Das Tempo der Innovationen im Bereich der generativen KI (gen KI) erfordert leistungsstarke, flexible und effiziente Lösungen für die Bereitstellung von großen Sprachmodellen (Large Language Models, LLMs). Heute stellen wir Ihnen Red Hat AI Inference Server vor. Als Schlüsselkomponente der Red Hat AI Plattform ist es in Red Hat OpenShift AI und Red Hat Enterprise Linux AI (RHEL AI) enthalten. AI Inference Server ist auch als Standalone-Produkt verfügbar, um optimierte LLM-Inferenzfunktionen mit echter Portierbarkeit in Ihren Hybrid Cloud-Umgebungen bereitzustellen.
AI Inference Server bietet Nutzenden in beliebigen Deployment-Umgebungen eine gehärtete, unterstützte vLLM-Distribution zusammen mit intelligenten LLM-Komprimierungstools und einem optimierten Modell-Repository auf Hugging Face, unterstützt durch den Enterprise-Support von Red Hat und die Flexibilität beim Einsatz von Drittanbietern gemäß der Support-Richtlinie für Drittanbieter von Red Hat.
Beschleunigte Inferenz mit einem vLLM-Kern und erweiterter Parallelverarbeitung
Das Kernstück von AI Inference Server ist die vLLM Serving Engine. vLLM ist bekannt für die hohe Durchsatz- und speichereffiziente Leistung. Sie wird erreicht durch innovative Techniken wie PagedAttention (Optimierung der GPU-Speicherverwaltung, entwickelt im Rahmen der Forschung an der University of California, Berkeley) und kontinuierliches Batching und erzielt im Vergleich zu traditionellen Verfahren oft eine um ein Vielfaches höhere Performance. Der Server stellt außerdem normalerweise einen OpenAI-kompatiblen API-Endpunkt bereit, was die Integration vereinfacht.
Um die heutigen, umfangreichen gen KI-Modelle auf unterschiedlicher Hardware handhaben zu können, bietet vLLM robuste Inferenzoptimierungen:
- Tensorparallelität (TP): Teilt einzelne Modellschichten auf mehrere GPUs auf, normalerweise in einem Knoten, um die Latenz zu reduzieren und den Rechendurchsatz für diese Schicht zu erhöhen.
- Pipeline-Parallelität (PP): Stellt sequenzielle Gruppen von Modellschichten auf verschiedenen GPUs oder Knoten bereit. Dies ist entscheidend für die Anpassung von Modellen, die selbst für einen einzelnen Multi-GPU-Knoten zu groß sind.
- Expertenparallelität (EP) für Mischungen von Experts Models (MoE): vLLM enthält spezielle Optimierungen für eine effiziente Handhabung von MoE-Modellarchitekturen und verwaltet ihre besonderen Routing- und Berechnungsanforderungen.
- Datenparallelität (DP): vLLM unterstützt Parallel Attention für Daten, wobei einzelne Anforderungen an verschiedene vLLM-Engines weitergeleitet werden. In den MoE-Schichten verbinden sich die datenparallelen Engines und teilen die Experts auf die datenparallelen und tensorparallelen Worker auf. Dies ist besonders wichtig bei Modellen wie DeepSeek V3 oder Qwen3 mit einer kleinen Anzahl von KV Heads (Key Value Attention), bei denen die Tensorparallelität zu einer unnötigen KV Cache-Duplizierung führt. Durch die Datenparallelität kann vLLM in diesem Fall auf eine größere Anzahl von GPUs skaliert werden.
- Quantisierung: LLM Compressor, eine Komponente von AI Inference Server, bietet eine einheitliche Library zur Erstellung komprimierter Modelle mit Gewichtungs- und Aktivierungsquantisierung oder reiner Gewichtungsquantisierung für eine schnellere Inferenz mit vLLM. vLLM verfügt über benutzerdefinierte Kernel wie Marlin und Machete für eine optimierte Performance durch Quantisierung.
- Spekulative Dekodierung: Spekulative Dekodierung verbessert die Inferenzlatenz, indem ein kleineres, schnelleres Entwurfsmodell verwendet wird, um mehrere zukünftige Token zu generieren, die dann vom größeren Hauptmodell in weniger Schritten validiert oder korrigiert werden. Durch diesen Ansatz wird die Dekodierungslatenz insgesamt reduziert und der Durchsatz erhöht, ohne die Ausgabequalität zu beeinträchtigen.
Diese Techniken können oft kombiniert werden, um beispielsweise die Pipeline-Parallelität in verschiedenen Knoten und die Tensorparallelität innerhalb einzelner Knoten zu verwenden. Dies ermöglicht eine effektive Skalierung der größten Modelle über komplexe Hardware-Topologien hinweg.
Deployment-Portierbarkeit per Containerisierung
