O ritmo da inovação da IA generativa (gen IA) exige soluções avançadas, flexíveis e eficientes para a implantação de Large Language Models (LLMs). Hoje, apresentamos o Red Hat AI Inference Server. Como um componente essencial da plataforma Red Hat AI, ele está incluído no Red Hat OpenShift AI e no Red Hat Enterprise Linux AI (RHEL AI). O AI Inference Server também está disponível como uma solução independente, criada para oferecer recursos otimizados de inferência de LLM com portabilidade verdadeira em seus ambientes de nuvem híbrida.
O AI Inference Server oferece aos usuários uma distribuição fortalecida e compatível do vLLM em qualquer ambiente de implantação, além de ferramentas inteligentes de compactação de LLM e um repositório otimizado de modelos no Hugging Face. Tudo isso com o suporte empresarial da Red Hat e a flexibilidade de implantação de terceiros, conforme a política de suporte de terceiros da Red Hat.
Como acelerar a inferência com um núcleo e paralelismo avançado de vLLM
O mecanismo de inferência vLLM é parte fundamental do AI Inference Server. Ele é conhecido por sua alta taxa de transferência e desempenho com eficiência de memória, propiciados por técnicas inovadoras, como PagedAttention (com otimização do gerenciamento de memória de GPU, originado de uma pesquisa na Universidade da Califórnia, Berkeley). As técnicas também incluem processamento contínuo em lotes, que muitas vezes tem um desempenho muito superior em comparação aos métodos de inferência tradicionais. Além disso, o servidor simplifica a integração expondo um endpoint de API compatível com OpenAI.
Para lidar com os enormes modelos de gen IA atuais em diversos hardwares, o vLLM oferece otimizações de inferência robustas:
- Paralelismo de tensores (TP): divide camadas de modelos individuais em várias GPUs, normalmente em um nó, reduzindo a latência e aumentando a taxa de transferência computacional dessa camada.
- Paralelismo de pipelines (PP): prepara grupos sequenciais de camadas de modelo em diferentes GPUs ou nós. Isso é crucial para ajustar modelos que são muito grandes, mesmo que seja para um único nó de várias GPUs.
- Paralelismo de especialistas (EP) para modelos de combinação de especialistas (MoE): o vLLM inclui otimizações especializadas para lidar com arquiteturas de modelos MoE com eficiência, gerenciando necessidades exclusivas de roteamento e computação.
- Paralelismo de dados (DP): o vLLM é compatível com atenção paralela a dados, que encaminha solicitações individuais para diferentes mecanismos de vLLM. Ao longo das camadas de MoE, os mecanismos de paralelismo de dados se unem, fragmentando especialistas por todos os trabalhadores de paralelismo de dados e de tensores. Isso é ainda mais importante em modelos como DeepSeek V3 ou Qwen3, que usam um pequeno número de cabeças de atenção de chave-valor (KV), onde o paralelismo de tensores causa duplicação desnecessária do cache de KV. Com o paralelismo de dados, o vLLM escala para um número maior de GPUs nesse caso.
- Quantização: o LLM Compressor, um componente do AI Inference Server, oferece uma biblioteca unificada para criar modelos compactados com quantização de peso e ativação ou quantização apenas de peso para inferência mais rápida com o vLLM. O vLLM tem kernels personalizados, como Marlin e Machete, para desempenho otimizado com quantização.
- Decodificação especulativa: melhora a latência de inferência usando um modelo de rascunho menor e mais rápido para gerar vários tokens futuros, os quais são então validados ou corrigidos pelo modelo principal maior em menos etapas. Essa abordagem reduz a latência geral de decodificação e aumenta a taxa de transferência sem prejudicar a qualidade da saída.
É importante observar que essas técnicas podem ser combinadas para escalar com eficiência os maiores modelos em topologias de hardware complexas. Por exemplo, usando o paralelismo de pipelines entre nós e o paralelismo de tensores dentro de cada nó.
Portabilidade de implantação por meio da conteinerização
