LLM) をデプロイするための強力で柔軟かつ効率的なソリューションが必要です。本日は、Red Hat AI Inference Server を紹介します。これは Red Hat AI プラットフォームの主要コンポーネントであり、Red Hat OpenShift AI および Red Hat Enterprise Linux AI (RHEL AI) に含まれています。AI Inference Server はスタンドアローン製品としても利用でき、ハイブリッドクラウド環境内のどこででも実行できる真の可搬性を備えた最適化された LLM 推論機能を提供します。
あらゆるデプロイ環境において、AI Inference Server はサポート付きの強化された vLLM ディストリビューション、インテリジェントな LLM 圧縮ツール、Hugging Face 上の最適化されたモデルリポジトリを提供します。これらはすべて Red Hat のエンタープライズサポートと、Red Hat のサードパーティ・サポート・ポリシーに準拠するサードパーティのデプロイメントの柔軟性によって支えられています。
vLLM コアと高度な並列処理で推論を高速化
AI Inference Server の中心には、vLLM 提供エンジンがあります。vLLM は、その高スループットとメモリー効率の高いパフォーマンスで知られています。これは、PagedAttention (カリフォルニア大学バークレー校の研究に由来する GPU メモリー管理の最適化技術) や継続的バッチ処理などの革新的な技術によって達成されており、多くの場合、従来の提供方法と比較して数倍のパフォーマンスを実現します。また、このサーバーは通常、OpenAI 互換の API エンドポイントを公開しており、これによって統合が単純化されます。
さまざまなハードウェアで今日の大量の AI モデルを処理するために、vLLM は推論の堅牢な最適化を提供します。それらの処理には次のような方法があります。
- テンソル並列処理 (TP): 個々のモデルレイヤーを複数の GPU (通常はノード内にあるもの) に分割して、レイテンシーを短縮し、そのレイヤーの計算スループットを向上させます。
- パイプライン並列処理 (PP):さまざまな GPU またはノードにまたがってモデルレイヤーのシーケンシャルグループをステージングします。これは、単一のマルチ GPU ノードにすら大きすぎるモデルを適合させるのに不可欠です。
- エキスパート混合 (MoE) モデルのエキスパート並列処理 (EP):vLLM には、MoE モデルアーキテクチャを効率的に処理し、ルーティングと計算に関する固有のニーズを管理するための特殊な最適化処理が含まれています。
- データ並列処理 (DP):vLLM は、各リクエストを異なる vLLM エンジンにルーティングするデータ並列アテンションをサポートします。MoE レイヤーでは、データ並列エンジンが相互に結合し、すべてのデータ並列ワーカーとテンソル並列ワーカーの間でエキスパートをシャーディングします。これは、DeepSeek V3 や Qwen3 など、キーバリューアテンション (KV) ヘッドの数が少ないモデルで特に重要です。そのようなモデルでは、テンソル並列処理により KV キャッシュの無駄な重複が発生するためです。この場合、データ並列処理により、vLLM を多数の GPU に拡張できます。
- 量子化:AI Inference Server のコンポーネントである LLM Compressor が、vLLM による推論を高速化するために、重みとアクティベーション量子化または重みのみの量子化を使用して圧縮モデルを作成するための統合ライブラリを提供します。vLLM には Marlin や Machete などのカスタムカーネルがあり、量子化によってパフォーマンスを最適化します。
- 投機的デコーディング:投機的デコーディングは、より小規模で高速なドラフトモデルを使用して複数の未来のトークンを生成することで、推論のレイテンシーを改善します。これらのトークンは、より少ないステップで、より大規模なメインモデルによって検証または修正されます。このアプローチにより、全体的なデコードのレイテンシーが短縮され、出力品質を損なうことなくスループットが向上します。
重要なのは、これらの手法は組み合わせて使用できることが多いということです。たとえば、ノード間でパイプライン並列処理を行い、各ノード内でテンソル並列処理を使用することで、最大規模のモデルを複雑なハードウェアトポロジーにわたって効果的に拡張することが可能になります。
コンテナ化によるデプロイメントの可搬性