AI Inference Server wird als standardmäßiges Container Image bereitgestellt und bietet beispiellose flexible Deployment-Flexibilität. Dieses containerisierte Format ist der Schlüssel für die Portierbarkeit der Hybrid Cloud und stellt sicher, dass genau dieselbe Inferenzumgebung konsistent ausgeführt wird, unabhängig davon, ob sie über Red Hat OpenShift, Red Hat Enterprise Linux (RHEL), Nicht-Red Hat Kubernetes-Plattformen oder andere Linux-Standardsysteme bereitgestellt wird. Dies sorgt für eine standardisierte, vorhersagbare Basis, um LLMs dort bereitzustellen, wo Ihr Unternehmen sie benötigt, und vereinfacht die Abläufe in verschiedenen Infrastrukturen.
Multi Accelerator Support
AI Inference Server wurde mit robustem Support für mehrere Beschleuniger als zentrales Designprinzip entwickelt. So kann die Plattform nahtlos verschiedene Hardware-Beschleuniger nutzen, darunter NVIDIA- oder AMD-GPUs sowie Google-TPUs. Durch die Bereitstellung einer einheitlichen Inferenz-Serving-Schicht, die die Komplexität der zugrunde liegenden Hardware abstrahiert, bietet AI Inference Server erhebliche Flexibilität und Optimierungsmöglichkeiten.
Dieser Multi Accelerator Support ermöglicht Nutzenden:
- Optimierung im Hinblick auf Performance und Kosten: Deployment von Inferenz-Workloads auf dem am besten geeigneten Beschleuniger basierend auf den spezifischen Modellmerkmalen, Latenzanforderungen und Kostenüberlegungen. Verschiedene Beschleuniger erzielen in unterschiedlichen Bereichen hervorragende Leistungen. Die Möglichkeit, die richtige Hardware für den jeweiligen Job auszuwählen, führt zu einer besseren Performance und Ressourcennutzung.
- Zukunftssichere Deployments: Wenn neue und effizientere Beschleunigertechnologien verfügbar werden, ermöglicht die Architektur von AI Inference Server deren Integration, ohne dass wesentliche Änderungen an der Bereitstellungsinfrastruktur oder dem Anwendungscode erforderlich sind. Dies sorgt für Langlebigkeit und Anpassungsfähigkeit.
- Skalierung der Inferenzkapazität: Die Inferenzkapazität lässt sich auf einfache Weise skalieren, indem sie weitere Beschleuniger vom gleichen Typ oder verschiedene Typen von Beschleunigern hinzufügen, um unterschiedliche Workload-Anforderungen zu erfüllen. Dies sorgt für die erforderliche Agilität, um dem schwankenden Nutzerverkehr und der zunehmenden Komplexität des KI-Modells gerecht zu werden.
- Wahl des Beschleunigers: Durch die Unterstützung einer Vielzahl von Beschleunigeranbietern mit derselben Softwareschnittstelle verringert die Plattform die Abhängigkeit von einem einzelnen Hardwareanbieter und bietet eine bessere Kontrolle über die Hardwarebeschaffung und das Kostenmanagement.
- Vereinfachtes Infrastrukturmanagement: AI Inference Server bietet eine konsistente Management-Schnittstelle für verschiedene Arten von Beschleunigern und reduziert den operativen Aufwand, der mit dem Deployment und Monitoring von Inferenzservices auf heterogener Hardware verbunden ist.
Modelloptimierung durch die Expertise von Neural Magic bei Red Hat
Das effiziente Deployment massiver LLMs bedarf häufig einer Optimierung. AI Inference Server integriert leistungsstarke LLM-Komprimierungsfunktionen und nutzt dabei die bahnbrechende Expertise in der Modelloptimierung von Neural Magic, das jetzt Teil von Red Hat ist. Unter Verwendung branchenführender Quantisierungs- und Sparsity-Techniken wie SparseGPT reduziert der integrierte Komprimierer die Modellgröße und den Rechenaufwand drastisch, ohne dass es dabei zu einem signifikanten Genauigkeitsverlust kommt. Dies ermöglicht schnellere Inferenzgeschwindigkeiten und bessere Ressourcennutzung, was zu einer erheblichen Reduzierung des Speicherbedarfs führt und eine effektive Ausführung der Modelle auch auf Systemen mit begrenztem GPU-Speicher ermöglicht.
Verbesserter Zugriff mit einem optimierten Modell-Repository
Um das Deployment weiter zu vereinfachen, bietet AI Inference Server Zugriff auf ein kuratiertes Repository gängiger LLMs (beispielsweise Llama-, Mistral- und Granite-Familien), die praktischerweise auf der Seite von Red Hat AI auf Hugging Face gehostet werden.
Hierbei handelt es sich nicht um einfache Standardmodelle, denn diese Modelle wurden mithilfe integrierter Komprimierungstechniken speziell für eine hochleistungsfähige Ausführung auf der vLLM-Engine optimiert. Das bedeutet, dass Sie sofort einsatzfähige, effiziente Modelle erhalten. So reduzieren Sie den Zeit- und Arbeitsaufwand drastisch, um Ihre KI-Anwendungen in die Produktion zu bringen, und schaffen eine schnellere Wertschöpfung.
Technischer Überblick über Red Hat AI Inference Server

