生成式 AI(gen AI)的创新步伐不断加快,必然需要强大、灵活且高效的解决方案来部署大语言模型(LLM)。今天,我们要介绍的正是红帽 AI 推理服务器。作为红帽 AI 平台的关键组件,它已集成到红帽 OpenShift AI 和红帽企业 Linux AI(RHEL AI)中。此外,AI 推理服务器也可作为独立产品提供,既能带来优化的 LLM 推理功能,亦有助于在混合云环境中实现真正的可移植性。
在任何部署环境中,AI 推理服务器都能为用户提供经过强化、受支持的 vLLM 发行版,以及智能 LLM 压缩工具和 Hugging Face 上的优化模型存储库,而且均享有红帽企业级支持,并依据红帽第三方支持政策提供灵活的第三方部署选项。
vLLM 核心与先进并行技术助力加速推理
AI 推理服务器的核心是 vLLM 服务引擎。vLLM 以高吞吐量和内存高效性能著称,这得益于 PagedAttension(源自加州大学伯克利分校的研究成果,可优化 GPU 内存管理)和连续批处理等创新技术,而且与传统服务方法相比,vLLM 通常能实现数倍的性能提升。此外,该服务器通常会提供兼容 OpenAI 的 API 端点,从而简化集成。
为了在多样化的硬件上处理现今规模庞大的生成式 AI 模型,vLLM 提供了强大的推理优化方案:
- 张量并行(TP):将各个模型层拆分到多个 GPU (通常在一个节点内),从而降低该层的延迟并提高计算吞吐量。
- 管道并行(PP):将模型层的顺序组划分到不同的 GPU 或节点上。对于即便在一个多 GPU 节点上也难以容纳的大型模型而言,这一技术至关重要。
- 针对混合专家(MoE)模型的专家并行(EP):vLLM 包含专门的优化,可高效处理 MoE 模型架构,并管理其独特的路由和计算需求。
- 数据并行(DP):vLLM 支持数据并行注意力机制,能够将各个请求路由到不同的 vLLM 引擎。在处理 MoE 层时,数据并行引擎会协同工作,将专家模型分片到所有数据并行和张量并行的工作节点上。这对于 DeepSeek V3 或 Qwen3 等具有少量键值注意力(KV)头的模型尤为重要,因为其中张量并行会导致 KV 缓存冗余复制,从而造成资源浪费,而数据并行则使 vLLM 能够在这种场景下扩展至更多 GPU。
- 量化:LLM 压缩器是 AI 推理服务器的一个组件,它提供了一个统一的库,用于创建采用权重和激活量化或仅权重量化的压缩模型,以配合 vLLM 实现更快推理。
- 推测解码:推测解码通过使用一个更小、更快的草稿模型来生成多个未来令牌,随后由更大的主模型以更少的步骤进行验证或纠正,从而改善推理延迟。这种方法可在不牺牲输出质量的情况下,减少总体解码延迟并提高吞吐量。
值得注意的是,这些技术通常可以组合使用(例如跨节点使用管道并行,在每个节点内使用张量并行),以在复杂的硬件拓扑中高效扩展超大型模型。
通过容器化实现部署可移植性
AI 推理服务器以标准容器镜像的形式交付,提供了出色的部署灵活性。这种容器化格式是其混合云可移植性的关键所在,确保无论通过红帽 OpenShift、红帽企业 Linux(RHEL)、非红帽 Kubernetes 平台还是其他标准 Linux 系统进行部署,推理环境都能保持完全一致。它提供了一个标准化、可预测的基础,可在业务所需的任何地方部署 LLM,从而简化跨不同基础架构的运维。