標準のコンテナイメージとして提供される AI Inference Server は、他にはないデプロイメントの柔軟性を提供します。このコンテナ化されたフォーマットは、ハイブリッドクラウドの可搬性の鍵であり、Red Hat OpenShift、Red Hat Enterprise Linux (RHEL)、Red Hat 以外の Kubernetes プラットフォーム、またはその他の標準的な Linux システムのいずれを介してデプロイしても、まったく同じ推論環境を一貫して実行できます。ビジネスが必要とする任意の場所で LLM を提供するための標準化された予測可能な基盤となり、多様なインフラストラクチャでの運用を単純化します。
マルチアクセラレーターのサポート
AI Inference Server は、堅牢なマルチアクセラレーターのサポートをコア原則として設計されています。この機能により、プラットフォームは NVIDIA GPU、AMD GPU、Google TPU などのさまざまなハードウェア・アクセラレーターをシームレスに活用できます。AI Inference Server は、基盤となるハードウェアの複雑さを抽象化する統合された推論提供レイヤーを提供することで、優れた柔軟性と最適化の機会を提供します。
このマルチアクセラレーターのサポートにより、次のことが可能になります。
- パフォーマンスとコストの最適化:特定のモデルの特性、レイテンシーの要件、コストの考慮事項に基づいて、最適なアクセラレーターに推論ワークロードをデプロイできます。アクセラレーターは種類によって優れた能力を発揮する分野が異なるため、ジョブに適したハードウェアを選択できることで、パフォーマンスとリソース利用率が向上します。
- 将来を見据えたデプロイメント:AI Inference Server のアーキテクチャでは、より効率的な新しいアクセラレーター・テクノロジーが利用可能になった場合、提供インフラストラクチャやアプリケーションコードに大きな変更を加えることなく、それらを統合できます。これにより、長期的な実行可能性と適応性が実現します。
- 推論能力のスケーリング:同じタイプのアクセラレーターをさらに追加したり、さまざまな種類のアクセラレーターを組み込んで多様なワークロードの要求に対応したりと、推論能力を容易に拡張できます。これにより、変動するユーザートラフィックや、進化する AI モデルの複雑さに対応するために必要なアジリティが得られます。
- アクセラレーターの選択肢:さまざまなアクセラレーターベンダーを同じソフトウェア・インタフェースでサポートすることで、単一のハードウェアプロバイダーへの依存を減らし、ハードウェアの調達とコスト管理をより詳細に制御できます。
- インフラストラクチャ管理の単純化:AI Inference Server は、さまざまな種類のアクセラレーター間で一貫した管理インタフェースを提供します。これにより、異種ハードウェアでの推論サービスのデプロイと監視に伴う運用オーバーヘッドを単純化できます。
Red Hat の Neural Magic の専門知識を活用したモデル最適化
大規模な LLM を効率的にデプロイするには、多くの場合、最適化が必要です。AI Inference Server には、現在 Red Hat の傘下にある Neural Magic がもたらす先駆的なモデル最適化の専門知識を活用した強力な LLM 圧縮機能が統合されています。業界をリードする量子化およびスパース性技術 (SparseGPT など) を使用する統合圧縮機能は、精度を大幅に損なうことなく、モデルサイズと計算ニーズを大幅に削減します。これにより、推論速度が高速になり、リソース利用率が改善されるため、メモリーフットプリントが大幅に削減され、GPU メモリーに制約のあるシステムでもモデルを効果的に実行できます。
最適化されたモデルリポジトリによるアクセスの効率化
デプロイをさらに単純化するために、AI Inference Server には、人気のある LLM (Llama、Mistral、Granite ファミリーなど) の厳選されたリポジトリへのアクセスが含まれています。これらは Hugging Face のRed Hat AI ページでホストされているため便利に使えます。
これらは単なる標準モデルではなく、vLLM エンジンでの高性能実行に特化した統合圧縮技術を使用して最適化されています。これにより、デプロイの準備が整った効率的なモデルをすぐに利用でき、AI アプリケーションをプロダクションに導入するために必要な時間と労力が大幅に削減され、より迅速に価値を実現できます。
Red Hat AI Inference Server の技術概要