O AI Inference Server é disponibilizado como uma imagem de container padrão e oferece flexibilidade de implantação inigualável. Esse formato em containers é essencial para sua portabilidade em nuvem híbrida, garantindo a execução consistente do mesmo ambiente de inferência, seja a implantação por meio do Red Hat OpenShift, Red Hat Enterprise Linux (RHEL), outras plataformas Kubernetes ou outros sistemas Linux padrão. Ele oferece uma base padronizada e previsível para atender aos LLMs onde quer que sua empresa precise, simplificando as operações em diversas infraestruturas.
Suporte a vários aceleradores
O AI Inference Server foi criado com suporte robusto a vários aceleradores como um princípio essencial de design. Esse recurso permite que a plataforma aproveite de forma simplificada uma ampla variedade de aceleradores de hardware, incluindo NVIDIA, GPUs da AMD e TPUs do Google. Com uma camada unificada de entrega de inferência que abstrai as complexidades do hardware subjacente, o AI Inference Server oferece oportunidades significativas de flexibilidade e otimização.
Esse suporte a vários aceleradores permite aos usuários:
- Otimizar para desempenho e custo: implante cargas de trabalho de inferência no acelerador mais adequado com base nas características específicas do modelo, requisitos de latência e considerações de custo. Diferentes aceleradores se destacam em diferentes áreas, e a capacidade de escolher o hardware certo para a tarefa resulta em desempenho e utilização de recursos aprimorados.
- Obter implantações prontas para o futuro: à medida que novas e mais eficientes tecnologias de acelerador ficam disponíveis, a arquitetura do AI Inference Server permite a integração delas sem exigir alterações significativas na infraestrutura de inferência ou no código da aplicação. Isso oferece viabilidade e adaptabilidade a longo prazo.
- Escalar a capacidade de inferência: escale facilmente a capacidade de inferência adicionando mais aceleradores do mesmo tipo ou incorporando diferentes tipos de aceleradores para lidar com diversas demandas de carga de trabalho. Dessa forma, você obtém a agilidade necessária para lidar com as complexidades do tráfego oscilante de usuários e dos modelos de IA em constante evolução.
- Escolher o acelerador: com suporte a vários fornecedores de acelerador com a mesma interface de software, a plataforma reduz a dependência de um único fornecedor de hardware, dando a você maior controle sobre a aquisição de hardware e o gerenciamento de custos.
- Simplificar o gerenciamento de infraestruturas: o AI Inference Server oferece uma interface de gerenciamento consistente em diferentes tipos de aceleradores, simplificando a despesa operacional associada à implantação e monitoramento de serviços de inferência em hardware heterogêneo.
Otimização de modelos com base na expertise da Neural Magic na Red Hat
A implantação eficiente de LLMs em massa geralmente exige otimização. O AI Inference Server integra recursos avançados de compactação de LLM, aproveitando a expertise pioneira em otimização de modelos da Neural Magic, agora parte da Red Hat. Com técnicas líderes do setor de quantização e dispersão, como o SparseGPT, o compressor integrado reduz drasticamente o tamanho do modelo e as necessidades computacionais sem perda significativa de precisão. Isso permite inferências mais rápidas e melhor utilização de recursos, resultando em reduções substanciais no volume de memória e possibilitando a execução dos modelos com eficiência, mesmo em sistemas com memória de GPU limitada.
Acesso simplificado com um repositório de modelos otimizado
Para simplificar ainda mais a implantação, o AI Inference Server inclui acesso a um repositório selecionado de LLMs conhecidos (como as famílias Llama, Mistral e Granite), estrategicamente hospedados na página da Red Hat AI no Hugging Face.
Eles não são apenas modelos padrão, eles foram otimizados usando técnicas de compactação integradas, especificamente para execução de alto desempenho no mecanismo vLLM. Isso significa que você obtém modelos eficientes e prontos para implantação, reduzindo muito o tempo e o esforço necessários para colocar suas aplicações de IA em produção, agregando valor mais rapidamente.
Visão geral técnica do Red Hat AI Inference Server