多加速器支持
AI 推理服务器以强大的多加速器支持为核心设计原则。这项功能使平台能够无缝利用各种硬件加速器,包括 NVIDIA、AMD GPU 和 Google TPU。AI 推理服务器还通过提供统一的推理服务层来抽象化处理底层硬件的复杂性,从而显著提升灵活性,并创造更多优化空间。
这种多加速器支持使用户能够:
- 针对性能和成本进行优化:根据具体的模型特征、延迟要求和成本考量,在最合适的加速器上部署推理工作负载。不同加速器在不同领域各有优势,为作业选择合适的硬件可以提高性能和资源利用率。
- 实施面向未来的部署:随着更高效的全新加速器技术的推出,AI 推理服务器的架构支持进行集成,而无需对服务基础架构或应用代码进行重大更改。这样便可确保长期可用性与适应性。
- 扩展推理容量:通过添加更多相同类型的加速器或合并不同类型的加速器来处理不同的工作负载需求,轻松扩展推理容量。这提供了所需的敏捷性来应对波动的用户流量和不断演变的 AI 模型复杂性。
- 加速器选择:通过使用相同的软件接口支持多种加速器供应商,该平台减少了对单一硬件供应商的依赖,从而在硬件采购和成本管理方面提供了更大的控制权。
- 简化基础架构管理:AI 推理服务器为不同类型的加速器提供了一致的管理接口,简化了与在异构硬件上部署和监控推理服务相关的运维开销。
由红帽 Neural Magic 专业知识提供支持的模型优化
高效部署大规模 LLM 通常需要进行优化。AI 推理服务器集成了强大的 LLM 压缩功能,并利用了红帽旗下 Neural Magic 带来的开创性模型优化专业知识。借助行业领先的量化和稀疏技术(如 SparseGPT),集成式压缩器能够大幅减小模型规模和计算需求,同时不会显著影响精度。这有助于加快推理速度、提高资源利用率,从而显著减少内存占用,甚至使模型能够在 GPU 内存有限的系统上高效运行。
优化模型存储库实现便捷访问
为进一步简化部署流程,AI 推理服务器支持访问精选的热门 LLM 存储库(如 Llama、Mistral 和 Granite 系列模型),这些模型便捷地托管在 Hugging Face 的红帽 AI 页面上。
这些不仅仅是标准模型,它们已使用集成压缩技术进行了优化,专门针对在 vLLM 引擎上实现高性能运行而设计。这意味着您可以获得开箱即用、易于部署的高效模型,大大减少将 AI 应用投入生产所需的时间和精力,并更快地实现价值。
红帽 AI 推理服务器技术概述

vLLM 架构力求最大限度提高 LLM 推理的吞吐量并尽可能减少延迟,尤其是在处理高并发且请求长度各异的系统中。该设计的核心是 EngineCore,这是一个专用的推理引擎,可以协调正向计算,管理 KV 缓存,以及对来自多个同步提示的令牌进行动态批处理。
EngineCore 不仅能够降低管理长上下文窗口的开销,还能智能地抢占处理或将对延迟敏感的短时请求与长时间运行的查询进行交错处理。这通过基于队列的调度与 PagedAttention(一种新颖的方法,为每个请求虚拟化键值缓存)相结合来实现。实际上,EngineCore 提高了 GPU 内存使用效率,同时减少了计算步骤之间的空闲时间。