vLLM アーキテクチャは、特にさまざまな長さの多数の要求を同時に処理するシステムで、LLM 推論のスループットを最大化し、レイテンシーを最小化することを目指しています。この設計の中心には、EngineCore があります。これは専用の推論エンジンであり、フォワード・コンピュテーションを調整し、KV キャッシュを管理し、複数の同時プロンプトからのトークンを動的にバッチ処理します。
EngineCore は、長いコンテキストウィンドウの管理に関するオーバーヘッドを削減するだけでなく、実行時間の長いクエリで、短くてレイテンシーの影響を受けやすいリクエストをインテリジェントにプリエンプションまたはインターリーブします。これは、キューベースのスケジューリングと PagedAttention の組み合わせによって実現します。これは、各要求の KV キャッシュを仮想化する新しいアプローチです。実際、EngineCore は GPU メモリーの効率的な使用を改善するとともに、計算ステップ間のアイドル時間を短縮します。
ユーザー向けサービスと通信するために、EngineCoreClient はアダプターとして機能し、API (HTTP、gRPC など) とやり取りしてリクエストを EngineCore にリレーします。複数の EngineCoreClient が 1 つ以上の EngineCore と通信できるため、分散型またはマルチノードのデプロイメントが促進されます。vLLM は、リクエスト処理を低レベルの推論操作から明確に分離することで、複数の EngineCore へのロードバランシングや、ユーザーの需要に合わせたクライアント数のスケーリングなど、柔軟なインフラストラクチャ戦略を可能にします。
この分離によって、さまざまなサービス提供インタフェースと柔軟に統合できるだけでなく、分散型でスケーラブルなデプロイも実現できます。EngineCoreClient は別個のプロセスで実行され、ネットワークを介して 1 つ以上の EngineCore と通信して、負荷を分散し、CPU オーバーヘッドを減らすことができます。