Die vLLM-Architektur zielt darauf ab, den Durchsatz zu maximieren und die Latenzzeit für LLM-Inferenzen zu minimieren, insbesondere in Systemen mit hoher Nebenläufigkeit und unterschiedlichen Anfragelängen. Im Zentrum dieses Designs steht EngineCore, eine dedizierte Inferenz-Engine, die Vorausberechnungen koordiniert, den KV-Cache verwaltet und Token, die von mehreren gleichzeitigen Prompts stammen, dynamisch verarbeitet.
EngineCore reduziert nicht nur den Overhead für die Verwaltung langer Kontextfenster, sondern verdrängt auch intelligente kurze, latenzempfindliche Anforderungen mit länger laufenden Abfragen. Dies wird durch eine Kombination aus warteschlangenbasierter Planung und PagedAttention erreicht. Dabei handelt es sich um einen neuartigen Ansatz, der den Schlüssel/Wert-Cache für die Anfragen virtualisiert. Tatsächlich verbessert EngineCore die effiziente GPU-Speichernutzung und reduziert gleichzeitig die Leerlaufzeit zwischen den Berechnungsschritten.
Bei der Schnittstelle zu benutzerorientierten Services fungiert der EngineCoreClient als Adapter, der mit APIs (HTTP, gRPC usw.) interagiert und Anforderungen an EngineCore weiterleitet. Mehrere EngineCoreClients können mit einem oder mehreren EngineCores kommunizieren und verteilte Bereitstellungen oder Bereitstellungen mit mehreren Knoten erleichtern. Durch die saubere Trennung der Anfragenverarbeitung von den Low Level-Inferenzvorgängen ermöglicht vLLM flexible Infrastrukturstrategien, wie Load Balancing auf mehrere EngineCores oder die Skalierung der Anzahl der Clients, um die Anforderungen der Nutzenden zu erfüllen.
Diese Absonderung ermöglicht nicht nur eine flexible Integration mit verschiedenen Schnittstellen, sondern auch eine verteilte und skalierbare Bereitstellung. EngineCoreClients können auf separaten Prozessen ausgeführt werden und mit einem oder mehreren EngineCores über das Netzwerk kommunizieren, um Belastungen auszugleichen und den CPU-Overhead zu verringern.
Ausführen von Red Hat AI Inference Server
Ausführen auf RHEL
$ podman run --rm -it --device nvidia.com/gpu=all -p 8000:8000 \
--ipc=host \
--env "HUGGING_FACE_HUB_TOKEN=$HF_TOKEN" \
--env "HF_HUB_OFFLINE=0" -v ~/.cache/vllm:/home/vllm/.cache \