为了与面向用户的服务交互,EngineCoreClient 充当与 API(HTTP、gRPC 等)交互并将请求中继到 EngineCore 的适配器。多个 EngineCoreClient 可以与一个或多个 EngineCore 通信,从而促进分布式或多节点部署。通过将请求处理与底层推理操作完全分离,vLLM 支持灵活的基础架构策略,例如跨多个 EngineCore 进行负载均衡,或根据用户需求扩展客户端数量。
这种分离不仅允许与各种服务接口灵活集成,还支持分布式和可扩展部署。EngineCoreClient 可以在单独的进程上运行,通过网络与一个或多个 EngineCore 通信,以实现负载平衡并降低 CPU 开销。
运行红帽 AI 推理服务器
在 RHEL 上运行
$ podman run --rm -it --device nvidia.com/gpu=all -p 8000:8000 \
--ipc=host \
--env "HUGGING_FACE_HUB_TOKEN=$HF_TOKEN" \
--env "HF_HUB_OFFLINE=0" -v ~/.cache/vllm:/home/vllm/.cache \
--name=vllm \
registry.access.redhat.com/rhaiis/rh-vllm-cuda \
vllm serve \
--tensor-parallel-size 8 \
--max-model-len 32768 \
--enforce-eager --model RedHatAI/Llama-4-Scout-17B-16E-Instruct-FP8-dynamic在 OpenShift 上运行
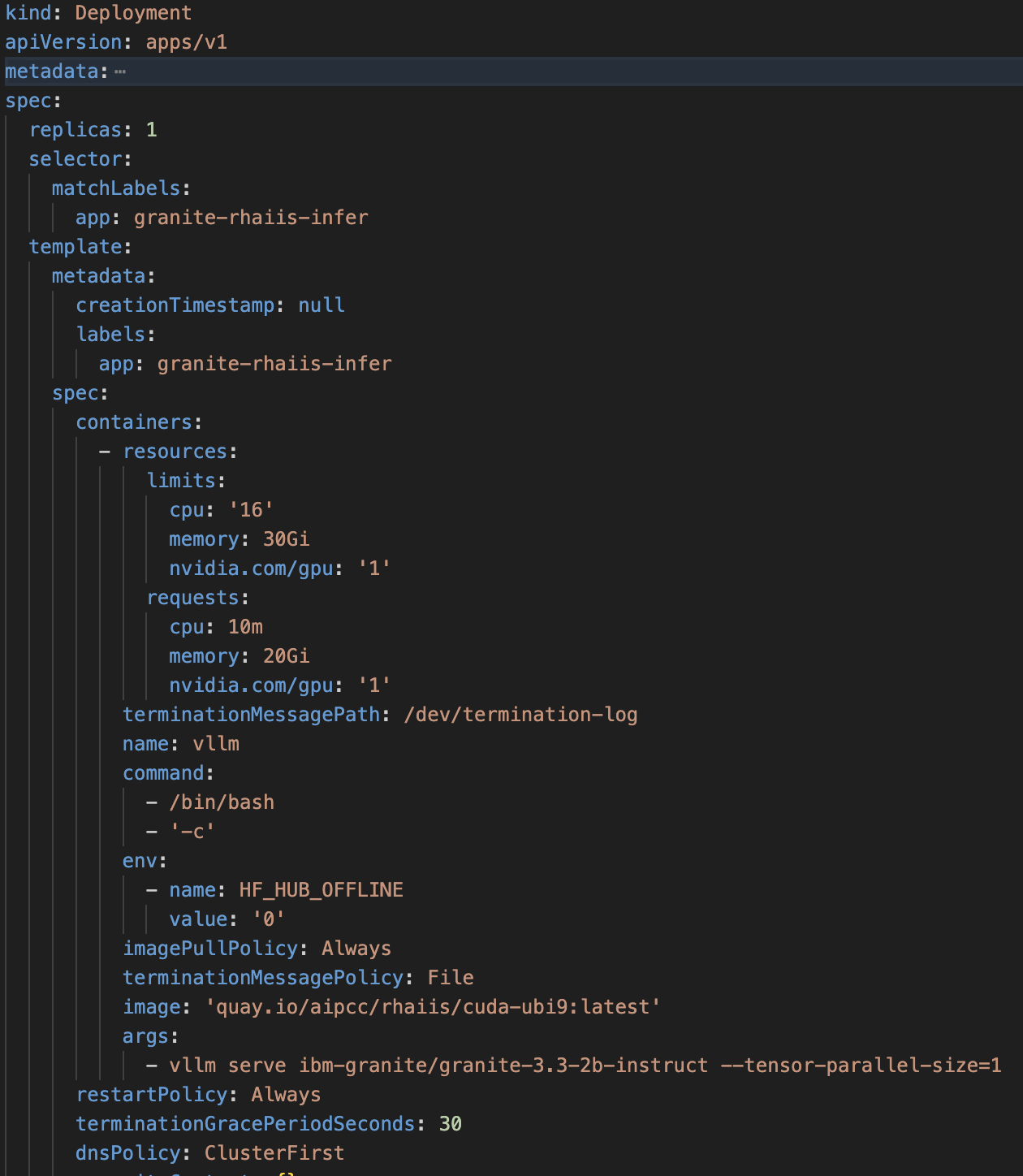
AI 推理服务器的 OpenShift 部署规范示例:
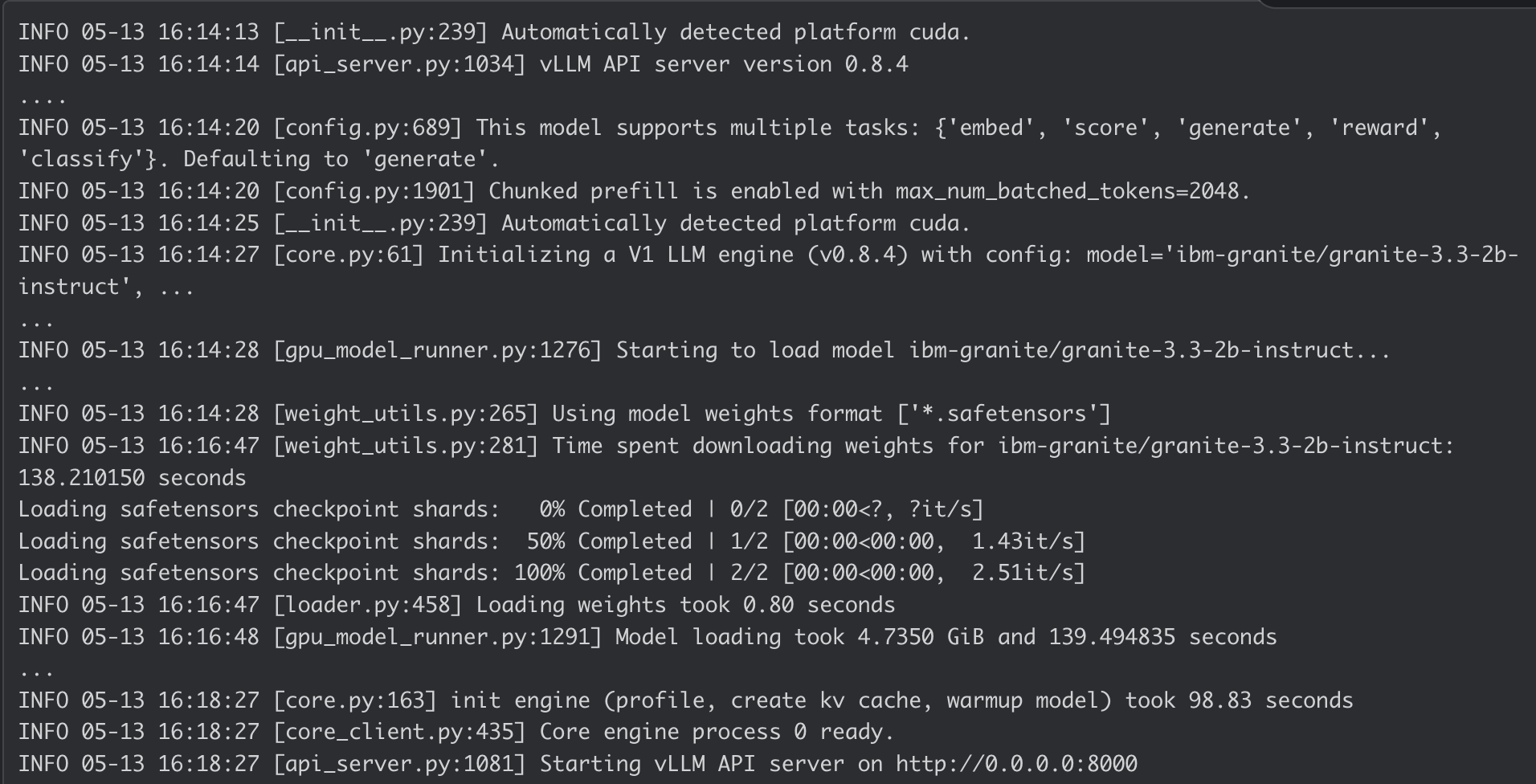
AI 推理服务器容器日志:
结论
红帽 AI 推理服务器集卓越性能与灵活部署于一体。其容器化特性带来了真正的混合云灵活性,无论数据和应用位于何处,您都可以一致地部署先进的 AI 推理,为企业 AI 工作负载提供强大的基础。
请浏览红帽 AI 推理服务器网页和我们的引导式演示以了解更多信息,或查看我们的技术文档以了解详细配置。
关于作者

Erwan Gallen is Senior Principal Product Manager, Generative AI, at Red Hat, where he follows Red Hat AI Inference Server product and manages hardware-accelerator enablement across OpenShift, RHEL AI, and OpenShift AI. His remit covers strategy, roadmap, and lifecycle management for GPUs, NPUs, and emerging silicon, ensuring customers can run state-of-the-art generative workloads seamlessly in hybrid clouds.
Before joining Red Hat, Erwan was CTO and Director of Engineering at a media firm, guiding distributed teams that built and operated 100 % open-source platforms serving more than 60 million monthly visitors. The experience sharpened his skills in hyperscale infrastructure, real-time content delivery, and data-driven decision-making.
Since moving to Red Hat he has launched foundational accelerator plugins, expanded the company’s AI partner ecosystem, and advised Fortune 500 global enterprises on production AI adoption. An active voice in the community, he speaks regularly at NVIDIA GTC, Red Hat Summit, OpenShift Commons, CERN, and the Open Infra Summit.

Carlos Condado is a Senior Product Marketing Manager for Red Hat AI. He helps organizations navigate the path from AI experimentation to enterprise-scale deployment by guiding the adoption of MLOps practices and integration of AI models into existing hybrid cloud infrastructures. As part of the Red Hat AI team, he works across engineering, product, and go-to-market functions to help shape strategy, messaging, and customer enablement around Red Hat’s open, flexible, and consistent AI portfolio.
With a diverse background spanning data analytics, integration, cybersecurity, and AI, Carlos brings a cross-functional perspective to emerging technologies. He is passionate about technological innovations and helping enterprises unlock the value of their data and gain a competitive advantage through scalable, production-ready AI solutions.