Red Hat AI Inference Server の実行
RHEL での実行
$ podman run --rm -it --device nvidia.com/gpu=all -p 8000:8000 \
--ipc=host \
--env "HUGGING_FACE_HUB_TOKEN=$HF_TOKEN" \
--env "HF_HUB_OFFLINE=0" -v ~/.cache/vllm:/home/vllm/.cache \
--name=vllm \
registry.access.redhat.com/rhaiis/rh-vllm-cuda \
vllm serve \
--tensor-parallel-size 8 \
--max-model-len 32768 \
--enforce-eager --model RedHatAI/Llama-4-Scout-17B-16E-Instruct-FP8-dynamicOpenShift での実行
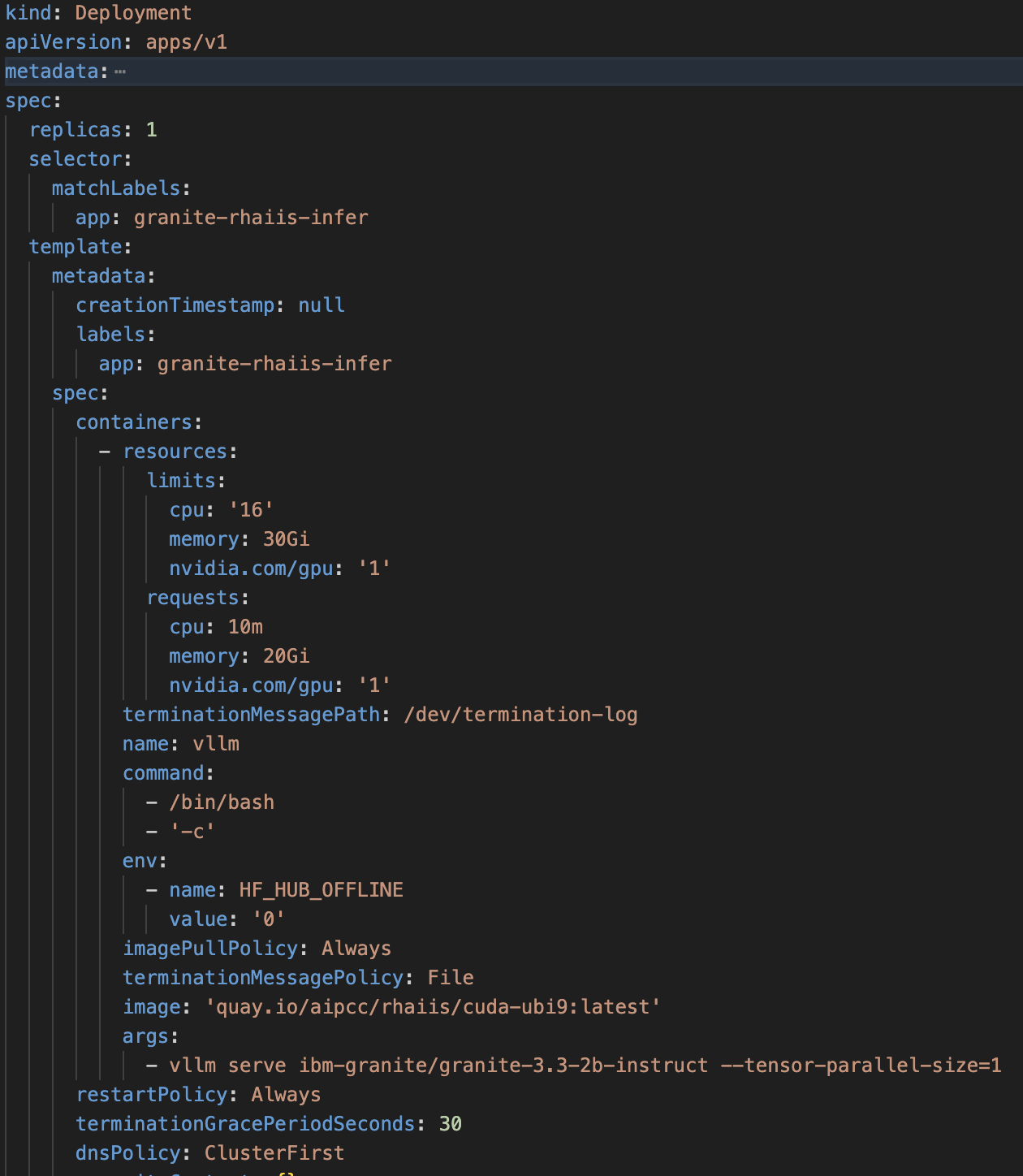
AI Inference Server の OpenShift デプロイメント仕様の例:
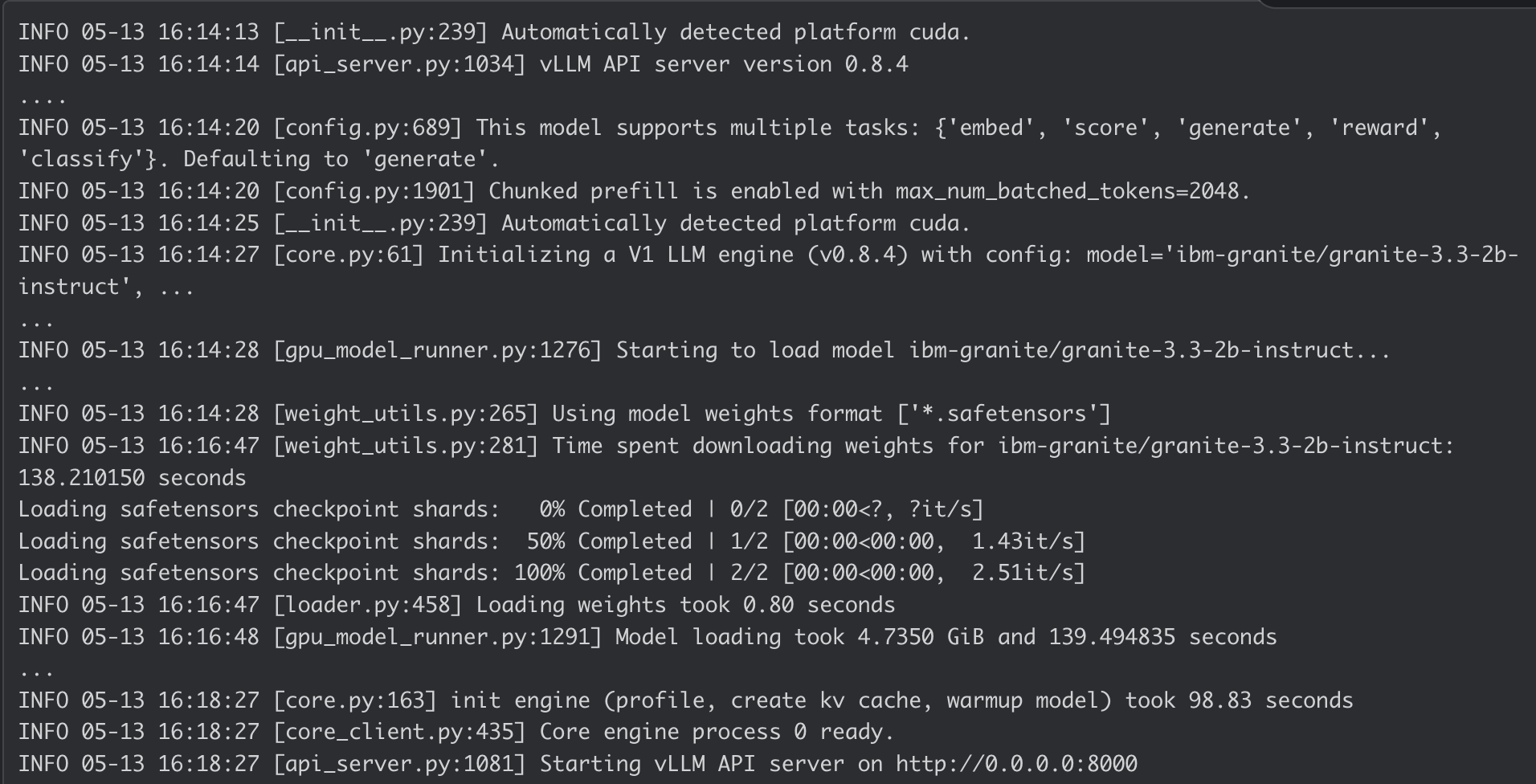
AI Inference Server コンテナのログ:
まとめ
Red Hat AI Inference Server は、最先端のパフォーマンスと、必要とされるデプロイメントの柔軟性を兼ね備えています。コンテナであるため、ハイブリッドクラウドの柔軟性がもたらされ、データやアプリケーションが存在する場所に一貫して最先端の AI 推論をデプロイすることができるので、エンタープライズ AI ワークロードのための強力な基盤となります。
詳細については、Red Hat AI Inference Server の Web ページおよび当社のガイド付きデモをご覧ください。また、詳細な設定については Red Hat の技術ドキュメントをご確認ください。
Product
Red Hat AI Inference Server
執筆者紹介