--name=vllm \
registry.access.redhat.com/rhaiis/rh-vllm-cuda \
vllm serve \
--tensor-parallel-size 8 \
--max-model-len 32768 \
--enforce-eager --model RedHatAI/Llama-4-Scout-17B-16E-Instruct-FP8-dynamicAusführen auf OpenShift
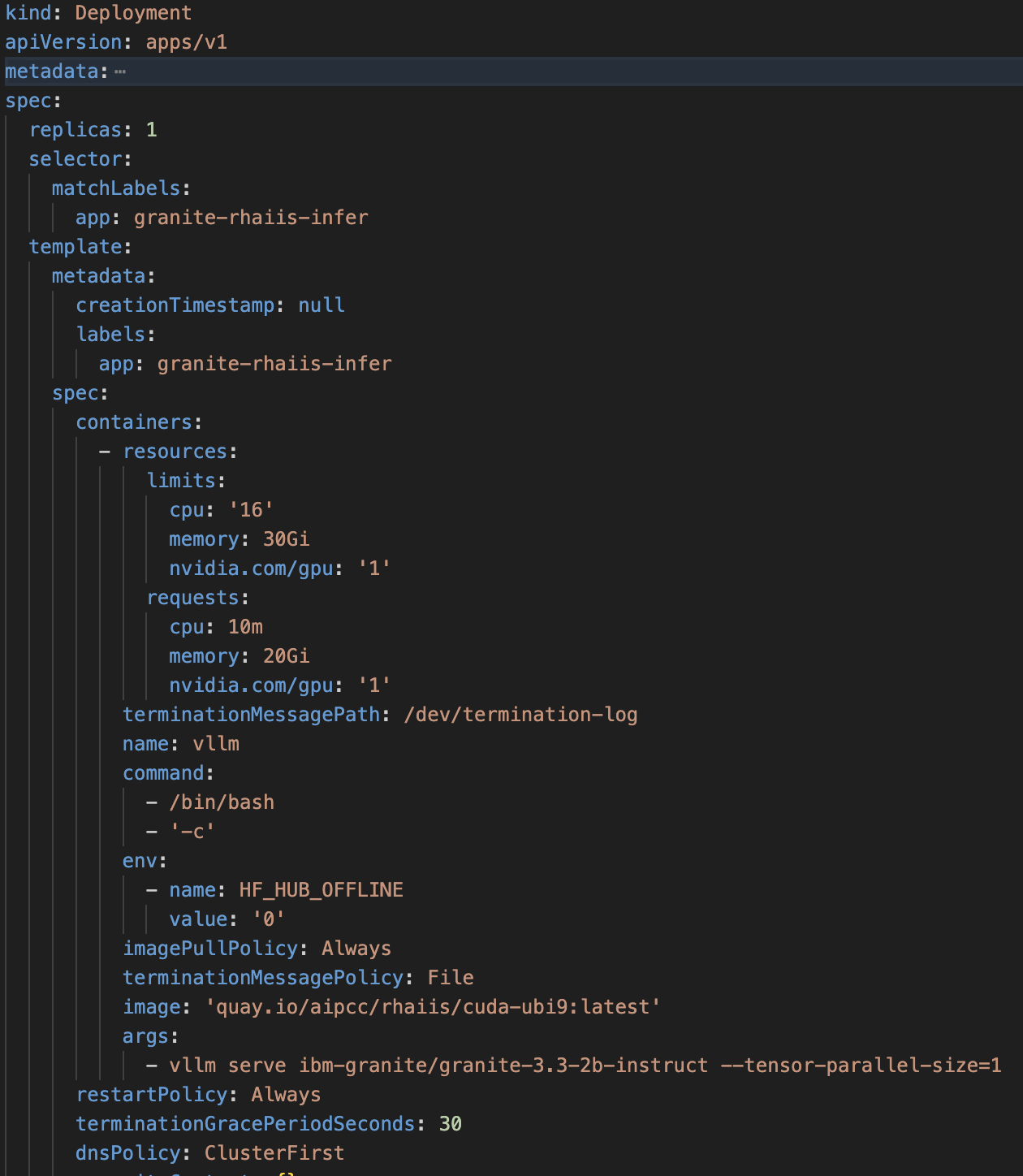
Beispiel einer OpenShift-Bereitstellungsspezifikation für AI Inference Server:
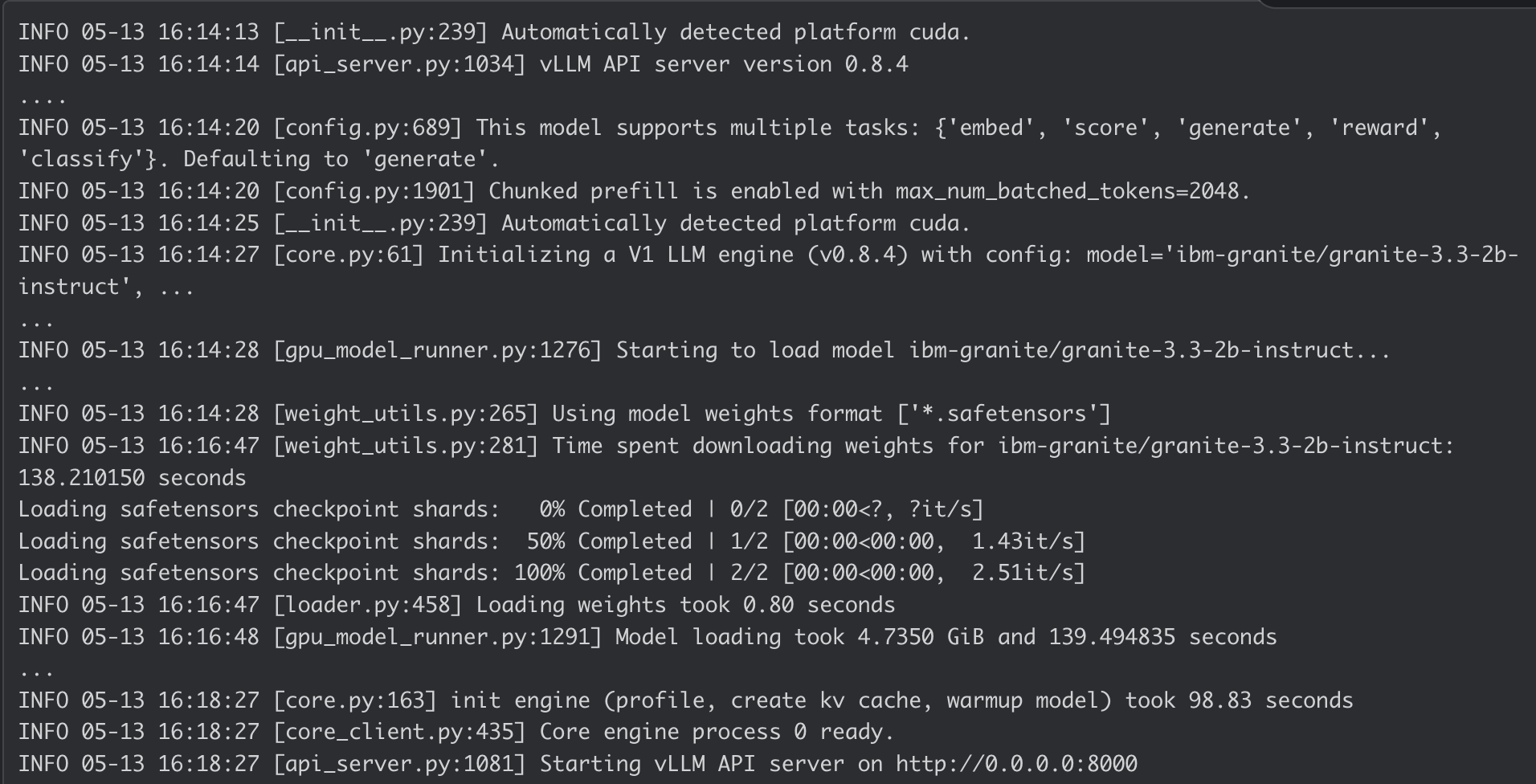
Container-Protokoll für AI Inference Server:
Fazit
Red Hat AI Inference Server kombiniert erstklassige Performance mit der Flexibilität beim Deployment, die Sie benötigen. Die containerisierte Struktur bietet echte Hybrid Cloud-Flexibilität und ermöglicht Ihnen so eine konsistente Bereitstellung moderner KI-Inferenz unabhängig davon, wo sich Ihre Daten und Anwendungen befinden. So erhalten Sie eine leistungsstarke Basis für Ihre Unternehmens-KI-Workloads.
Entdecken Sie die Webseite zu Red Hat AI Inference Server und unsere angeleitete Demo, oder sehen Sie sich unsere technische Dokumentation für detaillierte Konfigurationen an.
Product
Red Hat AI Inference Server
Über die Autoren