A arquitetura de vLLM busca maximizar a taxa de transferência e minimizar a latência na inferência de LLM, principalmente em sistemas que lidam com alta concorrência com comprimentos variados de solicitação. Esse design conta com o EngineCore, um mecanismo de inferência dedicado que coordena computações diretas, gerencia o cache de KV e agrupa dinamicamente tokens provenientes de vários prompts simultâneos.
Além de reduzir a sobrecarga de gerenciamento de longas janelas de contexto, o EngineCore também antecipa ou intercala de maneira inteligente solicitações curtas e sensíveis à latência com consultas mais longas. Isso é feito por meio de uma combinação de programação baseada em fila e PagedAttention, uma nova abordagem que virtualiza o cache de chave-valor para cada solicitação. Em termos práticos, o EngineCore melhora o uso eficiente da memória da GPU e reduz o tempo ocioso entre as etapas de computação.
Para interagir com os serviços voltados ao usuário, o EngineCoreClient atua como um adaptador que interage com as APIs (HTTP, gRPC, etc.) e transmite solicitações ao EngineCore. Vários EngineCoreClients podem se comunicar com um ou mais EngineCores, facilitando implantações distribuídas ou de vários nós. O vLLM separa claramente o gerenciamento de solicitações das operações de inferência de baixo nível, permitindo estratégias de infraestrutura flexíveis, como o balanceamento de carga em vários EngineCores ou a escalabilidade do número de clientes para corresponder à demanda do usuário.