Erwan Gallen is Senior Principal Product Manager, Generative AI, at Red Hat, where he follows Red Hat AI Inference Server product and manages hardware-accelerator enablement across OpenShift, RHEL AI, and OpenShift AI. His remit covers strategy, roadmap, and lifecycle management for GPUs, NPUs, and emerging silicon, ensuring customers can run state-of-the-art generative workloads seamlessly in hybrid clouds.
Before joining Red Hat, Erwan was CTO and Director of Engineering at a media firm, guiding distributed teams that built and operated 100 % open-source platforms serving more than 60 million monthly visitors. The experience sharpened his skills in hyperscale infrastructure, real-time content delivery, and data-driven decision-making.
Since moving to Red Hat he has launched foundational accelerator plugins, expanded the company’s AI partner ecosystem, and advised Fortune 500 global enterprises on production AI adoption. An active voice in the community, he speaks regularly at NVIDIA GTC, Red Hat Summit, OpenShift Commons, CERN, and the Open Infra Summit.

Carlos Condado is a Senior Product Marketing Manager for Red Hat AI. He helps organizations navigate the path from AI experimentation to enterprise-scale deployment by guiding the adoption of MLOps practices and integration of AI models into existing hybrid cloud infrastructures. As part of the Red Hat AI team, he works across engineering, product, and go-to-market functions to help shape strategy, messaging, and customer enablement around Red Hat’s open, flexible, and consistent AI portfolio.
With a diverse background spanning data analytics, integration, cybersecurity, and AI, Carlos brings a cross-functional perspective to emerging technologies. He is passionate about technological innovations and helping enterprises unlock the value of their data and gain a competitive advantage through scalable, production-ready AI solutions.

チャンネル別に見る

自動化
テクノロジー、チームおよび環境に関する IT 自動化の最新情報

AI (人工知能)
お客様が AI ワークロードをどこでも自由に実行することを可能にするプラットフォームについてのアップデート

オープン・ハイブリッドクラウド
ハイブリッドクラウドで柔軟に未来を築く方法をご確認ください。

セキュリティ
環境やテクノロジー全体に及ぶリスクを軽減する方法に関する最新情報

エッジコンピューティング
エッジでの運用を単純化するプラットフォームのアップデート

インフラストラクチャ
世界有数のエンタープライズ向け Linux プラットフォームの最新情報

アプリケーション
アプリケーションの最も困難な課題に対する Red Hat ソリューションの詳細
仮想化
オンプレミスまたは複数クラウドでのワークロードに対応するエンタープライズ仮想化の将来についてご覧ください