Erwan Gallen is Senior Principal Product Manager, Generative AI, at Red Hat, where he follows Red Hat AI Inference Server product and manages hardware-accelerator enablement across OpenShift, RHEL AI, and OpenShift AI. His remit covers strategy, roadmap, and lifecycle management for GPUs, NPUs, and emerging silicon, ensuring customers can run state-of-the-art generative workloads seamlessly in hybrid clouds.
Before joining Red Hat, Erwan was CTO and Director of Engineering at a media firm, guiding distributed teams that built and operated 100 % open-source platforms serving more than 60 million monthly visitors. The experience sharpened his skills in hyperscale infrastructure, real-time content delivery, and data-driven decision-making.
Since moving to Red Hat he has launched foundational accelerator plugins, expanded the company’s AI partner ecosystem, and advised Fortune 500 global enterprises on production AI adoption. An active voice in the community, he speaks regularly at NVIDIA GTC, Red Hat Summit, OpenShift Commons, CERN, and the Open Infra Summit.

Carlos Condado is a Senior Product Marketing Manager for Red Hat AI. He helps organizations navigate the path from AI experimentation to enterprise-scale deployment by guiding the adoption of MLOps practices and integration of AI models into existing hybrid cloud infrastructures. As part of the Red Hat AI team, he works across engineering, product, and go-to-market functions to help shape strategy, messaging, and customer enablement around Red Hat’s open, flexible, and consistent AI portfolio.
With a diverse background spanning data analytics, integration, cybersecurity, and AI, Carlos brings a cross-functional perspective to emerging technologies. He is passionate about technological innovations and helping enterprises unlock the value of their data and gain a competitive advantage through scalable, production-ready AI solutions.

Mehr davon
Nach Thema durchsuchen

Automatisierung
Das Neueste zum Thema IT-Automatisierung für Technologien, Teams und Umgebungen

Künstliche Intelligenz
Erfahren Sie das Neueste von den Plattformen, die es Kunden ermöglichen, KI-Workloads beliebig auszuführen

Open Hybrid Cloud
Erfahren Sie, wie wir eine flexiblere Zukunft mit Hybrid Clouds schaffen.

Sicherheit
Erfahren Sie, wie wir Risiken in verschiedenen Umgebungen und Technologien reduzieren

Edge Computing
Erfahren Sie das Neueste von den Plattformen, die die Operations am Edge vereinfachen

Infrastruktur
Erfahren Sie das Neueste von der weltweit führenden Linux-Plattform für Unternehmen

Anwendungen
Entdecken Sie unsere Lösungen für komplexe Herausforderungen bei Anwendungen
Virtualisierung
Erfahren Sie das Neueste über die Virtualisierung von Workloads in Cloud- oder On-Premise-Umgebungen