Essa separação permite a integração flexível com várias interfaces de disponibilização e possibilita a implantação distribuída e escalável. Os EngineCoreClients podem ser executados em processos separados, comunicando-se com um ou mais EngineCores pela rede para balancear a carga e diminuir a despesa operacional da CPU.
Execução do Red Hat AI Inference Server
Execução no RHEL
$ podman run --rm -it --device nvidia.com/gpu=all -p 8000:8000 \
--ipc=host \
--env "HUGGING_FACE_HUB_TOKEN=$HF_TOKEN" \
--env "HF_HUB_OFFLINE=0" -v ~/.cache/vllm:/home/vllm/.cache \
--name=vllm \
registry.access.redhat.com/rhaiis/rh-vllm-cuda \
vllm serve \
--tensor-parallel-size 8 \
--max-model-len 32768 \
--enforce-eager --model RedHatAI/Llama-4-Scout-17B-16E-Instruct-FP8-dynamicExecução no OpenShift
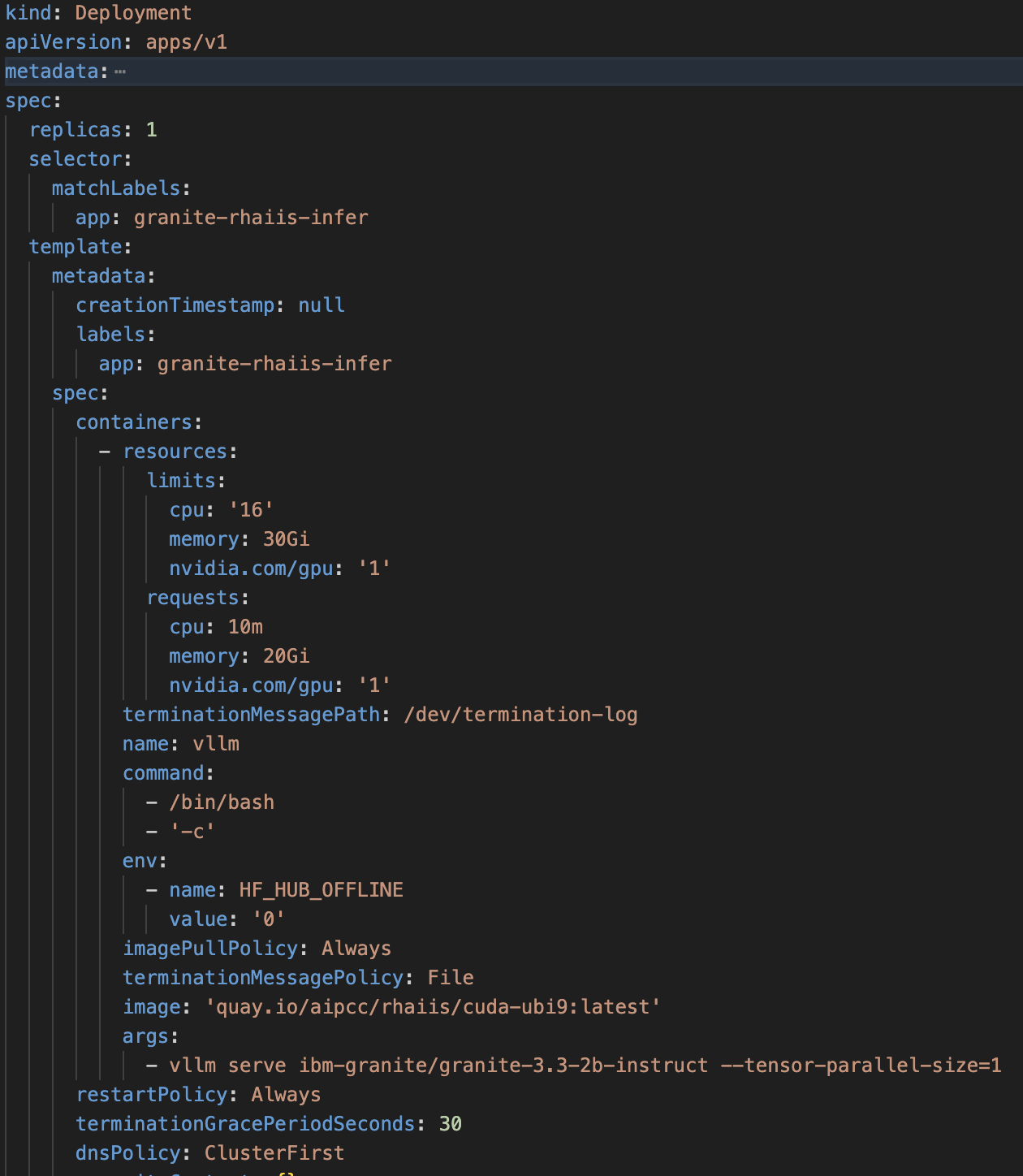
Exemplo de especificação de uma implantação do OpenShift para o AI Inference Server:
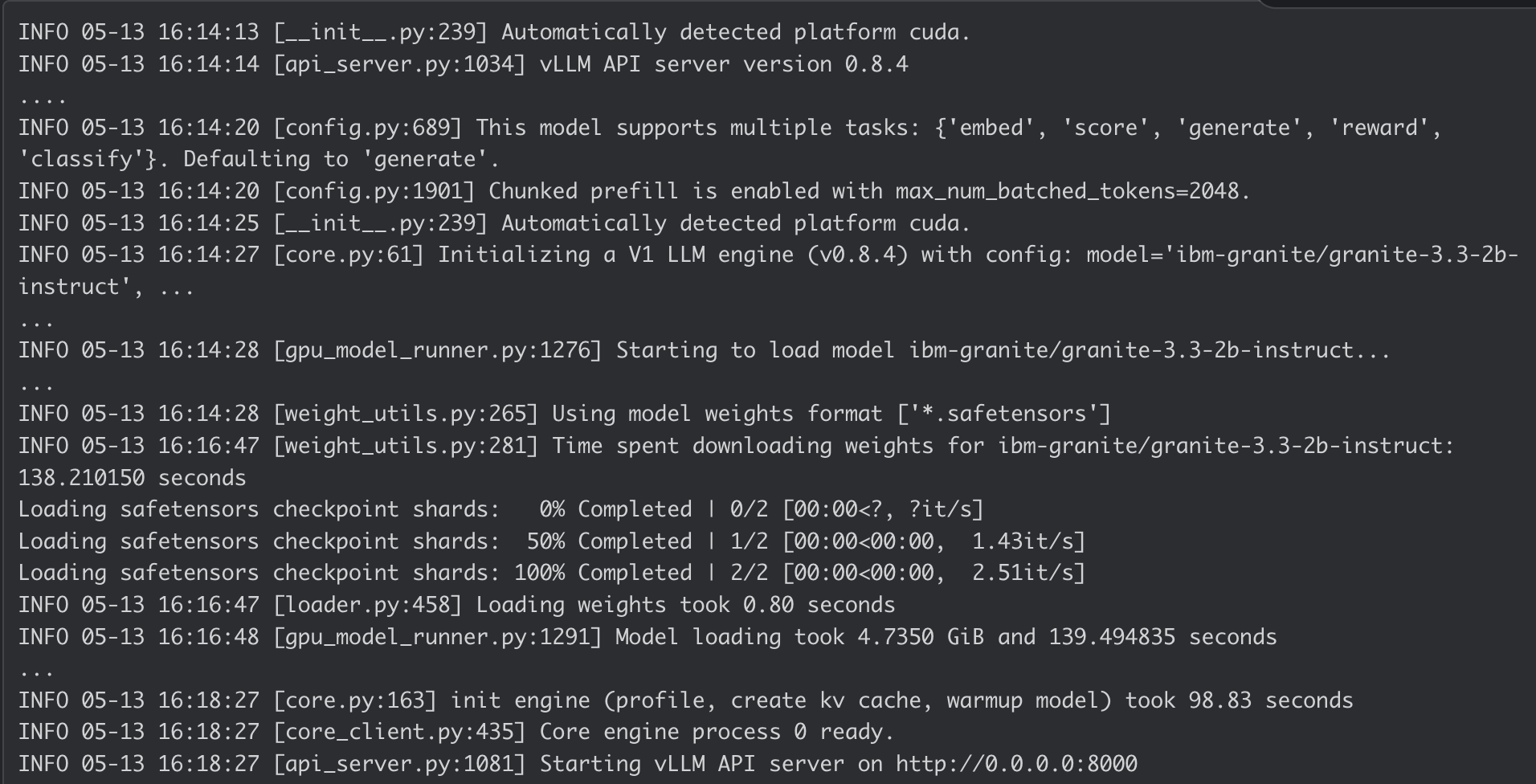
Log do container do AI Inference Server:
Conclusão
O Red Hat AI Inference Server combina desempenho de ponta com a flexibilidade de implantação de que você precisa. A natureza conteinerizada dele proporciona a verdadeira flexibilidade da nuvem híbrida. Dessa forma, você pode implantar inferência de IA de ponta com consistência onde quer que seus dados e aplicações estejam, oferecendo uma base poderosa para suas cargas de trabalho de IA empresarial.
Confira a página do Red Hat AI Inference Server e nossa demonstração guiada para mais informações. Você também pode ver nossa documentação técnica com configurações detalhadas.
Product
Red Hat AI Inference Server
Sobre os autores

Erwan Gallen is Senior Principal Product Manager, Generative AI, at Red Hat, where he follows Red Hat AI Inference Server product and manages hardware-accelerator enablement across OpenShift, RHEL AI, and OpenShift AI. His remit covers strategy, roadmap, and lifecycle management for GPUs, NPUs, and emerging silicon, ensuring customers can run state-of-the-art generative workloads seamlessly in hybrid clouds.
Before joining Red Hat, Erwan was CTO and Director of Engineering at a media firm, guiding distributed teams that built and operated 100 % open-source platforms serving more than 60 million monthly visitors. The experience sharpened his skills in hyperscale infrastructure, real-time content delivery, and data-driven decision-making.
Since moving to Red Hat he has launched foundational accelerator plugins, expanded the company’s AI partner ecosystem, and advised Fortune 500 global enterprises on production AI adoption. An active voice in the community, he speaks regularly at NVIDIA GTC, Red Hat Summit, OpenShift Commons, CERN, and the Open Infra Summit.

Carlos Condado is a Senior Product Marketing Manager for Red Hat AI. He helps organizations navigate the path from AI experimentation to enterprise-scale deployment by guiding the adoption of MLOps practices and integration of AI models into existing hybrid cloud infrastructures. As part of the Red Hat AI team, he works across engineering, product, and go-to-market functions to help shape strategy, messaging, and customer enablement around Red Hat’s open, flexible, and consistent AI portfolio.
With a diverse background spanning data analytics, integration, cybersecurity, and AI, Carlos brings a cross-functional perspective to emerging technologies. He is passionate about technological innovations and helping enterprises unlock the value of their data and gain a competitive advantage through scalable, production-ready AI solutions.

Mais como este
Navegue por canal

Automação
Últimas novidades em automação de TI para empresas de tecnologia, equipes e ambientes

Inteligência artificial
Descubra as atualizações nas plataformas que proporcionam aos clientes executar suas cargas de trabalho de IA em qualquer ambiente

Nuvem híbrida aberta
Veja como construímos um futuro mais flexível com a nuvem híbrida

Segurança
Veja as últimas novidades sobre como reduzimos riscos em ambientes e tecnologias

Edge computing
Saiba quais são as atualizações nas plataformas que simplificam as operações na borda

Infraestrutura
Saiba o que há de mais recente na plataforma Linux empresarial líder mundial

Aplicações
Conheça nossas soluções desenvolvidas para ajudar você a superar os desafios mais complexos de aplicações
Virtualização
O futuro da virtualização empresarial para suas cargas de trabalho on-premise ou na nuvem